


提高开发效率的不是五花八门的框架,而是类库
计算框架五花八门,有用于流式计算的Flink,用于边缘计算的eKuiper、用于大规模分布式计算的MapReduce,还有Spark、Samza、Storm、Omega、Kubernetes、Oracle Event Processing、Spring Batch、DataX、Kettle、influxdb、TDengine等。很多开发者认为这些计算框架可以大幅减少开发工作量,研究学习的氛围很浓厚,进而催生出更多的框架出来。
计算框架对减少工作量的作用不大
应用结构很重要,是开发工作成败的关键,现成的计算框架避免了从头开发结构性代码,可以节省这部分的开发工作量。但是,结构性代码与具体业务无关,即使自行开发,工作量也不大,应用程序使用计算框架后,能减少的工作量很有限。实际上,应用程序的主要工作量是业务逻辑代码,也就是结构里的内容,计算框架的关注点在于结构性代码,而不是业务逻辑代码,很难减少这部分的工作量。
此外,计算框架是根据典型场景做死的,有着严格的限制,很难面面俱到,比如很难把Flink集成进应用程序内部,很难让MapReduce发挥高性能小集群的优势。
计算类库对减少工作量的作用更大
计算框架很重要,但对减少工作量的作用不大。那么什么东西才能提高开发效率?应用程序的主要工作量是业务逻辑代码,如果有现成的东西可简化业务逻辑的编写,就能减少工作量了。
这就是类库。
JDK下有很多计算类库。比如JDK自带的Stream内置去重、排序、分组、最大、最小等函数,方便了流数据的计算;Tablesaw提供了排序、过滤、聚合等函数,可以避免自己硬编码;JsonPath提供了查询Json串的语法,可以用简短的语句查询多层Json。这些类库接口友好,可以被Java程序直接调用,可以显著减少业务逻辑的开发工作量。
此外,计算类库没有结构性代码,不会受限于典型应用场景,开发者可以将其自由应用于创新的计算场景,根据具体场景设计细节功能,或将必要的场景维度自由组合在一起。
良好计算类库的标准
作为良好的计算类库,是不是只要做好一大堆函数就行了,比如在Stream里增加分组汇总和关联计算函数?
丰富的函数是良好计算类库的基本标准,但远远不够,良好计算类库还应当具备以下特征:
专业的数据对象,专用于计算的语言。计算类库的所有功能都基于底层的数据对象(结构化数据为主,数组、矩阵为辅),这种数据对象以计算为目标,专业性很强,与EntityBean之类的普通对象区别较大。从空间、性能、运行稳定性、接口便利性等方面考虑,这种以计算为目标的数据对象应当是编程语言原生提供的,这就要求编程语言本身是专用于计算的语言,而不是Java\C#等用途通用的语言。
解释型语言。计算过程通常有多个步骤组成,每个步骤的中间结果通常都不同,数据结构也不同,这就要求计算类库基于解释型的计算语言,有动态推断数据结构的能力,否则就要像Scala等编译型语言一样,事先定义每一步的数据结构,代码将很难编写。解释型语言还可以简化Lambda语法的接口规则,可以用简短的代码实现较复杂的业务逻辑。
