


程序设计习题 第 8 章 表一表
8.2 序表与排列
1. 有字段名:["user_id","age","due_amt","due_date","user_score"]
数据:[[748147, 21, 258.7045, 2018/5/25, 0.7],[672952, 37, 307.927, 2018/7/9,0],[404196, 24, 252.9809, 2018/3/18, 0.542857],[342769, 23, 107.6503, 2018/2/13, 0.073529],[828139, 23, 201.0499, 2018/7/1, 0.666667]]
(1)用给出的字段名和数据生成一个序表,数据的每一个子序列为一条记录
(2)在序表的第1条记录前插入一行数据795130,31, 3730.995, 2018/11/25, 0.142857
(3)求序表的长度
(4)取序表第1条记录
(5)取序表的倒数第3条记录
(6)比较(4)(5)的user_score值,输出分数高的user_id
(7)取序表的第3到5行
(8)取序表的第1、3、5行
(9)将(8)中的第2行user_score改为0.85,并观察原表和(7)中同一记录的变化
(10)将排列(7)和(8)求并集,并计算合并后的长度
(11)创建一个新的序表,字段名为Id,Age,Amt
(12)将(10)中记录按照对应的字段插入到(11)
(13)将(1)的原始序表保存为”user_1.xlsx”,(10)的序表保存为”user_2.xlsx”
2. 将第1题中生成的”user_1.xlsx”和”user_2.xlsx”合并成一个文件命名为”user.xlsx”
3. 将文件”user.xlsx”按照行数拆分,每3行拆分为一个小文件,命名为user1、user2……
8.3 序表生成
1. 以"user_id","age","due_amt","due_date","user_score"为字段名
序列[[748147, 21, 258.7045, 2018/5/25, 0.7],[672952, 37, 307.927, 2018/7/9,0],[404196, 24, 252.9809, 2018/3/18, 0.542857],[342769, 23, 107.6503, 2018/2/13, 0.073529],[828139, 23, 201.0499, 2018/7/1, 0.666667]]的每一个子成员为一条记录,生成序表如下图。
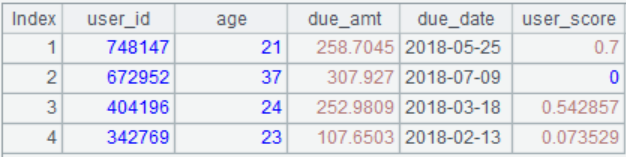
