


关于 rename 对缺失字段容错以及 import 列别名的问题
大佬们,过节好。🙏
相比较于去年风声鹤 li,挡板皆兵,能被 ju 委 hui、jie 道 ban 随意拿捏,行动不便的假期,今年的长假显得更随性自由,这些多亏了强大的祖国。那表哥表妹实现数据处理随性自由要靠谁,我觉得要靠强大的 SPL,但 SPL 也有一些限制,比如函数 rename 更改字段名时对缺失字段的处理没有容错,这也是一种限制。
函数 rename 更改已经存在的字段名没有问题,很直观,如下图所示:
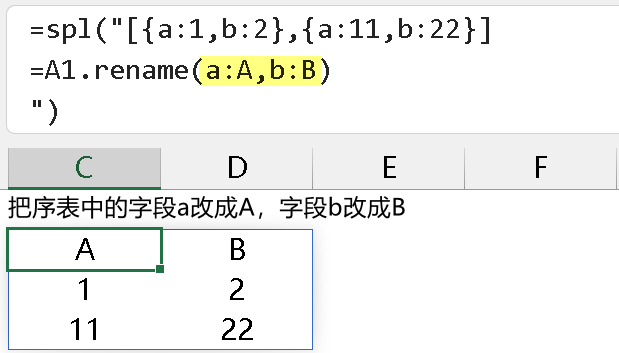
但是,如果涉及到了序表中不存在的字段名,SPL 会直接抛出错误,如下所示,在参数中增加一个 c:C,把不存在的小写 c 字段名改成大写 C 字段名,此时抛出”字段不存在“的错误:
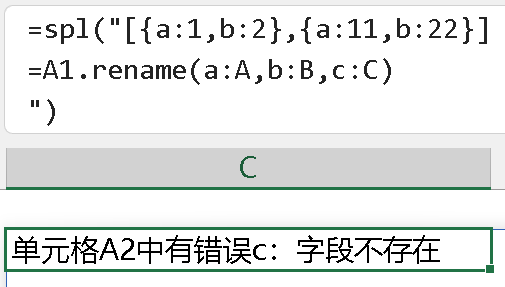
当然,这样报错肯定是没有问题的。我想说的是:
rename 能不能实现自由度更大一些的选项拓展?实现对缺失字段的容错处理。
依然用 Power Query(以下简称 PQ) 中具有类似功能的的 Table.RenameColumns 函数举例如下:
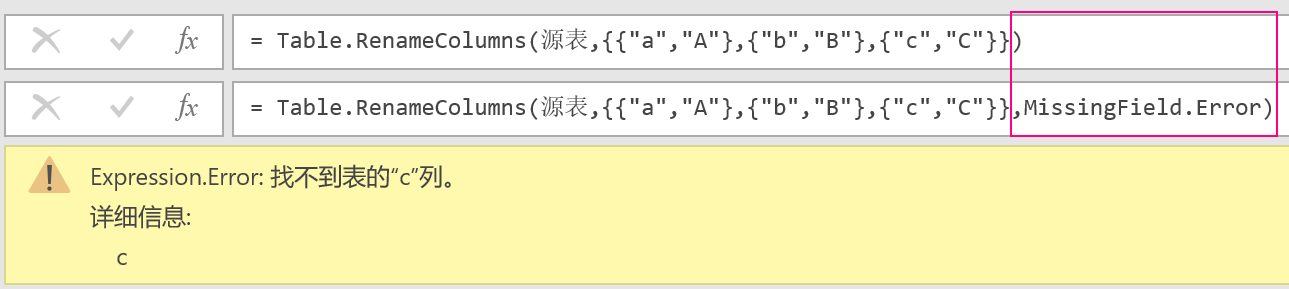
1、字段不存在时,依然保持报错,这是基本的功能。PQ 的 rename 函数多了一个处理 MissingField 的参数,在缺省或者指定为 MissingField.Error 时,会抛出错误:
2、对不存在的字段实现容错忽略的处理,正常显示更改后的结果,如果没有更改就返回原序表。PQ 里用了 MissingField.Ignore 参数:

