


(已解决) 关于遍历复用中的两个小问题
遍历复用的用途是把同一批数据重复遍历多次的计算变成遍历一次,虽然计算总量没变,但遍历次数少了,简单理解成这样应该没错吧?那是不是总的耗时也会减少,少了重复遍历的时间?
举个简单的例子,文件是一个 2250 万行 3 列的 btx,要聚合一些列。
第一种方法是每一次聚合重新写一遍,如下截图所示:
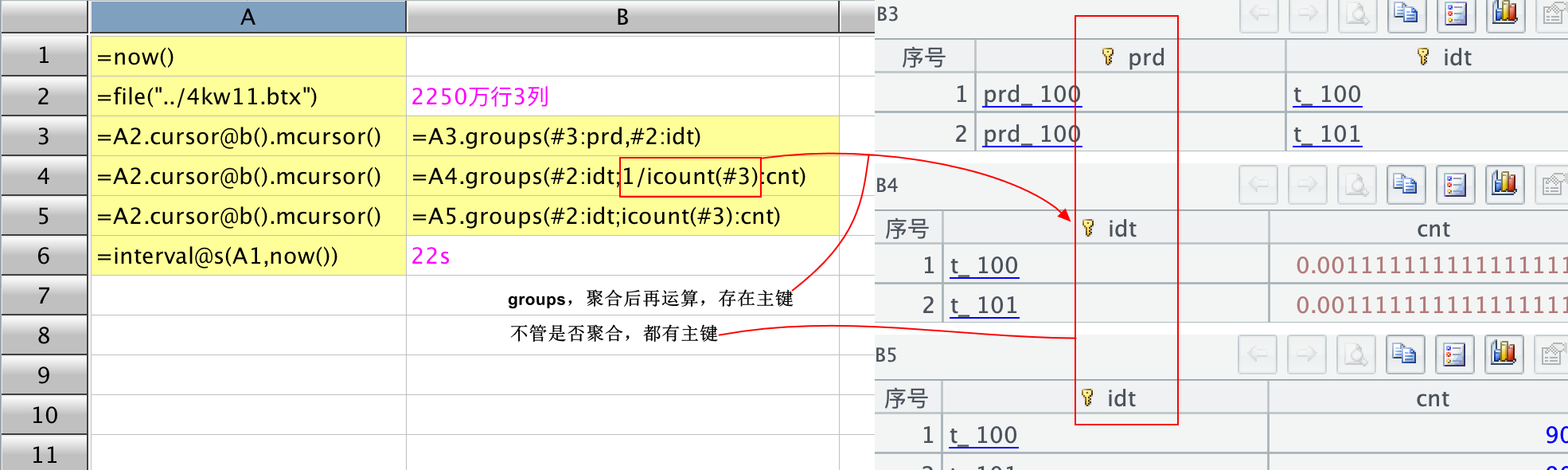
第二种方法是用 cursor…cursor 的方法,遍历复用,如下所示:
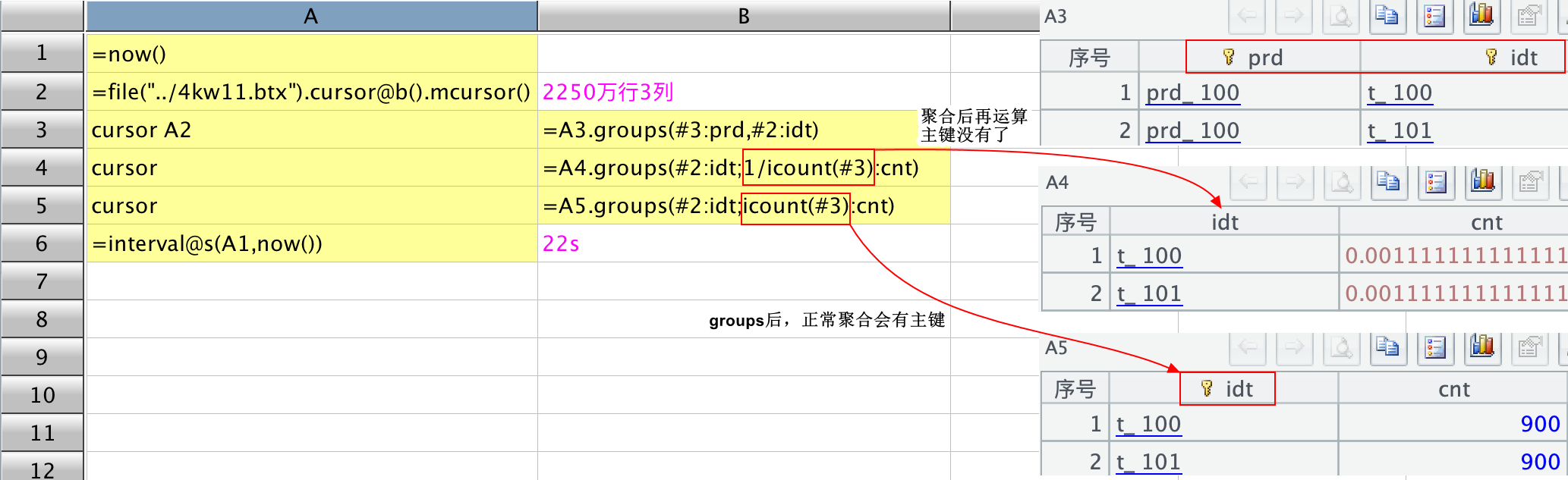
我原本以为第二种方法应该会快一些,但实际运行结果是两种写法的总耗时是一样的。然后,还有一个发现,在用管道时,不管是 cursor…cursor,还是 channel 方法,在 groups 时,聚合后再进行一次运算,主键就不存在了。可以从上述截图中观察,第一种方法,不管是否聚合,聚合后是否再运算,groups 之后都会自动生成主键,但在遍历复用时,聚合后再计算主键就丢失了,就像上图中的 B4 代码格,1/icount()或者 icount()+0,主键就没有了。所以,
1、遍历复用的时间是怎么算的?就像此例,常规写法和遍历复用耗时没区别,只是写法上更整齐优雅;
2、遍历复用时,聚合后再计算主键能不丢失吗?