2. 向第1题的序表中插入100条数据,其中”user_id”和”age”取随机整数,”due_amt”和”user_score”取随机浮点数,”due_date”取2018年的任意一天,并将表格保存为”user_104.xlsx”
3. 用字段”amt_flag”标出第2题序表中”due_amt”大于500的用户,大于500标为1反之为0(用A.new()和A.derive()分别实现)
4. 把8.2习题中的”user_1.xlsx”和”user_2.xlsx”合并,并追加列”File”,显示数据来源
8.4 循环函数
1.
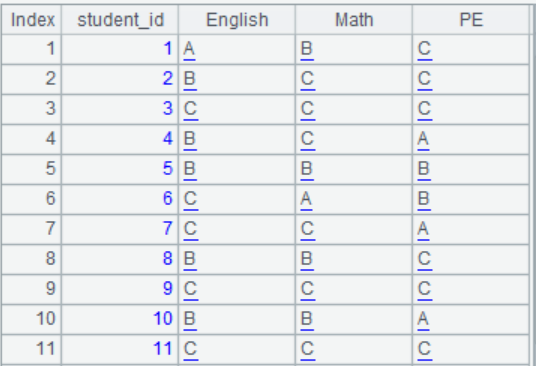
(1)用程序生成一张学生成绩表,效果如下图。学生id取值为1到50,成绩取100以内的随机数。
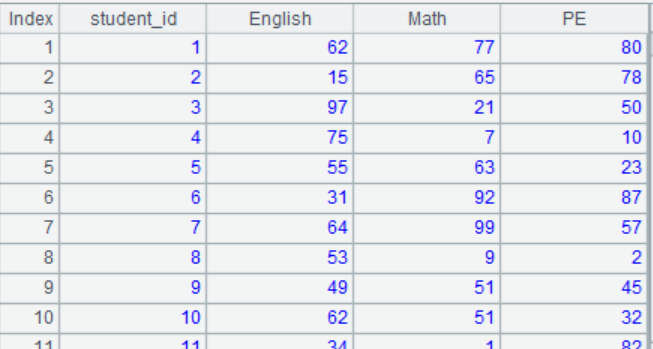
(2)计算数学最高分,英语平均分和总分最低分
(3)找出数学最高的学生和总分最低的学生
(4)分别筛选出英语在80分以上的人和数学80分以上的人
(5)筛选出英语或数学在80分以上的人
(6)筛选出英语80分以上但数学没达到80分的人
(7)计算英语和数学都在80分以上的人的总分最高分
(8)在成绩单上添加字段”total”计算总分,并按照总分排序,从高到低
(9)将成绩单按照英语从高到低,体育从低到高排序
(10)计算前5名总分和总分前5名的人
(11)把”student_id”修改为字符串格式
(12)添加字段”total_rank”表示每名学生的排名,并将total_rank<=25的人评价为A,其余为B,用字段flag表示
(13)计算这批学生中A级和B级学生数学分数差最大值
(14)计算A级和B级学生数学分数差最大的学生对
2. Excel里某产品2021年1月份的日销售数据
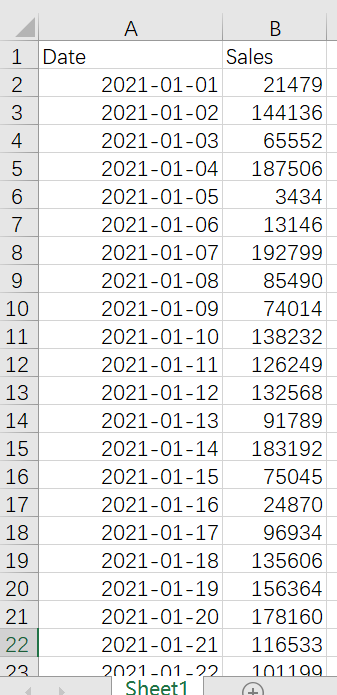
(1)筛选出偶数日的销售额数据
(2)筛选出周六日的销售额数据
(3)计算每日的销售额涨幅和累计销售额
(4)计算该产品销售额最长连续上涨了多少日
(5)计算销售额最高那天的涨幅
(6)计算销售额超过15万的日期和涨幅
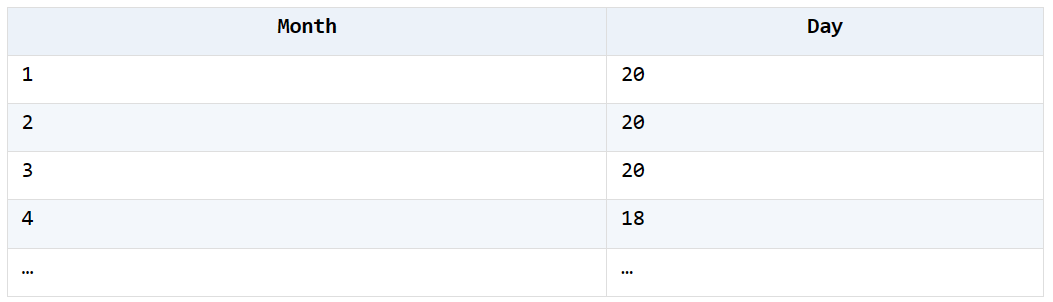
3. 有订单销售表Orders.xlsx如下图,统计出 2014 年每个月达到 20 笔订单所需天数
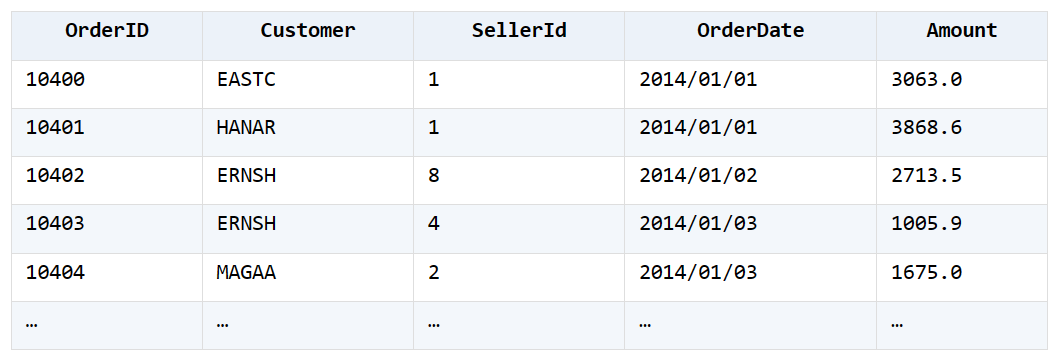
统计效果如图
8.5 字段上的计算
1.