3、对不存在的字段作为添加新列处理,列值用 null 填充。PQ 里用了 MissingField.UseNull 参数:

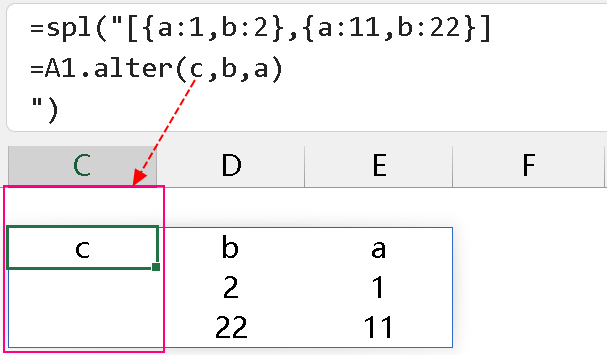
上述第三点”对不存在的字段处理成添加列“,SPL 中的 alter 函数也有该功能,如下所示,在更改列顺序的同时,对不存在的 c 列作为添加列处理,并用 null 填充:
=========================================================================
由此,引出另一个问题:
如何在读取文件的同时实现重新命名列别名,模拟 SQL 语句 "select a as A,b as B from table"
比如,主目录下有一个 test.xlsx 文件,有 4 个字段,字段名分别为 "客户名称",“状态”,“建筑面积”,“日期”,用 xlsimport 读取数据时,可以实现只获取其中的若干列,比如,只获取客户名称和建筑面积这两列:

那能不能实现这样的写法,在获取列数据的同时可以命名列别名:
- 1、file(“test.xlsx”).xlsimport@t(客户名称: 名称, 建筑面积: 面积)
- 2、T(“test.xlsx”, 客户名称: 名称, 建筑面积: 面积)
相当于 "select 客户名称 as 名称, 建筑面积 as 面积 from test.xlsx"。
甚至于,在读取列的同时,不仅可以命名列别名,还能指定数据类型,比如,把参数写成 "原列名: 新列名: 数据类型"。import 方法在读取数据时是可以指定数据类型的。按目前的函数功能,要想实现更改列名的效果,只能依靠 rename 方法,或者用 new 方法按字段一个一个写出去,当然这两种方法的本质也不同,rename 方法能改变源序表,而 new 方法会生成一个新的序表,两种方法都不直接。
因为在输出时 xlsexport、export 函数是支持字段处理和列别名的:
- 1、f.xlsexport(A,x:F,…;s;p)
- 2、f.export(A,x:F,…;s)
这些想法可能是我异想天开了,恳请大佬们指点解惑。若能实现函数功能拓展,那是最好不过了。
万分感谢!Happy Holidays!