原生的计算函数库和流程控制语法。除了数据对象外,计算函数库和流程控制语法也应当是原生的,这样才能获得来自底层的支持,才能保证执行效率和表达效率这两大核心指标。Pandas这种Python的第三方函数库不算良好的计算类库,SQLite这种需要借助外部实现流程控制的内存数据库也不是。
开放的计算体系。良好的计算类库,应当可以直接计算常见的数据源,并直接进行跨源计算,如文件、RDB、微服务、流数据、大数据,而不是像数据库那样事先执行耗时繁琐的操作,如建库、建表结构、入库。
易于集成的接口。计算类库实现业务逻辑代码后,通常要被通用程序语言调用,成为整体项目的一部分,这就要求计算类库提供易于集成的接口,比如JDBC\ODBC\HTTP等,API接口会绑定编程语言,勉强可以接受但不算优选接口,比如Tablesaw类库。
SPL是良好的计算类库
SPL是基于JVM的轻量级开源计算类库,不仅内置丰富的函数库,还提供了易用的集成接口和表达能力足够强的解释型计算语言,内置专用于计算的数据对象、原生的计算函数库和流程控制语法,支持开放的计算体系,达到了良好计算类库的标准。
解释型计算语言
SPL是解释型计算语言,其Lambda表达式接口简单易用,可以方便地推断出值参数和函数参数,适合中间步骤较多的复杂计算。
专业的数据对象
SPL设计了序表这种专用于数据计算的对象,序表优先使用游离记录,与复制记录相比,占用的内存少,性能高。序表天然具备序号;可方便地访问字段。
SPL还可以动态推断计算结果的数据结构,适合较复杂的多步骤计算:
````
=join(Orders:o,SellerId ; Employees:e,EId)
.groups(e.DEPT;sum(o.Amount):amt,count(1):cnt)
.select(amt>1000 && amt<3000)
````
原生的计算函数库和流程控制语法
基于解释型语言和专业的数据对象,SPL提供了原生的计算函数库,可以轻松完成日常的SQL式计算,实现各种场景下的业务逻辑,比如去重、分组汇总、关联等。
SPL集合化更彻底,支持有序计算、分步计算、对象式关联计算,可以简化复杂的业务逻辑。基于高性能私有格式,SPL提供了大量高性能算法,可显著提升IO性能和计算性能。
SPL提供原生的流程控制语法,可以方便地实现日常业务逻辑。分支结构:
A |
B |
|
3 |
for T |
=A3.BONUS=A3.BONUS+A3.AMOUNT*0.01 |
4 |
=A3.CLIENT=CONCAT(LEFT(A3.CLIENT,4), "co.,ltd.") |
|
5 |
… |
开放的计算体系
不必事先入库建模,SPL可直接计算多种数据源,并将计算结果写入新数据源,包括各类文件、RDB、Restful、Hive、MongoDB、Kafka等。
易用的JDBC集成接口
SPL计算代码以脚本文件的形式存于操作系统目录,Java代码通过JDBC调用SPL脚本文件,调用方法同存储过程。
例子:将SPL脚本存为mix.splx,Java通过JDBC调用脚本:
````
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
