


怎样做多数据源的混合计算
早期应用通常只会连接一个数据库,计算也都由数据库完成,基本不存在多数据源混合计算的问题。而现代应用的数据源变得很丰富,同一个应用也可能访问多种数据源,各种 SQL 和 NoSQL 数据库、文本 /XLS、WebService/Restful、Kafka、Hadoop、…。多数据源上的混合计算就是个摆在桌面需要解决的问题了。
直接在应用中硬编码实现是很繁琐的,Java 这些常用的应用开发语言很不擅长做这类事,和 SQL 比,简洁性差得很远。
把多源数据导入一个数据库再计算也不合适,且不说导入需要时间导致丧失数据实时性,有些数据想要无损地导入关系数据库(比如 Mongodb 支持和多层文档数据)是件非常困难且成本高昂的任务。毕竟这些五花八门的数据源之所以存在都是有其道理的,不可能轻松被关系数据库取代。否则人没必要发明 Mongodb,直接用 MySQL 算了。
逻辑数仓呢?听起来就很沉重。使用前先需要定义元数据来映射这些多样性的数据源,很繁琐。而且大部分逻辑数仓还是 SQL 型的,依然很难无损地映射这些多样性的数据。
那一堆计算框架呢?特别是流计算框架。倒是能接入不少数据源,但计算本身的功能却提供得很少。要么用 SQL,就会有逻辑数仓一样的映射困难问题;要想自由接入各种数据源,就自己用 Java 写计算代码。
面对多数据源上的混合计算问题,esProc SPL 才是个好方法。
esProc SPL 是纯 Java 开发的开源计算引擎,在这里 https://github.com/SPLWare/esProc 。
esProc SPL 怎么解决这个问题呢?主要是两个方面。
1. 抽象多样性数据源的访问接口,可以将五花八门的数据映射成少数几个数据对象。
2. 基于 1 中的数据对象,自行实现足够丰富且不依赖于数据源的计算能力。
有了这两方面能力,碰到新的数据源只要封装一下接口,不断补充就可以了。
esProc SPL 提供了两个基本的数据对象:序表和游标,分别对应内存数据表和流式数据表。
包括关系数据库在内,几乎所有的数据源都会提供返回这两种数据对象的接口:小数据一次性读出,使用内存数据表(序表);大数据要逐步返回,使用流式数据表(游标)。有了这两种数据对象,就可以覆盖几乎所有的数据源了。
这样,不需要事先定义元数据做映射,直接使用数据源本身提供的方法来访问数据,然后封装成这两种数据对象之一即可。这样可以保留数据源的特点,充分利用其存储和计算能力。当然更不需要先把数据做“某种”入库动作,实时访问就可以。这两种数据对象就是多样性数据源访问接口共有的能力,而逻辑数仓采用的映射数据表方法并没有正确抽象出多样性数据源的公共特征,适用面要窄很多。
需要特别指出的是,SPL 的序表和游标都支持多层结构化数据以及文本数据,这就能接收和处理 json 数据(或其二进制变种)。
看一些例子:
关系数据库,A2 返回序表,A3 返回游标
A |
|
1 |
=connect("MyCompany") |
2 |
=A1.query("select * from employees order by hire_date asc limit 100") |
3 |
=A1.cursor("select * from salaries") |
4 |
>A1.close() |
本地文件,A1/A3 返回序表,A2 返回游标
A |
|
1 |
=T("Orders.csv") |
2 |
=file("sales.txt").cursor@t() |
3 |
=file("Orders.xls").xlsimport@t() |
Restful,A1 返回 json 格式的文本
A |
|
1 |
=httpfile("http://127.0.0.1:6868/restful/emp_orders").read() |
2 |
=json(A1) |
Elastic Search
A |
|
1 |
>apikey="Authorization:ApiKey a2x6aEF……KZ29rT2hoQQ==" |
2 |
