


(已解决) icursor 与 cursor 获取到不同结果
因为集算器版本更新 (2023 年 12 月 08 日),icursor 好像有变化,旧版 Mac 中的 icursor 跑不出结果,但新版的 mac 和 win 中的 icursor 和 cursor 方法在本例中获取到的结果依然有不一样。
stdate.ctx 是一个 1 列 104 万行的文件,stdate.idx 是用 index@w 创建的全文检索索引文件,想查找统计出包含 "2021" 字样的记录数,用的是两端模糊查找 "*2021*",数字关键字超过两个。Mac 版用的是 20231020 这个 IDE 版本,其中的 jar 包没有更新到最近日期,Win 版用的是海外版 20231020,其中的 jar 包更新到了最近日期 20231205。其中的 icursor 方法在不同版本中得到了不一样的结果,但 select 方法得到的结果都是一致的。此例中,包含 2021 字样的正确结果是 909458 条,Win 版 icursor 获取的数量少了,请看以下截图:
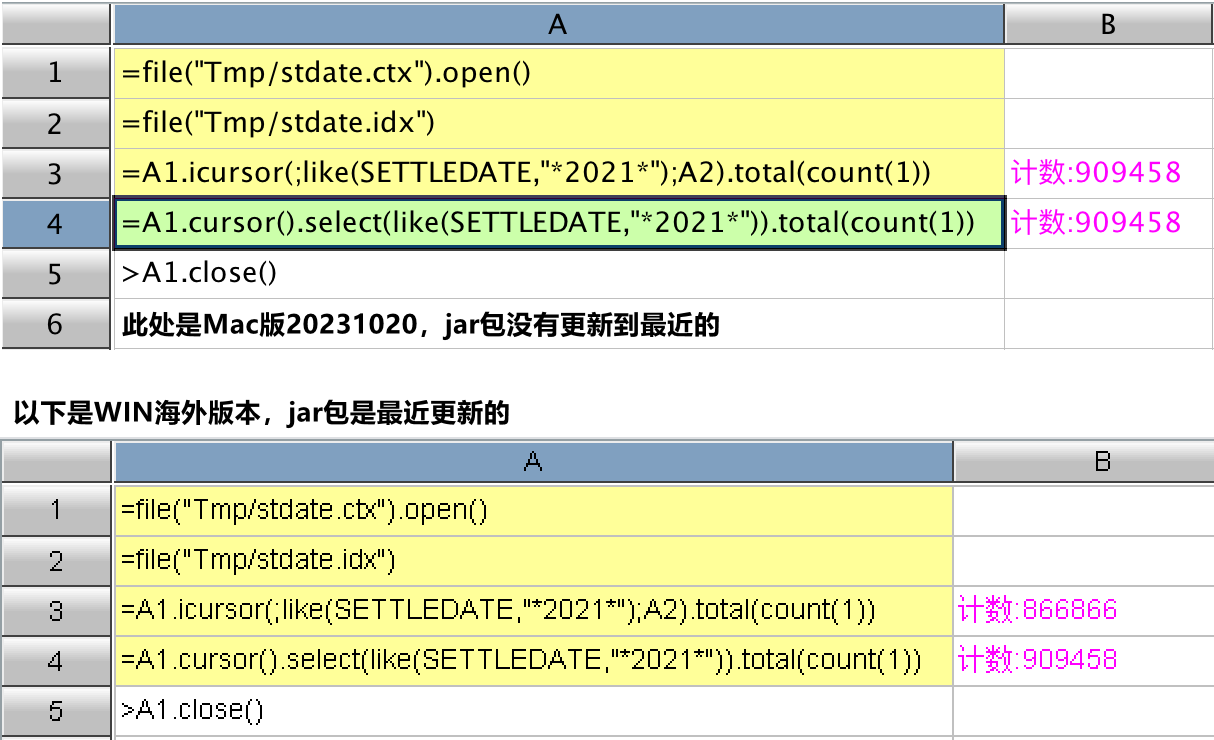
数据是这个样式的:
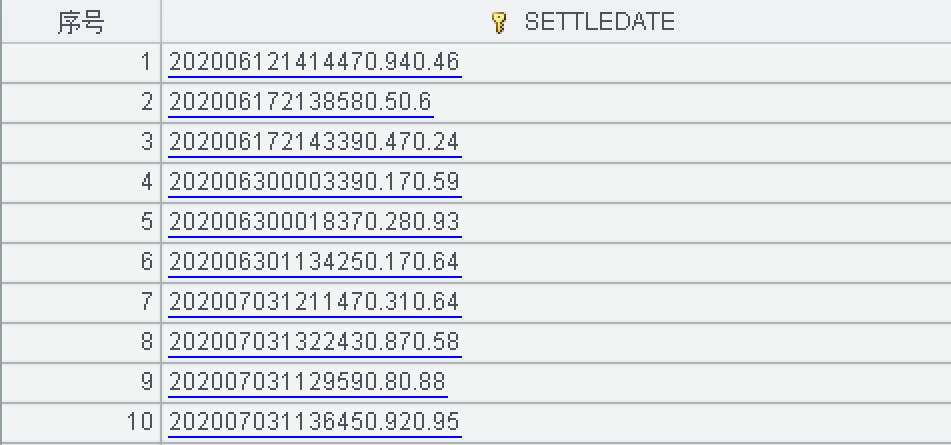
不知道哪里的用法欠妥,恳请大佬们帮忙!谢谢!


