


程序设计习题 第 9 章 分类别
9.1 分组与汇总
1. 请统计字符串”esProc SPL is a smart desktop data analysis tool”中每个字母出现的次数(忽略大小写,a与A是同一个字母)
2.
(1)编程生成一张学生成绩表,效果如下图。学生id取值为1到50,其中1到25号Class为”one”,25号以后为”Two”。Subject为"English","Math","PE","Science"和"Arts",Score取100以内的随机数。
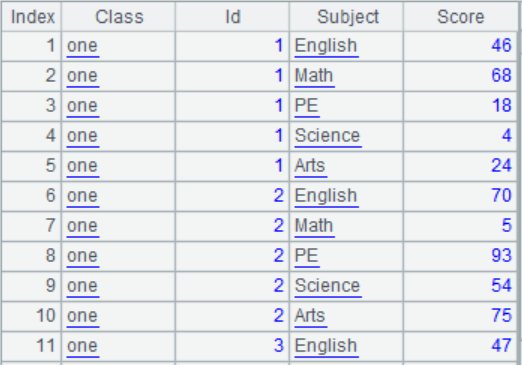
(2)计算每名学生的总分和平均分和分数最高的科目
(3)计算每个班级的各科平均分,最高分和最低分
(4)将每个班的各科成绩分别降序排列,并保存为多张Excel,命名格式Class_Subject
(5)统计每个班各科的得分中位数和不及格(低于 60 分)人数
(6)筛选出每个班各科成绩90分以上的人
3. 随机生成一系列邮箱地址,里面包含重复值,例如
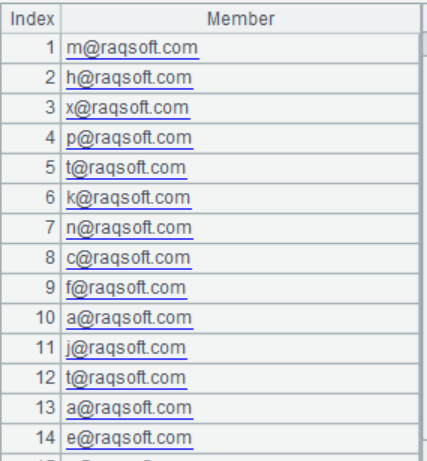
(1)去掉重复的邮箱地址
(2)找出重复的邮箱地址
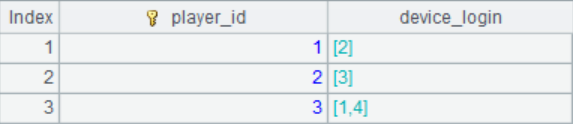
4. 某游戏平台一些玩家的行为活动表如下

每行数据记录了一名玩家在退出平台之前,当天使用同一台设备登录平台后打开的游戏的数目(可能是 0 个)。
(1)查询每位玩家第一次登录平台的日期。
结果示例:

(2)查询每位玩家都用了那些设备登陆
结果示例:
(3)计算在首次登录的第二天再次登录的玩家的比率
5. 有员工表
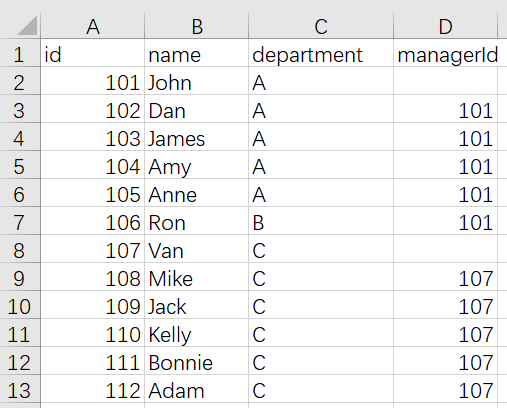
id 是此表的主键(具有唯一值的列)。
该表的每一行表示雇的名字、他们的部门和他们的经理的id。
如果managerId为空,则该员工没有经理。
没有员工会成为自己的管理者。
编写程序,找出至少有五个直接下属的经理名字
9.2 枚举与对齐
1. 有员工薪资表如下,统计A、B、C部门的平均工资
id |
name |
department |
salary |
101 |
John |
A |
7000 |
102 |
Dan |
B |
11000 |
103 |
James |
A |
9000 |
104 |
Amy |
B |
7000 |
105 |
Anne |
B |
16000 |
106 |
Ron |
A |
8000 |
107 |
Van |
C |
20000 |
108 |
Mike |
C |
7500 |
109 |
Jack |
D |
18000 |
110 |
Kelly |
D |
9500 |
111 |
Bonnie |
C |
12000 |
112 |
Adam |
C |
8500 |
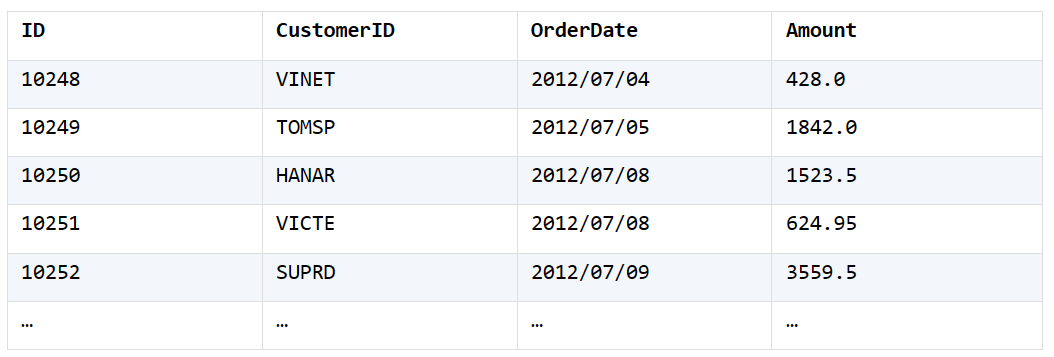
2. 根据订单表,顺序列出2013年每月的订单总数
3. 根据发帖记录表,按标签(Label)将帖子分组,并统计各个标签出现频数按照降序排列
ID |
Title |
Author |
Label |
1 |
Easy analysis of Excel |
John |
Excel,ETL,Import,Export |
2 |
Early commute: Easy to pivot excel |
Dan |
Excel,Pivot,Python |
3 |
Initial experience of SPL |
James |
Basics,Introduction |
4 |
Talking about set and reference |
Amy |
Set,Reference,Dispersed,SQL |
5 |
Early commute: Better weapon than Python |
John |
Python,Contrast,Install |
6 |
… |
… |
… |
结果示例:
Label |
Count |
SPL |
7 |
SQL |
6 |
Basics |
5 |
… |
… |
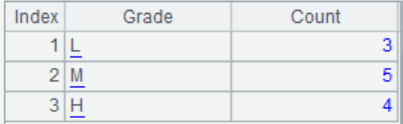
4. 根据员工薪资表,按工资 8000 以下、8000~12000 和 12000 以上分为[L,M,H]三组组,并统计各组的人数。(用枚举和序号分组两种方式分别实现)
id |
name |
department |
salary |
101 |
John |
A |