'{ "counter" : 1, "tags" : ["red"] ,"beginTime":"2022-01-03" ,"endTime":"2022-02-15" } |
3 |
=es_rest("https://localhost:9200/index1/_doc/1", "PUT",A2;"Content-Type: application/x-ndjson",apikey) |
Mongodb,A2 返回序表,A3 返回游标
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mymongo") |
2 |
=mongo_shell(A1,"{'find':'orders',filter:{OrderID: {$gte: 50}},batchSize:100}") |
3 |
=mongo_shell@dc(A1,"{'find':'orders',filter:{OrderID: { $gte: 50}},batchSize:10}") |
4 |
=mongo_close(A1) |
Kafka,A2 返回含有 json 数据的序表,A3 返回游标
A |
|
1 |
=kafka_open("/kafka/my.properties", "topic1") |
2 |
=kafka_poll(A1) |
3 |
=kafka_poll@c(A1) |
4 |
=kafka_close(A1) |
HBase,A2/A3 返回序表,A4 返回游标
A |
|
1 |
=hbase_open("hdfs://192.168.0.8", "192.168.0.8") |
2 |
=hbase_get(A1,"Orders","row1","datas:Amount":number:amt,"datas:OrderDate": date:od) |
3 |
=hbase_scan(A1,"Orders") |
4 |
=hbase_scan@c(A1,"Orders") |
5 |
=hbase_close(A1) |
esProc SPL 封装过的数据源已经很多,还在不断增加中:

esProc SPL 针对序表提供了完善的计算能力,包括过滤、分组、排序、连接等,丰富程度还远远超过 SQL,大部分运算只要一句就可以完成:
Filter:T.select(Amount>1000 && Amount<=3000 && like(Client,"*s*"))
Sort:T.sort(Client,-Amount)
Distinct:T.id(Client)
Group:T.groups(year(OrderDate);sum(Amount))
Join:join(T1:O,SellerId; T2:E,EId)
TopN:T.top(-3;Amount)
TopN in group:T.groups(Client;top(3,Amount))
游标上也有类似的计算,语法几乎完全一样,这里就不详细举例了。感兴趣的小伙伴可以参考 esProc SPL 官网上的材料。
在这些基础上,混合计算就非常容易实现了:
两个关系数据库
A |
|
1 |
=oracle.query("select EId,Name from employees") |
2 |
=mysql.query("select SellerId, sum(Amount) subtotal from Orders group by SellerId") |
3 |
=join(A1:O,SellerId; A2:E,EId) |
4 |
=A3.new(O.Name,E.subtotal) |
关系数据库与 json
A |
|
1 |
=json(file("/data/EO.json").read()) |
2 |
=A1.conj(Orders) |
3 |
=A2.select(Amount>1000 &&Amount<=3000 && like@c(Client,"*s*")) |
4 |
=db.query@x("select ID,Name,Area from Client") |
