


500 个 Excel 文件汇总计算的效率提升
如题,在 SPL 主目录下有一个 TrialBalance 文件夹,包含 500 个格式一致的 xlsx 文件。文件的格式如下所示:
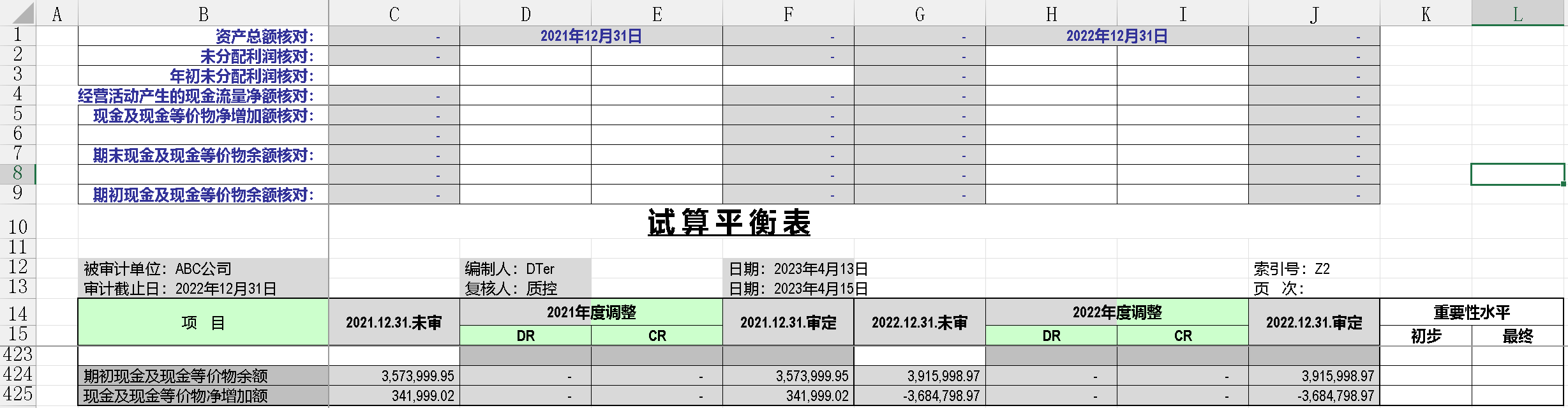
表格有 10 列,425 行,要求对 500 个文件的 C16:J425 这个区域中对应的单元格对位相加,汇总后保持源格式输出。需要汇总计算的单元格区域中,有些单元格的值 "***“,汇总后需保持”***",而不是 1500 个星号,如果是空单元格,保持空,其它的单元格都是数值,需相加后填入。一个简单的汇总计算,类似案例,在官网中也有,地址如下:
4.23 汇总文件 - 按单元格位置对位汇总 - 文件个数不定
这是一个很好的启蒙案例。但有个问题,用 xlsopen 效率不理想,如果用案例中的方法来汇总此例中的 500 个文件,需耗时 100 多秒(本机 10G 内存,配置一般)。我想到了用游标的方式来读取,把每一个文件中的区域读成嵌套序列,对位相加后汇总到一个总的序列,再用 xlscell 把这个序列写出去,代码如下:
| A | B | |
| 1 | =now() | |
| 2 | =[${fill(",",408)}] | // 创建长度为 409 的序列 |
| 3 | =directory@p("TrialBalance\\*.xlsx") | // 获取 500 个 xlsx 文件的路径 |
| 4 | =A3.(file(~).xlsimport@c(;,17:)) | // 批量获取成游标,每个表的 17 行开始 |
| 5 | >A4.run@m(~.fetch().array().m(2:).(A2.modify(#,[A2(#)++~.m(3:).(if(~=="***",null,~))]))) | // 循环 fetch 数据的同时,对序列 A2 对位相加 |
| 6 | >a=file(A3(1)).xlsopen(),a.xlscell("C17":,1;A2) | // 选择任意一个文件 open 成对象,写入 A2 序列 |
| 7 | =file("Output.xlsx").xlswrite(a) | // 输出结果 |
| 8 | =interval@ms(A1,now()) | // 本机 10G 内存,耗时 12578 毫秒 |
用游标的方法,效率有明显提升,本机 10G 内存耗时 13 秒。
发此帖的目的是想求助大佬指导:
- 代码格 A5 中,run@m() 多线程似乎对效率提升没有助益,本机最多 4 个线程,且在集算器中也设置成了最多 4 线程;
- 代码格中对 A2 序列的修改,用赋值法 A2(#)=A2(#)++~ 和用 modify 方法 A2.modify(#,[A2(#)++~]) 有没有效率上的差异,还有没有其他更好的写法?我猜测这两种写法在效率上是一样的。不像序列的拼接运算和 insert,前者会产生新的对象,而后者只是修改源对象。
- 把 A5 里的语句嵌套放进 A4 似乎会快一些,这是不是错觉?应该不至于在执行 A5 的时候又执行一次 A4 吧?