(1)用程序生成一张学生成绩表,效果如下图。学生id取值为1到50,成绩取100以内的随机数。(用宏实现)
(2)在所有列前面插入一列class,表示学生所在班级,1-25号学生为one,26-50号为two
(3)添加字段total,计算每名学生的总成绩
2. 将第1题中的学生成绩表英语成绩修改为60-100之间的随机数
3. 将学生成绩表中的各科成绩分箱处理,改用A、B、C表示,90分以上为A,60-89为B,60分以下为C。修改效果如图
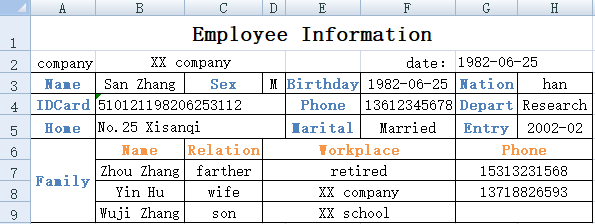
4. 在员工信息登记表文件staff.xlsx中,每个sheet有员工信息及他的家庭成员信息,请将员工信息及家庭成员信息分别解析成两个结构化数据表。其中一个sheet如下图:
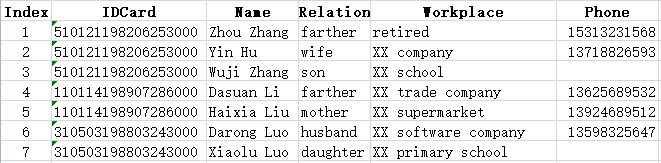
解析效果
员工信息表:

家庭成员信息表:
参考答案
8.2 序表与排列
1.
A |
B |
C |
|
1 |
["user_id","age","due_amt","due_date","user_score"] |
[[748147, 21, 258.7045, 2018/5/25, 0.7],[672952, 37, 307.927, 2018/7/9,0],[404196, 24, 252.9809, 2018/3/18, 0.542857],[342769, 23, 107.6503, 2018/2/13, 0.073529],[828139, 23, 201.0499, 2018/7/1, 0.666667]] |
=([A1]|B1).record() |
2 |
=C1.insert(1,795130,31, 3730.995, string(“2018/11/25”), 0.142857) |
||
3 |
=C1.len() |
||
4 |
=C1(1) |
||
5 |
=C1.m(-3) |
||
6 |
>output("user"/if(A4.user_score>A5.user_score,A4.user_id,A5.user_id)/"is better") |
||
7 |
=C1.to(3,5) |
||
8 |
=C1.m([1,3,5]) |
||
9 |
>A8(2).user_score=0.85 |
||
10 |
=A7&A8 |
=A10.len() |
|
11 |
=create(Id,Age,Amt) |
||
12 |
=A11.insert(0:A10,user_id:Id,age:Age,due_amt:Amt) |
||
13 |
=file("user_1.xlsx").xlsexport@t(C1) |
=file("user_2.xlsx").xlsexport@t(A10) |
2.
A |
|
1 |
=directory@p("data/*.xlsx").(file(~).xlsimport@t()).conj() |
2 |
>file("user.xlsx").xlsexport@t(A1) |
3.
A |
|
1 |
=file("user.xlsx").xlsimport@t() |
2 |
=A1.len().step(3,1) |
3 |
=A2.(file("data/user"/#/".xlsx").xlsexport@t(A1.to(~,~+2))) |
8.3 序表生成
1-3
4.
A |
|
1 |
[[748147, 21, 258.7045, 2018/5/25, 0.7],[672952, 37, 307.927, 2018/7/9,0],[404196, 24, 252.9809, 2018/3/18, 0.542857],[342769, 23, 107.6503, 2018/2/13, 0.073529]] |
2 |
=A1.new(A1(#)(1):user_id,A1(#)(2):age,A1(#)(3):due_amt,date(A1(#)(4),"yyyy/MM/dd"):due_date,A1(#)(5):user_score) |
3 |
=A2.insert(0:100,int(rand()*1000000):user_id,rand(42)+18:age,rand()*1000:due_amt,date("2018-01-01")+rand(365):due_date,rand():user_score) |
4 |
>file("C:/Users/29636/Desktop/tmp/user_104.xlsx").xlsexport@t(A3) |
5 |
=A2.new(user_id,if(due_amt>500,1,0):amt_flag) |
6 |
=A2.derive(if(due_amt>500,1,0):amt_flag) |
A |
|
1 |
=directory@p("data/*.xlsx") |
2 |
=A1.(file(~).xlsimport@t().derive(filename@n(A1.~):File)).conj() |
3 |
>file("user.xlsx").xlsexport@t(A2) |
8.4 循环函数
1.