5 |
=join(A3:o,Client;A4:c,ID) |
Mongodb 和关系数据库
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell(A1,"test1.find()") |
3 |
=A2.new(Orders.OrderID,Orders.Client,Name,Gender,Dept).fetch() |
4 |
=mongo_close(A1) |
5 |
=db.query@x("select ID,Name,Area from Client") |
6 |
=join(A3:o, Orders.Client;A5:c,ID) |
Restful 和本地文本文件
A |
|
1 |
=httpfile("http://127.0.0.1:6868/api/getData").read() |
2 |
=json(A1) |
3 |
=T("/data/Client.csv") |
4 |
=join(A2:o,Client;A3:c,ClientID) |
有了混合计算能力,还可以顺便解决 T+0 计算。
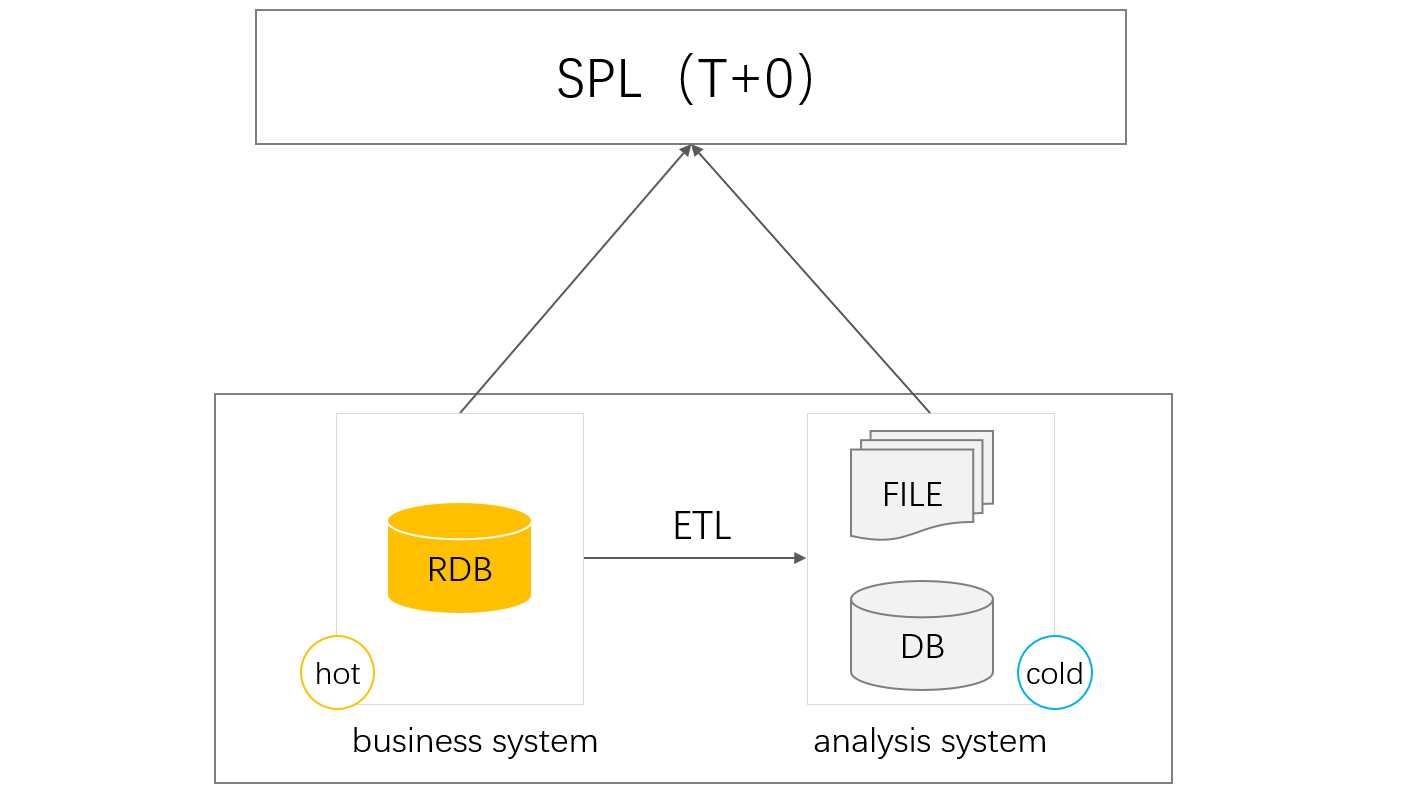
单体的 TP 数据库天然就支持 T+0 计算。数据积累太多时,会影响 TP 数据库的性能。这时候通常会把一部分历史数据移到专业的 AP 数据库中,也就是冷热分离,TP 数据库只保存近期产生的热数据,AP 数据库保存历史冷数据,TP 数据库压力减轻后即可流畅运行。
但这样,想做实时全量统计时就需要跨库计算了,而这一直是个麻烦事,特别是面对异构数据库(TP 库和 AP 库常常不是同一种)就更困难。有了 esProc SPL 这种混合数据源计算能力,这个问题就可以轻松解决了。
A |
B |
|
1 |
=[[connect@l("oracle"),"ORACLE"],[connect@l("hive"),"HIVE"]] |
|
2 |
=SQL="select month(orderdate) ordermonth,sellerid,sum(amount) samount,count(amount) camount from sales group by month(orderdate),sellerid" |
|
3 |
fork A1 |
=SQL.sqltranslate(A3(2)) |
4 |
=A3(1).query(B3) |
|
5 |
=A3.conj().groups(ordermonth,sellerid;sum(samount):totalamount,sum(camount):totalcount) |
|
TP 数据库 Oracle 和 AP 数据库 Hive 之间的混合运算,SPL 还能把 SQL 转换成不同数据库的方言语法。
那么,esProc SPL 写出来的代码如何集成到应用程序中呢?
很简单,esProc 提供了标准的 JDBC 驱动,被 Java 程序引入后,就可以使用 SPL 语句了,和调用数据库 SQL 一样。
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = conn.createStatement();
ResultSet result = statement.executeQuery("=json(file(\"Orders.csv\")).select(Amount>1000 && like(Client,\"*s*\")
较复杂的 SPL 脚本可以存成文件,然后就像调用存储过程一样:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
CallableStatement statement = conn.prepareCall("call queryOrders()");
statement.execute();
这相当于提供了一个没有存储且不用 SQL 的逻辑数据库。


英文版