CallableStatement statement = conn.prepareCall("{call mix(?, ?)}");
statement.setObject(1, "2022-01-01");
statement.setObject(2, "2022-12-31");
statement.execute();
````
除了JDBC接口,SPL还内置HTTP服务,允许上层应用以POST/GET方式直接调用脚本文件,终端设备也可以通过该方式将消息推送给SPL去处理。
计算框架的计算代码与非计算代码是高度混合的,SPL弱化框架属性强化类库属性,计算代码外置于Java的非计算代码,两者各司其职专业互补,一方改动不影响另一方,程序员不用借助控制类框架(如Spring),就可以用简单代码降低计算逻辑和前端应用的耦合性。
SPL是解释型语言,修改后可立即执行,无须编译无须停机无须重启 JAVA 应用,程序员无需编写额外的结构性代码,可直接实现计算逻辑的热切换。
SPL应用场景举例
成熟的计算类库不限于某个典型的应用场景,可方便地集成到多种多样的应用场景中,下面选部分举例。
常规计算
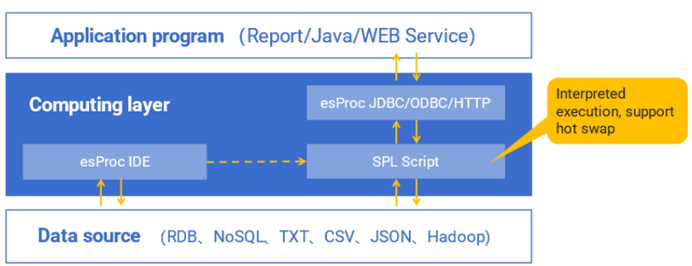
常规计算场景即Birt/JasperReport等Java报表应用,或Servlet\JSP等Java Web应用,以及Java桌面或命令行应用。
报表计算
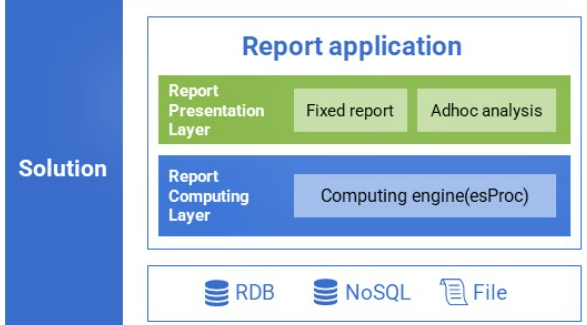
报表的开发要经过数据准备和数据呈现两个过程,报表工具只能解决呈现环节的问题,而对数据准备无能为力。SPL 计算能力强,可以简化报表数据准备,弥补报表工具计算能力不足,全面提升报表开发效率。
OLAP多维分析
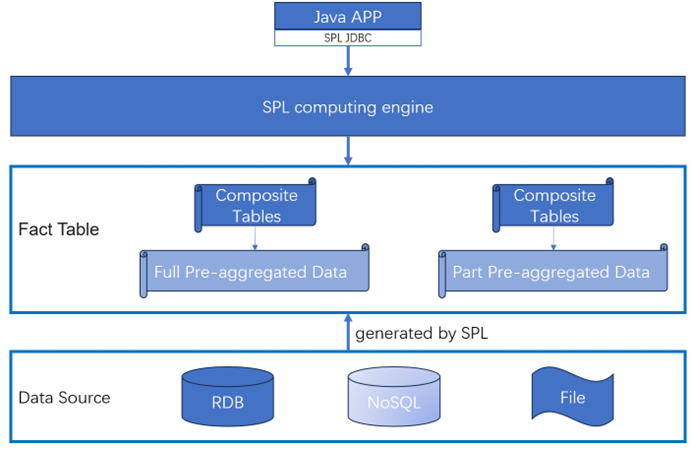
多维分析是OLAP的重点细分场景,需要对多维度大体积的事实数据进行计算,并立刻返回计算结果,SPL创新的提出离散数据集代数,支持SQL很难实现的高性能算法及高性能存储格式,可以大幅提升多维分析的性能。
时序计算
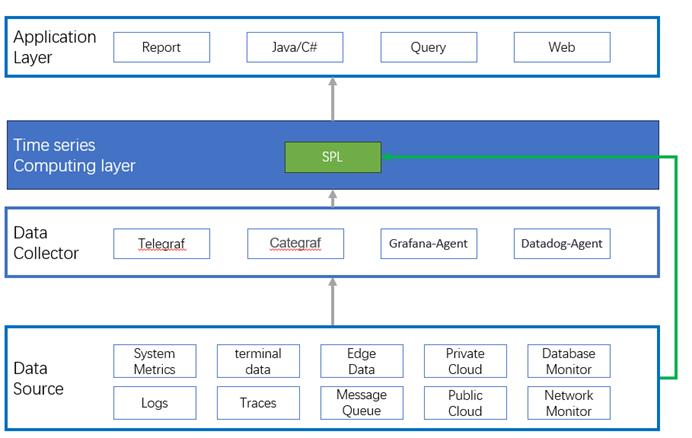
时序计算的数据源涉及各类包含时间字段的HTTP数据、日志数据、消息数据,通常要用数据采集器作为中转。SPL内置HTTP服务,支持高性能存储格式,支持有序集合且集合化更彻底,特别适合时序计算。
离线跑批
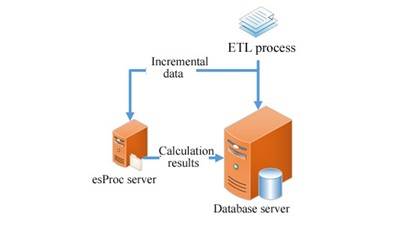
离线跑批虽然并发要求低,但涉及的数据量往往很大,计算逻辑也很复杂,SPL提供了各类高性能算法、表达能力够强的计算语法,支持多数据源混合计算,非常适合跑批场景。
微服务
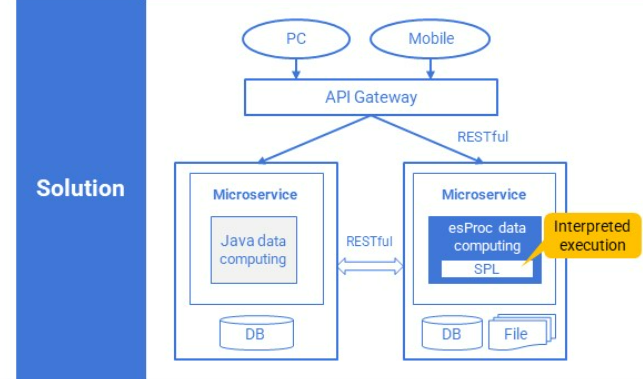
SPL是微服务理想的计算引擎,具备丰富计算类库与敏捷语法,可以大幅简化数据处理;体系开放可以实时处理任意数据源数据;解释执行天然支持热切换;借助高效算法与并行机制可以充分保证计算性能。