rename 就是 rename,它不会对任何一条记录的对象做动作,只是改变数据结构定义这个对象。这样速度比较快。
从逻辑上讲并不需要这个功能,修正数据结构时应该统一用 alter 方法,但这会真地会产生新的记录对象。如果仅仅是为了改变字段名(以便使下一步运算进行某种对齐,比如 merge)而产生新对象,速度会变慢,数据量大的时候影响会非常大,所以才提供了 rename。
rename 可以理解为 alter 在简化却较常见的情况下的高速实现。补上原来不存在的 null 字段,事实上会真地生成新的记录对象了,这时候不要用 rename 了。
至于 import 增加别名的问题,那个本质上是个计算列,并不是简单的别名,SQL 中的 as 前面也可以是个表达式。export 里的 x 也不是个别名,而是个表达式。
import 和 export 在这方面设计得不对称,是权衡的结果。import 时的计算用.new 再描述并不算麻烦且对性能几乎无影响,一定要并进 import 会导致更常用的数据类型信息更难写,计算过程时还要再分析表达式中引用的字段才能保证高性能读取,这会有较高的实现成本,复杂化本身也会影响性能。而 export 没有数据类型信息,可以利用这个参数位置来描述计算列,实现成本也不高。绝大多数情况下,import 对性能的要求要远高于 export,import 的优化方向是快,export 则是方便(反正写外存都不会太快)。
谢谢老贼解惑。
导入时修改别名和指定数据类型,是之前在微信群里有群友提起过,正好跟 rename 也有点类似,所以这次一起发帖求助了。既然这个会负面影响效率,那就不管他了,效率第一。一句代码执行 10 分钟,和 10 句代码执行只需 1 分钟,那我宁愿多写几句。
rename 对不存在的字段作为添加列处理,涉及到生成新对象,这个也影响效率,果断不需要。这个功能在 PQ 里也几乎用不上。
但在 PQ 应用中,renamecolumns 对不存在的字段进行忽略错误,正常显示源表,倒是一个常用实用的功能。我倒不是说外国佬的 PQ 有多高明,实际上 PQ 的效率低下一直是个问题,远不及 SPL 高效简洁。自从跟 SPL 结缘,我现在几乎放弃使用 PQ 了。
所以,恳请大神考虑,在不牺牲效率的前提下,SPL 的 rename 函数可不可以实现对 missingfield 的容错处理,更改能改的列名,忽略不存在的列,同时返回结果,而不是直接抛出错误,不知道这样的函数选项设计对 SPL 效率会不会有负面影响?底层的逻辑我也不懂,我就是单纯觉得有容错选项可以写起来更自由一些。
期待大神回复🙏
增加这个选项不会影响性能,但有什么实际用途吗?
对于想不清有没用的情况,设计原则是由实际需求来刺激,而不是主动穷举所有可能性,那可能会搞出很多一辈子也用不上的东西(其实 SPL
里多少也有点这类内容)。
谢谢老贼回复,情况是这样的:
先举个简单的例子,如下图所示,左侧从上到下分别是 3 个表,因为某些原因,字段名写的不一样,而实际上有相同关键字的字段需视为同一个字段,也就是说 a=a1,b=b1…,要求合并表格,相同的字段对齐。目前的写法是,为了避免报错,每一个表要先判断之后再 rename 字段名:
如果,rename 函数可以忽略缺失字段的报错,那写法上可以简洁很多,不用再去判断哪一个表要更改哪一个字段名,比如写成这样:
以上案例并非臆造,在实际工作中,我有一些表格需要合并,因为某些阿三设计的软件,对字段的命名很随性,不一致,比如商品名称、产品名称、品名实际上是一样的,商品价格、产品价格、产品单价、价格也是一样的……,诸如此类,30 个字段,有多种不同的命名,每次都要手动去改,不胜其烦。所以才会有这个求助帖子。我在工作中也碰到过另外一些企业,他们对数据管理这一块是很随性的,最常见的就是字段名的随意命名,导致后期需要花费大量时间去清洗数据,比如一些医院对医用耗材的核算,换个领导换个系统,五花八门的设计,原因就不说了;还有一些外企,系统都是自己设计或者委托阿三设计的,一个岗位多的有十套小系统,用户名密码写满一张 A4 纸,数据很乱。做数据分析的基本上的时间都消耗在了清洗这一块。
In my humble opinion,函数的有些功能有应该比没有要好,no offense🙏 ,用不用的上另说,就像核武器,有而不用和没得用,那是截然不同的姿态和底气。我倒不是说 SPL 非要弄成跟外国佬的 PQ 一样,SPL 也不是 ETL 工具,我觉得 SPL 已经强于 PQ 了。当然,rename 如能拓展,自然是锦上添花。😄
rename 函数做了修改,F 不存在时不再抛出异常
开源程序已更新,请打包试用
握艹,what a surprise,这就改啦,有点小激动😄
感谢老贼,老贼威武!
感谢 leavedy,大佬辛苦啦!
SPL…遥遥领先!
大佬,这个更新在哪里啊?😄
集算器 (SPL) 最新版发布啦『发布日期 20260507』
更新下载贴里的 bin-jar