7000 |
102 |
Dan |
B |
11000 |
103 |
James |
A |
9000 |
104 |
Amy |
B |
7000 |
105 |
Anne |
B |
16000 |
106 |
Ron |
A |
8000 |
107 |
Van |
C |
20000 |
108 |
Mike |
C |
7500 |
109 |
Jack |
D |
18000 |
110 |
Kelly |
D |
9500 |
111 |
Bonnie |
C |
12000 |
112 |
Adam |
C |
8500 |
结果示例:
5. 根据员工薪资表,按年龄条件 [小于 35 岁, 小于 45 岁] 将员工分组(可重复分组),统计平均工资,不满足条件的分到新组。
id |
name |
birthday |
salary |
101 |
John |
1974/11/20 |
7000 |
102 |
Dan |
1980/7/19 |
11000 |
103 |
James |
1970/12/17 |
9000 |
104 |
Amy |
1985/3/7 |
7000 |
105 |
Anne |
1975/5/13 |
16000 |
106 |
Ron |
1988/3/7 |
8000 |
107 |
Van |
1994/11/20 |
20000 |
108 |
Mike |
1990/7/19 |
7500 |
109 |
Jack |
1970/12/17 |
18000 |
110 |
Kelly |
1985/3/7 |
9500 |
111 |
Bonnie |
1975/5/13 |
12000 |
112 |
Adam |
1995/5/13 |
8500 |
9.3 有序分组
1. 根据员工的入职时间平均分成三组(按余数的顺序分配到某一组),并统计每组的平均工资。部分数据如下:
ID |
NAME |
BIRTHDAY |
ENTRYDATE |
DEPT |
SALARY |
1 |
Rebecca |
1974/11/20 |
2005/3/11 |
R&D |
7000 |
2 |
Ashley |
1980/7/19 |
2008/3/16 |
Finance |
11000 |
3 |
Rachel |
1970/12/17 |
2010/12/1 |
Sales |
9000 |
4 |
Emily |
1985/3/7 |
2006/8/15 |
HR |
7000 |
5 |
Ashley |
1975/5/13 |
2004/7/30 |
R&D |
16000 |
… |
… |
… |
… |
… |
… |
2. 根据历届奥运会奖牌榜统计表,求总成绩蝉联第一名届数最长的国家及其奖牌信息。部分数据如下:
Game |
Nation |
Gold |
Silver |
Copper |
30 |
USA |
46 |
29 |
29 |
30 |
China |
38 |
27 |
23 |
30 |
UK |
29 |
17 |
19 |
30 |
Russia |
24 |
26 |
32 |
30 |
Korea |
13 |
8 |
7 |
… |
… |
… |
… |
… |
Game表示第几届奥运会
3. 上证指数 2020 年收盘价最长连续上涨了多少天?(首个交易日指数上涨)。部分数据如下:
DATE |
CLOSE |
OPEN |
VOLUME |
AMOUNT |
2020/1/2 |
3085.198 |
3066.3357 |
292470208 |
3.27E+11 |
2020/1/3 |
3083.786 |
3089.022 |
261496667 |
2.90E+11 |
2020/1/6 |
3083.408 |
3070.9088 |
312575842 |
3.31E+11 |
2020/1/7 |
3104.802 |
3085.4882 |
276583111 |
2.88E+11 |
2020/1/8 |
3066.893 |
3094.2389 |
297872553 |
3.07E+11 |
… |
… |
… |
… |
… |
9.4 扩展与转置
1. 根据学生成绩表,统计每个班的各科最高分,按列显示。部分数据如下:
CLASS |
STUDENTID |
SUBJECT |
SCORE |
1 |
1 |
English |
84 |
1 |
1 |
Math |
77 |
1 |
1 |
PE |
69 |
1 |
2 |
English |
81 |
1 |
2 |