- 还有没有其它写法,可以让 xlsx 文件的处理效率有所提升,比如本机 10G 内存能否把效率提升到 10 秒以内。16G 内存的机器,代码执行效率似乎要快很多,最快能到 5 秒。我想依靠代码而不是硬件来提升效率。
- 代码效率不是很稳定,第一次执行时会慢一些,第二次执行会快很多,后续执行效率波动不会很大。
恳请大佬们得闲时给予帮助指导,谢谢!
excel 文件已打包附上,只有 10 个,500 个打包太大了,上传不了,若要测试,复制 500 个就行:


A2 写成 409.(null) 更清楚,当然这不影响速度。
A4太小了,现在run@m 会判断序列长度,太短就不做并行了,拆序列的成本很可能高于并行。一定要并行,可以写成游标方式,A4.cursor@m (4).run(…)
但这里并行会出错,多线程同时改写 A2 的相同成员,有些动作会被冲掉,SPL 不会做加锁判断(影响性能),需要程序员自己保证。
游标方式读XLS原则上不会比全读的性能好,只是少占内存。直接对着A3做运算,读出立即处理,不要全读出保持住,效果和游标是一样的。A3.run( file(~).xlsimport@w (…)…. ),用@w 读成二层序列,省掉array。
不过这个要自己试试了,通常 XLS 处理不会关注性能,我们在这方面没做刻意优化。
500 个 400 多行 10 列,也就 200 多万格,10G 内存应该没问题,可能是 JVM 分配内存不够?全部用 xlsimport@w 读入看看(这个可以并行)。
估计还是慢在 xlsimport 本身上(包括找到文件)。第二次快应该是因为被 OS 缓存了。
时间主要花在读 excel 上了,计算时间占比较小,可以忽略。所以优化点就落在读数上,可以用并行来读数。
目前A.@m ()、A.run@m ()会判断A的成员数量,如果太小不会使用多线程计算,这个会做一下修改不再根据成员数量来决定是否并行了。
目前的程序可以用 fork 语句来实现并行读数,大概可以写成如下:
fork to(4) =A3.range(A4,4).(file(~).xlsimport@(;,17:))
其中 fork 所在格为 A4,to(4) 表示采用 4 线程,A3.range(A4,4) 是把 A3 分成 4 分取当前线程对应的份,最终读取的数据会放在 fork 格上
谢谢老贼,谢谢 leavedy,Thank you for your time🙏
一下子信息量有点大,我得慢慢消化。
实话讲,500 个 excel 文件简单汇总后输出,用的是 15 年的水果机 +WINDOWS 虚拟机 10G 内存,13 秒已经很快了。
目前测试出用 @w 读成序列和 @c 游标的方式执行效率几乎是一样的。
接下来看一下能否实现并行处理,等我写出来了,再汇报测试情况。
对于并行多线程,@m 会判断成员数量,这点大佬已经说了。但对于 fork 是不是也有这样的限制,我用 fork 分成 4 路,其实际执行时间跟串行执行的时间几乎是一样的。按照我的理解,用 4 个线程执行时,其效率是由耗时最长的那个线程决定的,比如,串行执行耗时 12 秒,那 4 线程运行时最理想的状态是不是应该是 3 秒?当然,5 秒,6 秒也有可能,最坏应该不可能跟串行一样,对吧?