3、groups 聚合时,可以用 icount 直接不重复计数,那可不可以直接去重后累加或者去重后 concat,比如聚合后 [1,2,1],去重后累加变成 sum([1,2]),concat@c([1,2]) 这种效果(有其它方法实现,先按两列聚合,再聚合一次,用两次 groups);比如以下例子:
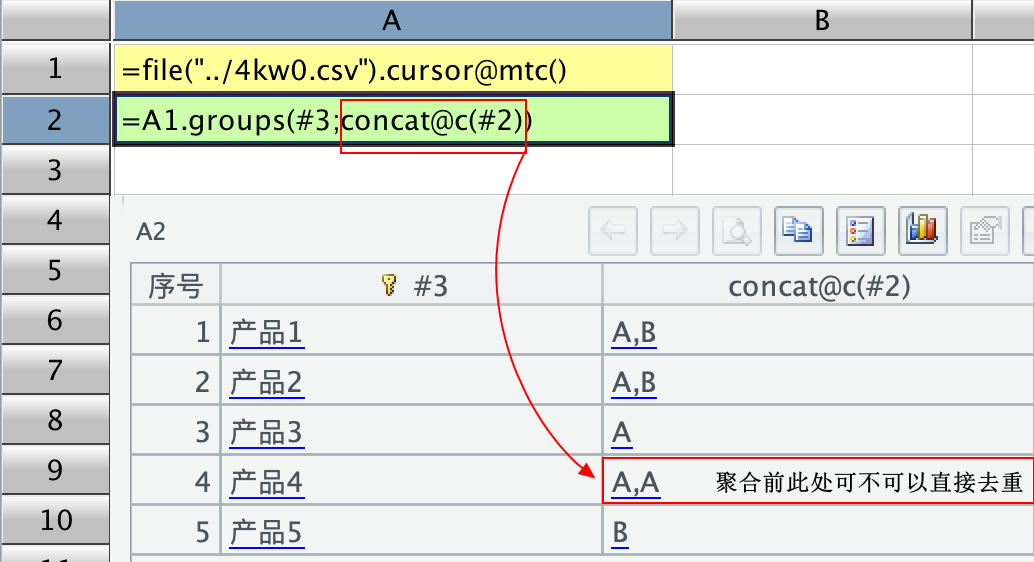
或者用 iterate 实现去重累积,但 iterate 在多路游标时不能用。
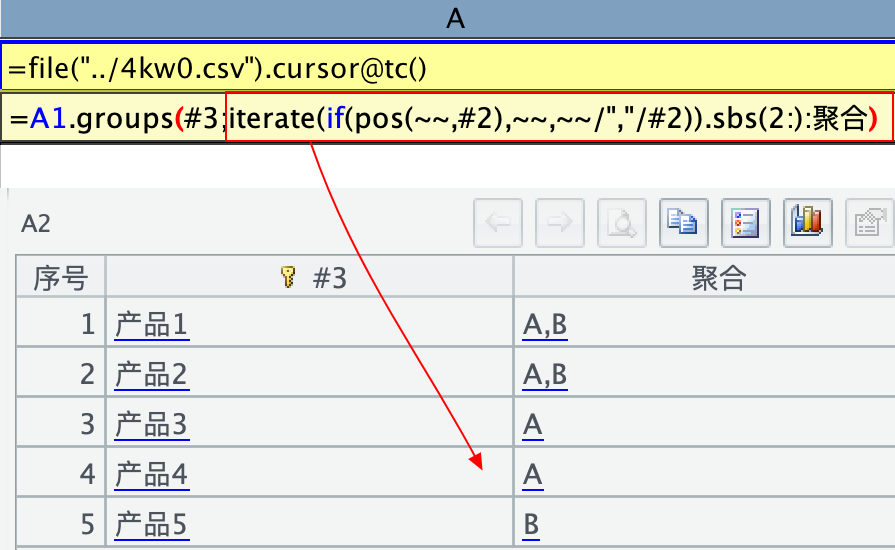
4、多路游标 groups 聚合时不能用 iterate。如下截图所示,用了 cursor@m(),如果不用 @m 是可以 iterate 的,函数文档里好像也没有说明:
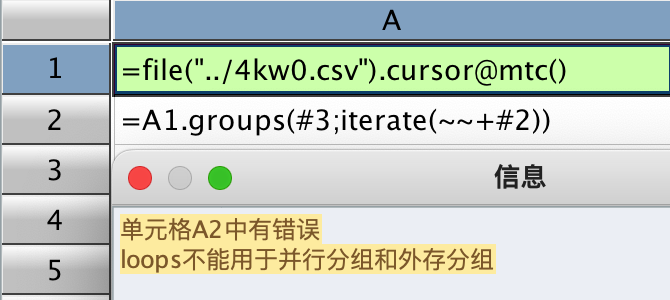
以上问题,可能是我写法不对或者理解有偏差,也有可能是举例不当,不过,还是恳请大佬们得闲时给予指导解惑,谢谢!


多路游标应该写成 file(…).cursor@mb(),file(…).cursor@b().mcursor() 并不会并行读数。
使用管道是为了读一次数据进行多个计算,节省的是读数的时间。
可以用 for file(…).cursor@mb(),10000 计算一下读数花了多少时间。
cs.groups(f;1/icount(..):cnt)会转成 cs.groups(f;icount(..):cnt).new(f,1/cnt:cnt) 来计算,new 计算没有继承主键。
多路游标不支持 iterate 聚合运算。