组表和索引文件都是同一个吧?
试了一下类似的数据,没发现这个现象。你的数据总量是多少?数据是如何造出来的?
数据只有 1 列,104 万行,来源于 excel 文件。文件已经其他途径转给您了。
ctx 文件是通过 excel 文件中的 1043840 行创建的:
以下是创建索引和查询计数语句,A3 结果 (计数 487) 和 A4、A5 结果 (计数 504) 不一样:
我分别试了 50 万行,80 万行,100 万行,查询 "*2023*",icursor 和 cursor.select 结果是一致的,
但超过 100 万行时,此例中,两种方法的结果就会有出入。Mac 版两者结果一致 (今天上午能用 icursor,下午一直不能用 icursor),Win 版两者结果不一致。
试了一下发过来的数据,结果没问题。
=file(“stdate.ctx”).open()
=A1.import()
/=A1.index@w(file(“idx_date”);SETTLEDATE)
=file(“idx_date”)
=A1.icursor(;like(SETTLEDATE,“2001”);A5).total(count(1))
=A1.cursor().select(like(SETTLEDATE,“2001”)).total(count(1))
总数据量是多大?
总数据量就是文件中的 1043839 行。
那真的很奇怪了,我这边 WIN 海外版怎么弄都是不一样的结果。
MAC 版里的 icursor 从下午到现在一直出不了结果,上午还能用。
电脑重启,日志文件都删除了,内存清理了,也没有用。
你正好试了一个没有出现问题的 "*2001*“。
但”*2021*“和”*2023*" 这两个 (不只这两个) 查询结果会有出入,
这两个例子在正文和回复中都有提及,都被你巧妙地避开了。
为了谨慎稳妥起见,我把此例的整个过程,从创建 ctx 文件到创建索引再到查询,复盘一下,恳请大佬指导:
1、从 excel 中的数据区域 A1:A1043840 创建 ctx 文件。首先,保证这部分数据是没有重复值的且升序排序,请看以下截图:
2、用 spl 插件在 excel 文档里写语句创建 ctx 文件,spl 语句如下截图所示:
创建完成后,在 excel 里用 T 函数读出 ctx 文件,相互核对印证创建成功:
3、在 win 版本的集算器里创建索引,用 index@w 创建全文检索索引文件,如下图所示:
4、分别用 icursor、cursor、select3 种方法对 "*2021*" 做查询统计计数,发现结果有出入,icursor 获取的结果少了,如下图所示:
5、以下截图中列出的是用上述 3 种方法统计结果有出入的例子:
6、以下截图中列出的是统计结果一致的例子:
我试了好几遍,上述过程和方法应该是没有问题的,恳请大佬们得闲时指导解惑,谢谢!
好的,我再试试
刚刚做了修改。用最新的代码试试
大佬,最新的代码在哪里😄 我去哪里试啊😄 这个回复不是跟我说的吧😄
在集算器 (SPL) 最新版发布啦『发布日期 20231208』 - 乾学院 (raqsoft.com.cn)
请问是哪一个?链接里没有更新的包,我没安装企业版的。
大佬们,请问这个问题有最新的 update 吗?
到下载贴,下载昨天的 esproc-bin*.jar 就可以
更新了 jar 包,还是跟之前一样的,icursor 和 cursor 得到的结果不一样。
大佬能帮忙再看一下吗?
忘了说下了。索引要重新建立。
这个不必纠结。
全文索引通常是在搜索中使用,找出前 N 个就够了。如果要找出所有,索引有可能会非常巨大,也没什么实用性了。
这个程序早期没考虑到这一点,索引做成找出所有,在一次实践过程中发现索引大到根本不可行,就改成有个上限。恰好就在这两个版本之间,就出现了不一致。
后来改成由用户设置上限的方式了。
感谢老贼指点解惑🙏 感谢 liwei 大佬🙏
昨天还重建索引试了没有变化,现在更新重建可以了,就本例而言,没有发现什么问题。我这样的小白就是纠结于结果对还是不对,执行效率快还是不快😄 肤浅的很,见谅。
建索引让我想起了钓鱼,钓鱼之前要用酒米打窝,撒好酒米等半个小时左右再去钓,往往会比较合适。撒酒米吸引鱼进窝,就相当于建立索引,索引预加载,而等待的半个小时相当于建索引花的时间,这些是沉没成本,之后不管能掉上来多少鱼,这些成本是必须的。撒酒米时要适量,少了起不了吸引鱼的效果,多了把鱼喂饱了。就像索引文件的大小,建小了不行,不痛不痒,但过大甚至是超大,反而没有助益。还是一个 cost-benefit 的问题。胡扯了几句,大佬们就当是工作之余看看笑话😄 🙏
再次感谢 SPL 大佬们的付出,谢谢!
Hava a nice day! Peace!