Math |
80 |
… |
… |
… |
… |
预期结果:
CLASS |
MAX_MATH |
MAX_ENGLISH |
MAX_PE |
1 |
97 |
96 |
97 |
2 |
97 |
96 |
97 |
… |
… |
… |
… |
2. 根据奥运会奖牌总榜,生成每种奖牌的榜单。部分数据如下:
Game |
Nation |
Gold |
Silver |
Copper |
30 |
USA |
46 |
29 |
29 |
30 |
China |
38 |
27 |
23 |
30 |
UK |
29 |
17 |
19 |
30 |
Russia |
24 |
26 |
32 |
30 |
Korea |
13 |
8 |
7 |
… |
… |
… |
… |
… |
预期结果:
Game |
Nation |
Medal_type |
Medals |
30 |
USA |
Gold |
46 |
30 |
USA |
Silver |
29 |
30 |
USA |
Copper |
29 |
30 |
China |
Gold |
38 |
30 |
China |
Silver |
27 |
30 |
China |
Copper |
23 |
… |
… |
… |
… |
3. 有员工薪资表如下:
Name |
Dept |
Area |
Salary |
David |
Sales |
Beijing |
8000 |
Daniel |
R&D |
Beijing |
15000 |
Andrew |
Sales |
Shanghai |
9000 |
Robert |
Sales |
Beijing |
26000 |
Rudy |
R&D |
Shanghai |
23000 |
… |
… |
… |
… |
统计各部门在不同地区的平均工资,预期结果:
Dept |
Beijing |
Shanghai |
… |
R&D |
13000 |
11000 |
… |
Sales |
15000 |
14000 |
… |
4. 按渠道分类的销售表,按年月进行记录。部分数据如下:
YEAR |
MONTH |
ONLINE |
STORE |
2020 |
1 |
2440 |
3746.2 |
2020 |
2 |
1863.4 |
448 |
2020 |
3 |
1813 |
624.8 |
2020 |
4 |
670.8 |
2464.8 |
2020 |
5 |
3730 |
724.5 |
… |
… |
… |
… |
期望查询 2020 年每种渠道每个月的销售额,预期结果:
CATEGORY |
1 |
2 |
3 |
… |
ONLINE |
2440 |
1863.4 |
1813 |
… |
STORE |
3746.2 |
448 |
624.8 |
… |
参考答案
9.1 分组与汇总
1.
A |
|
1 |
esProc SPL is a smart desktop data analysis tool |
2 |
=lower(A1).split("").select(~!=" ") |
3 |
=A2.group(~:letter;~.len():letter_count) |
2.
A |
|
1 |
=["English","Math","PE","Science","Arts"] |
2 |
=A1.(50.new(if(~<=25,"one","Two"):Class, ~:Id, A1.~:Subject, rand(100):Score)).conj().sort(Id) |
3 |
=A2.groups(Id;sum(Score):Total,maxp(Score).Subject:Max_sub) |
4 |
=A2.groups(Class,Subject;avg(Score):Average,max(Score):Max,min(Score):Min) |
5 |
=A2.group(Class,Subject;~.sort@z(Score):Subscore) |
6 |
=A5.(file(~.Class/"_"/~.Subject/".xlsx").xlsexport@t(~.Subscore)) |
7 |
=A2.groups(Class,Subject;median(,Score):Median_socre,count(Score<60):Failed_count) |
8 |
=A2.group(Class,Subject;~.select(Score>=90):Above_90) |
3.