谢谢大佬指点🙏 ,但
1、cursor@b() 时,会忽略 @m 选项,这是官方函数文档里写的。截图如下:
所以文中案例如果写成 file(btx).cursor@mb()耗时会达到 59 秒,相比较于 file(btx).cursor@b().mcursor() 慢了将近一半时间。
我没有用 csv 特地用集文件写成 mcursor,目的也是想请大佬指导一下,如何能让两千万行的集文件读的更快。文本文件可以 @m 内置并行,但集文件似乎 @mb 行不通。再有一个,数据库游标时,db.cursor() 也是没有 @m 选项,取数很慢,游标有点拿捏不住,平时也练的少。
2、管道我再捋捋,似懂非懂。我理解的性能提升,就是直观的耗时少了😂 停留在比较肤浅的层次。
3、groups 转换成 new 之后没有继承主键,不对,这个没有继承主键只有在管道用法的时候没有继承主键,不用管道时,还是继承主键了,大佬可以细看一下文中的两个截图的右边,我特地用红框框出来了。是有主键好还是没有主键好,这个我也不懂,我只是觉得 groups 天然生成主键很方便,当然后续再去 keys() 也不是不可以。
4、多路游标不支持 iterate 这个懂了,希望有空时可以更新一下函数说明。没办法,小白只能对着函数文档练。出现不一致时,很大困惑。
5、文中第 3 点,groups 里可不可以直接去重,直接去重后再聚合,恳请大佬再䁖䁖,指点一二🙏 我记得以前 groups 只能聚合,聚合后再操作这个聚合值是会报错的,现在好像可以操作,是不是做过调整了?