我按照大佬的指导,分别写了以下两组代码:
代码 1:串行,本机耗时 13876
代码 2:fork 并行,本机耗时 13922
这样的话,是不是说明 fork 多线程没有用起来?
集算器里的设置如下所示:
恳请大佬解惑🙏
我测试了一下并行是有效果的
=invoke(com.scudata.dm.Env.getParallelNum)
请在格子里执行一下这个表达式看看返回值是不是大于 1
返回值是 4,我这边用的是海外版:
我抄了一模一样的代码,fork 和串行耗时如下:
是不是我电脑的配置有问题?是个假的 4 核。并行效果一直没有实现过。😄
不太清楚了,会不会是用虚拟机的缘故?
配置都没有问题。
硬盘可能就这速度了,CPU 可以并行,笔记本电脑只有一块硬盘,通常没啥并行能力(SSD 好一点),只能捡 CPU 忙的时候。但 CPU 时间很少的时候,硬盘已经跑满了。
第二次快很多也是因为被 OS 缓存了,没有实质的硬盘动作。16G 快很多,可能也是因为 OS 能缓存得多。
可以用 file.read@b() 尝试一下硬读这些文件需要多长时间,这个性能的极限(即使 CPU 啥也不干也需要这个时间)。
我测试出并行效果了😄 ,真的是 666👍 👍 👍 (赞美词匮乏,只能用 666+ 大拇指,哈哈)
之前是在本机的 WIN 虚拟系统里测试的,整个虚拟系统是由 Parallels Desktop 集成的。可能某些未知原因,导致并行不成功。虚拟机里 4 核,标的是虚拟处理器,截图如下:
我重新在水果机上装了 SPL 的 Mac 社区版,并行成功了,哈哈,No pics,it didn’t happen。
It works like a charm…SPL 遥遥领先。
谢谢老贼,谢谢 leavedy,感谢你们的指导解惑,让我学到了很多!
Hava a nice day! Peace!
以下游标用法若有不当之处,恳请大佬指导为盼!
游标方法 1:多路游标 mcursor
因为源文件格式一致,所以可以用多路游标 mcursor。mcursor 可以把游标序列转换成多路游标,最终合并成一个序表。所以有了以下写法:
如果把上述 A3 代码格中的 mcursor 游标 fetch 出来,结果是一个序表,总行数是 500×409,所以在 A4 代码格中,用 groups 处理 A3 生成的多路游标,分组依据是序号 #,且这个序号是隐藏的,这一点不知道是不是凑巧,多路游标在处理时,每一个表中的行号都是从 1 到 409,正好作为分组聚合的依据。A4 生成的分组聚合的部分结果如下所示:
游标方法 2:多路游标 cursor@m(4)
cursor@m 也可以把游标序列变成多路游标,但其执行逻辑跟 mcursor 不同,mcursor 会把所有游标结果汇总成一个序表,而 cursor@m 生成的依然是多路游标,以下代码格 A5 中的多路游标 fetch 出来后是 500 个序列,并没有像 mcursor 一样合并成序表,这是最大的不同,但两者的效率几乎无差别。
感谢各位大佬的专业讨论,我从中学到了很多。
可以看到,SPL 效率很高,但是受限于 xlsx 格式的原因,导致最终整体效率不是很高,有点遗憾。
Excel 是目前最普遍的数据处理工具,几乎所有行业都离不开 excel。而且,基本上没有其他工具可以超越它的地位。
Excel 有着庞大的用户基础,如果 SPL 能在 Excel(xlsx) 方面给予更多的关注和努力,那么将对 SPL 的快速普及有很大的帮助。
对于 xlsx 格式,我们非常希望 SPL 能提高对它的读写速度,这将大幅改善用户体验,也能增强用户对 SPL 的依赖性。
如果 SPL 能够在 Excel 插件上更进一步,或者开发出 Ribbon 界面的插件选项卡,提供常用的数据处理功能,与 Excel 更紧密的结合,培养用户习惯,那么 SPL 绝对会成为广大 Excel 用户不可替代的利器。在此基础上,将会有相当一部分用户会对公司的更多产品感兴趣,如报表等。
就本人而言,日常工作就是处理各种类型的数据,大部分是 xlsx 格式,非常希望 SPL 能够高效率地处理这些数据。
另外,对正则表达式的高水平的支持也是本人对 SPL 的期望之一。
希望开发者们不要仅仅关注特定行业的工作内容,更要关注更多行业从业者的日常工作,了解他们如何处理数据,了解他们的真实需求,了解他们的痛点,这样才会使 SPL 逐渐形成它的稳固地位。
共同期待!