A |
B |
C |
|
1 |
=50.new(~:student_id,rand(100):English,rand(100):Math,rand(100):PE) |
||
2 |
=A1.max(Math) |
=A1.avg(English) |
=A1.min(English+Math+PE) |
3 |
=A1.maxp@a(Math) |
=A1.minp@a(English+Math+PE) |
|
4 |
=A1.select(English>=80) |
=A1.select(Math>=80) |
|
5 |
=A4&B4 |
||
6 |
=A4\B4 |
||
7 |
=(A4^B4).max(English+Math+PE) |
||
8 |
=A1.derive(English+Math+PE:total) |
=A8.sort@z(total) |
|
9 |
=A8.sort(-English,PE) |
||
10 |
=A8.top(-5,total) |
=A8.top(-5;total) |
|
11 |
>A8.run(student_id=string(student_id)) |
||
12 |
=A8.ranks@z(total) |
=A8.derive(A12(#):total_rank,:flag) |
>B12.run(flag=if(total_rank<=25,"A","B")) |
13 |
=B12.select(flag=="A") |
=B12.select(flag=="B") |
=A13.max(B13.max(abs(A13.Math-Math))) |
14 |
=A13.conj(B13.([A13.~,~])) |
=A14.maxp@a(abs(~(1).Math-~(2).Math)) |
2.
A |
B |
|
1 |
=T("C:/Users/29636/Desktop/tmp/dailysales.xlsx") |
|
2 |
=A1.select(#%2==0) |
|
3 |
=A1.select(day@w(Date)==7 || day@w(Date)==1) |
|
4 |
=A1.derive(Sales-Sales[-1]:Gain,Sales+CumSales[-1]:CumSales) |
|
5 |
=(a=0,A4.(if(Gain>0,a+=1,a=0))).max() |
|
6 |
=A4.maxp(Sales).Gain |
|
7 |
=A4.pselect@a(Sales>150000) |
=A4.calc(A7,Gain) |
8 |
=A7.new(A4(~).Date,B7(#):Gain) |
3.
A |
|
1 |
=T ("Orders.xlsx") |
2 |
=A1.select(year(OrderDate)==2014) |
3 |
=A2.sort(OrderDate) |
4 |
=A3.select(seq(month(OrderDate))==20) |
5 |
=A4.new(month(OrderDate):month,day(OrderDate):day) |
A2 选出 2014 年数据
A3 按照订单日期排序
A4 使用函数 seq() 计算每个月份的订单序号,并选出每个月序号为 20 的记录
A5 根据每个月序号为 20 的订单日期,算出其月份和日子,即为所求结果
8.5 字段上的计算
1.
2.
A |
|
1 |
[English,Math,PE] |
2 |
=A1.("rand(100):"/~).concat@c() |
3 |
=50.new(~:student_id,${A2}) |
4 |
=A3.fname().concat@c() |
5 |
=A3.new(if(student_id<=25,"one","two"):class,${A4}) |
6 |
=A5.derive(~.array().to(3,).sum():total) |
A |
|
1 |
[English,Math,PE] |
2 |
=A1.("rand(100):"/~).concat@c() |
3 |
=50.new(~:student_id,${A2}) |
4 |
=A3.field("English",50.(60+rand(40))) |
3.
A |
B |
C |
|
1 |
[English,Math,PE] |
||
2 |
=A1.("rand(100):"/~).concat@c() |
||
3 |
=50.new(~:student_id,${A2}) |
||
4 |
for A1 |
=A3.field(A4) |
=B4.(if(~>=90:"A",~<60:"C";"B")) |
5 |
>A3.field(A4,C4) |
4.
A |
B |
C |
|
1 |
=create(IDCard,Name,Sex,Birthday,Nation,Phone,Depart,Home,Marital,Entry) |
||
2 |
=create(IDCard,Name,Relation,Workplace,Phone) |
||
3 |
[B4,B3,D3,F3,H3,F4,H4,B5,F5,H5] |
||
4 |
=file("staff.xlsx").xlsopen() |
||
5 |
for A4 |
=A3.(eval($[A4.xlscell(]/~/",\""/A5.stname/"\")")) |
>A1.record(B5) |
6 |
=A4.xlsimport@t(Family,Name,Relation,Workplace,Phone;A5.stname,6) |
||
7 |
=B6.rename(Family:IDCard) |
>B7.run(IDCard=B5(1)) |
|
8 |
>A2.insert@r(0:B7) |
A1 创建列名分别为IDCard、Name、Sex、Birthday、Nation、Phone、Depart、Home、Marital、Entry的空序表,用于保存主表员工信息
A2 创建列名分别为IDCard、Name、Relation、Workplace、Phone的空序表,用于保存子表员工家庭成员信息
A3 定义主表员工信息所在单元格序列
A4 打开Excel数据文件
A5 循环读取Excel文件各sheet数据
B5 读取员工信息序列
C5 将B5读取的员工信息保存到序表A1
B6 从第6行开始读取员工家庭成员信息,只读指定的5列Family、Name、Relation、Workplace、Phone
B7 将B6序表的Family列改名为IDCard
C7 为B7序表的IDCard列赋值为员工信息中的IDCard
B8 将B7中的员工家庭成员信息追加到序表A2


英文版