刚试了一下,f.cursor@mb()是支持的,看一下 [工具]-[选项]-[环境] 里的最大并行数和多路游标缺省路数是不是 1,
如果是 1 则不会生成多路游标,这两个数通常设置成一样即可。
我测试了一下数据量为 500 万,字段数为 3,数据类型为整数的集文件 4 路并行读数时间为 50 毫秒,读数时间占比较少,所以使用管道效果不明显。
groups 不支持去重后累加,如果去重后的数据内存中能放的下可以写成 cs.groups(f1,v1).groups(f1;sum(v1)),
即把去重字段先放到分组字段里算出一个中间结果再进行一遍分组。
谢谢大佬回复🙏
1、 基础设置都设成 4 路了,CPU 只有 4 核,这个基础错误是不会犯的😄 ,既然您那边没有问题,估计是我哪里没弄对。而且官方函数文档说了 @b 时忽略 m,所以我以为用不得,我用的是海外版,这个我再看看怎么回事,我也不希望有啥不一样,总归是越快越好。能不能把您测试的集文件 4 路并行代码截个图,让我学习学习,有劳🙏
2、去重只是顺带提的一个想法,groups().groups(),两次 groups 也是我目前用的方法,还挺快的。我的想法是能用一句解决的不想用两句😄
3、cs.groups(字段;1/icount()) 这样还是是会继承主键的,只要不是管道都会继承主键,麻烦大佬再看看🙏
大佬请看以下截图:
我用 btx.cursor@mb(),然后用 fork 观察有没有多路,发现结果是这样的,是不是说明 @mb 中的 m 没起作用?
但是用了 btx.cursor@b().mcursor() 后用 fork 时,会有四个计算结果:
再用 csv 文件,csv.cursor@mtc(),用 fork 观察时,也有四个结果:
ch.groups(f;1/icount()) 没有设置主键这个问题改了,代码已提交到 git 上了。
了然…大佬的响应速度真快,跟 spl 是一样的高效👍 👍 👍
谢谢大佬的指点和帮助,周末愉快🙏
有空时,还请大佬过目以下截图,总觉得 file(btx).cursor@mb() 不能并行
我猜想可能是跟分组的结果集很大,并且数据分布有一定规律有关。
这几种写法都是并行计算分组的。
f.cursor@mb().groups() 是把文件分成 n 块,每块对应一个线程进行读数和分组计算,所有线程计算完后再把得到的结果汇总起来进行二次分组。
f.cursor@b().mcursor().groups() 则只有一个读数游标,进行分组计算的 n 个线程都跟这一个游标要数据,按理想状态来说线程 1 取 1 至 1000 条、2001 至 3000 条、…依次类推来进行分组计算,线程 2 取 1001 条至 2000 条、3001 至 4000 条、…依次类推来进行分组计算。
如果集文件中的数据不是随机分布的,而是存在某种规律,则这两种取数方案可能导致某一种的首次分组结果集远大于另一种取数方案的,这才导致性能相差巨大。
往集文件中多次追加相同的数据就有可能导致这种结果。
多谢大佬指导,我再消化消化您跟我说的知识点。
不占用您周末时间,好好休息🙏 🙏
Have a nice weekend! Peace!
大佬,周末好,哈哈…😄 ,照理不该在这个时候回信息打扰您,但我可能找到 file(btx).cursor@mb() 在我这边 @m 并行不起作用的原因了。
我复盘了一下整个操作流程,所有写法都是有依据的,不存在不正确使用,那问题只能出在 btx 集文件上。根据官方资料,集文件的生成可以有 3 种方式:
1、file(btx).export@b(cs or A), 这种是最常见常用的方法;
2、cs.select(条件;file(btx)),把不满足条件的记录写入集文件;
3、cs.groupn(条件;file(btx)),把分组子集分别写入集文件中。
而我恰巧是通过上述第 2 种方式生成的集文件,用这种 select 的方式生成的集文件可能存在问题。如下截图所示,kwdata.csv 模拟的是一个大概有 4500 万行 3 列的文本文件,文件中的日期只有 202311 月和 202312 月。我用 select 方法选出日期满足 202311 的,用 export@b 方法写入 11_data.btx 集文件中,而不满足 202311 的也就是 202312 的数据 select 写入 12_data.btx 集文件中。
然后两个集文件都用 cursor@mb(),再用 fork 观察是不是有多路游标生成,截图如下:
可以发现用 export@b 生成 11_data.btx 会有四个结果生成,而用 select 第 2 参数写出的 12_data.btx 只有一个结果,其它几路没起作用。
我反复试验了好几遍,各种调换顺序,也尝试了用 groupn 的方式写出集文件,结果都是一样的,如下,
所以斗胆猜测:
用 select、groupn 方法写出的集文件存在一点小问题,选项 @m 并行时不起作用,
目前只有通过 file(btx).export@b() 这种方式生成的集文件才可以并行 @mb。
恳请大佬得闲时亲测🙏
哦对是这个问题。
之前的集文件是可以选择是不是可分段并行的,可分段的集文件需要额外记一些段信息,默认生成的集文件是不可分段的。
后来 export 函数改成自动判断是不是生成可分段集文件了。
cs.select(x;file(…)) 这种写法没改,还是生成的不可分段集文件。不可分段集文件没法生成多路游标。
忘了集文件还有一种写出方式,T 函数:T(“文件名.btx”:cs/A),经测试,用 T 函数写出的集文件也可以并行。
Recap:
集文件能实现并行效果的写出方式:
1、file(“文件名.btx”).export@b(cs/A)
2、T(“文件名.btx”:cs/A)
尚不能实现并行效果的集文件写出方式:
3、cs.select(条件;file(“文件名.btx”))
4、cs.groupn(分组编号;[file(“文件 1.btx”),file(“文件 2.btx”)…]
集文件是 spl 特有的一种文件格式(这特么的纯属凑数废话),用户层面甚至不用费脑就可以实现快速输出,可见其使用的方便性,而并行是提高运算性能的重要手段,这一点对集文件也没有例外,所以,恳请大佬们斟酌,实现上述几种方式方法的殊途同归。
spl 的高效快捷和使用方便全仰仗于大佬们的专业和付出,先谢为敬(真心佩服)🙏
谢谢指出!