很遗憾,这几件事都做不了。
提高 xlsx 读取性能,我们没本事搞出来,这难度比自己重做个 Excel 都大,等微软吧。
Ribbon 插件,主要是界面的问题,这本身不是 SPL 团队擅长的(我们擅长数据计算的抽象),技术方向也不匹配(WIN GUI 编程,这个团队几乎无人会,Java 的显然又绑不上去),留待其他擅长这些技术的团队去做吧,SPL 提供计算支持就行了。
正则表达式,基本上可以说是个失败的设计,专业程序员都很少会用的。SPL 当然也支持它(因为 Java 支持),但再进一步自己研究完善它,性价比太低了,完全划不来。
这个运算的时间应该主要就是 xlsimport,它被并行的情况决定了最后的性能,其它动作时间占比可以忽略。
Excel 最大才 100 万行,远远算不上大数据,基本上没有用游标的理由,特别是指望游标来提速更啥没可能性。
从开始学习 SPL 到现在 3 个月的时间里见识了 SPL 的高效简洁,amazingly awesome,我相信 SPL 还有更多神奇的地方有待探索实践。当然,这些全仰仗于 SPL 大佬们的贡献。说来说去有两个问题是数据处理工作者比较关心的:
1、电子表格格式 (EXCEL、WPS) 读取的提速。我之前说了指望用游标来提速,这确实有一定的效果,比如用 xlsimport@w 和 xlsimport@c 作对比,读取几千行数据两者当然没有区别,读取 5 万行 30 列的数据,@w 就会溢出报错了(GC excede limi,好像是这样的报错),而 @c 会在两三秒的时间里读出来。那数据量大了怎么弄?转换存储格式,把 xlsx 格式用游标的形式写出去变成文本格式 csv 或者 txt,或者 SPL 的存储格式 btx/ctx。但 50 万行 30 列的 btx 文件读取很吃力,甚至是报错死机,而 50 万行 26 列的 btx 又可以在几秒的时间里读出来,就差了 4 列,效率差异很大,这也是叫人困惑。
2、正则表达式虽然很难掌握且效率一般,但不得不承认,它是一种很好的文本处理手段。比如以下正则替换:
如果 SPL 的 regex@a,replace 函数能实现二参使用上述 1,2 两种情况,那就很好很灵活了。
啥 30 列的 btx 会读不出来,300 列都不会有问题,你拿出来让人看看。
我刚测试了一下,还是有问题,这个 btx 文件是通过 excel 文件以游标的形式写出来的。
读 1-27 列没有问题,读到 28 列报错如下:
不指定字段,缺省读取 30 列时,报错如下:
这不用上传文件了,错误信息很明显告诉你内存不够了,JAVA 对内存很敏感。换个大内存机器很可能啥事都没有。
所以 Excel 也不能一下子读出来,这种时候要用游标去算了。
那就不纠结了😄 ,谢谢老贼解惑。🙏