A |
|
1 |
=30.(char(97+rand(26))/"@raqsoft.com") |
2 |
=A1.id() |
3 |
=A1.group().select(~.len()>1).(~(1)) |
4.
A |
|
1 |
=T("player_event.xlsx") |
2 |
=A1.groups(player_id;min(event_date):first_login) |
3 |
=A1.group(player_id;~.(device_id).id():device) |
4 |
=A1.group(player_id;~.(event_date).contain(min(event_date)+1):continu_login) |
5 |
=A4.count(continu_login)/A4.len() |
5.
A |
|
1 |
=T("employee.xlsx") |
2 |
=A1.group(managerId).select(~.len()>=5).(~.managerId) |
3 |
=A2.(A1.select(A2.~==id).name) |
9.2 枚举与对齐
1.
A |
|
1 |
=T("salary.xlsx") |
2 |
[A,B,C] |
3 |
=A1.align@a(A2,department) |
4 |
=A3.new(A2(#):department,~.avg(salary):avg_salary) |
2.
1 |
=T("orders.xlsx") |
2 |
=A1.select(year(Orderdate)==2013) |
3 |
=A2.groups@n(month(Orderdate):Month;count(id):OrderCount) |
3.
A |
|
1 |
=T("post_record.xlsx") |
2 |
=A1.conj(Label.split(",")).id() |
3 |
=A1.align@ar(A2.len(),A2.pos(Label.split(","))) |
4 |
=A3.new(A2(#):Label,~.count():Count).sort@z(Count) |
4.
A |
|
1 |
=T("salary.xlsx") |
2 |
[?<8000,?>=8000 && ?<12000,?>=12000] |
3 |
[L,M,H] |
4 |
=A1.enum(A2,salary) |
5 |
=A4.new(A3(#):Grade,count(~):Count) |
A |
|
1 |
=T("salary.xlsx") |
2 |
[8000,12000] |
3 |
[L,M,H] |
4 |
=A1.group@n(A2.pseg(salary)+1) |
5 |
=A4.new(A3(#):Grade,count(~):Count) |
5.
A |
|
1 |
=T("salary.xlsx") |
2 |
[?<35,?<45] |
3 |
[below 35,below 45] |
4 |
=A1.enum@nr(A2,age(birthday)) |
5 |
=A4.new(if (#>A2.len(), "Other",A3(#)):AGE,~.avg(salary):AvgSalary) |
9.3 有序分组
1.
A |
|
1 |
=T("Employee.csv").sort(ENTRYDATE) |
2 |
=A1.group@n((#-1)*3\A1.len()+ 1) |
3 |
=A2.new(#:GROUP_NO, ~.avg(SALARY):AVG_SALARY) |
2.
A |
|
1 |
=T("Olympic.txt") |
2 |
=A1.sort@z(Game,Gold,Silver,Copper) |
3 |
=A2.group@o1(Game) |
4 |
=A3.group@o(Nation) |
5 |
=A4.maxp@a(~.len()) |
3.
A |
|
1 |
=T("SSEC.csv") |
2 |
=A1.select(year(DATE)==2020).sort(DATE) |
3 |
=A2.group@i(CLOSE<CLOSE[-1]) |
4 |
=A3.max(~.len()) |
9.4 扩展与装置
1.
A |
|
1 |
=T("Scores.csv") |
2 |
=A1.groups(CLASS,SUBJECT; max(SCORE):MAX_SCORE) |
3 |
=A2.pivot(CLASS; SUBJECT, MAX_SCORE; "Math":"MAX_MATH", "English":"MAX_ENGLISH", "PE":"MAX_PE") |
2.
A |
|
1 |
=T("Olympic.txt") |
2 |
=A1.pivot@r(Game,Nation;Medal_type,Medals;Gold, Silver, Copper) |
3.
A |
|
1 |
=T("salary.txt") |
2 |
=A1.pivot@s(Dept; Area, avg(Salary)) |
4.
A |
|
1 |
=T("MonthSales.csv").select(YEAR==2020) |
2 |
=A1.pivot@r(YEAR,MONTH; CATEGORY, AMOUNT) |
3 |
=A2.pivot(CATEGORY; MONTH, AMOUNT) |
按照逻辑顺序,先使用函数 A.pivot@r()列转行,再使用函数 A.pivot() 行转列即可。


英文版