cs.select 和 cs.groupn 已经做了修改,提交到 github 上了。
谢谢大佬🙏 🙏
以下您说的,是让我去 github 上下载吗😄 github 我都没上去过,上不了😄
……
“ch.groups(f;1/icount()) 没有设置主键这个问题改了,代码已提交到 git 上了。”
“cs.select 和 cs.groupn 已经做了修改,提交到 github 上了。”
……
如果上不了 github 又着急使用可以找官方更新下载贴里的 jar 包。
大佬们,请问以下 jar 包有更新吗?
刚刚看到下载页面有更新 jar 包,下载下来试了一下,select 和 groupn 生成的集文件变成空的了,没有数据。
……
“ch.groups(f;1/icount()) 没有设置主键这个问题改了,代码已提交到 git 上了。”
“cs.select 和 cs.groupn 已经做了修改,提交到 github 上了。”
……
下载今天更新的那个 jar 包应该是可以的。
用 select 是怎么测试的?游标有把数据取出吗?
我就是按文中所说的方法生成测试的,
用 select 和 groupn 生成的集文件虽然有大小,但 fetch 出来是 null。
麻烦大佬有空亲测一下。
我使用今天上午的 esproc-bin.jar 测试 cs.select(x;f) 与 cs.groupn(x;F) 可以正常生成 btx 文件,fetch 结果也是正常的,测试用例如下:
我这弄不出来,大佬。我看你截图中 fetch 的是 A3,我这边 select 出的 A3 也是正常的,但 select 里边 2 参的文件,也就是 A2 就没有数据了。
同样 groupn,你 fetch 的是 A8,你试试 fetch 一下 A7 中的两个文件。
以上表述不是很严谨,确切应该是用 2 参输出的集文件在 file(btx).cursor@mb().fetch() 取不到数,@m 并行失效。
file(btx).cursor@b().fetch() 和 file(btx).import@b() 是有效的。
请大佬关注一下以下截图中 A6 和 A7:
A6 有 @m 选项,取不出数。
A7 可以取数。这两个的文件都是 select 的 2 参。
A8 可以取数且 @m 并行有效,这是直接 select 出来的。
您再下载更新下 esproc-bin.jar 试下
谢谢 ddszm 大佬,谢谢 leavedy 大佬🙏
刚测试完,本帖涉及的以下两个问题都解决了:
1、管道中的主键继承
2、用 select 和 groupn 方式写出集文件
以下小小建议,恳请大佬斟酌,函数参考文档对小白来说就是圣经:
1、希望能修改函数参考文档中关于 f.cursor@b 时的说明,集文件是可以并行的,也就是 @mb 是有效的。目前的文档中说 @b 时会忽略 @m;
2、希望能修改函数参考文档中关于 groupn 举例时的用法,groupn 之后取数时,不要用 fetch,用 skip 会比较好。
原因是,fetch 时要考虑内存是否能装得下,如果内存装不下,直接 fetch 会死机,小白用户会忽略这个预判,只会照着文档抄。
用 skip 会好一些。不知道这样说对不对?
有道理,我体会到了,感谢您的建议,我们来完善
感谢大佬关注🙏
“……我们来完善”,这话有力量、靠谱,听着让人振奋👍 👍 👍
May your business and personal endeavors reach new heights in 2024🙏