


SPL 简单 sql 中的 4 个小问题
大佬们,我在学习 SPL 的简单 sql 语句时碰到 4 个小问题,恳请指点解惑。
一、SPL 主目录下有 3 个相同结构的 xlsx 文件,文件名分别为 a1、a2、a3,简单 sql 语句可以实现把这 3 个同结构文件合并,如下所示:
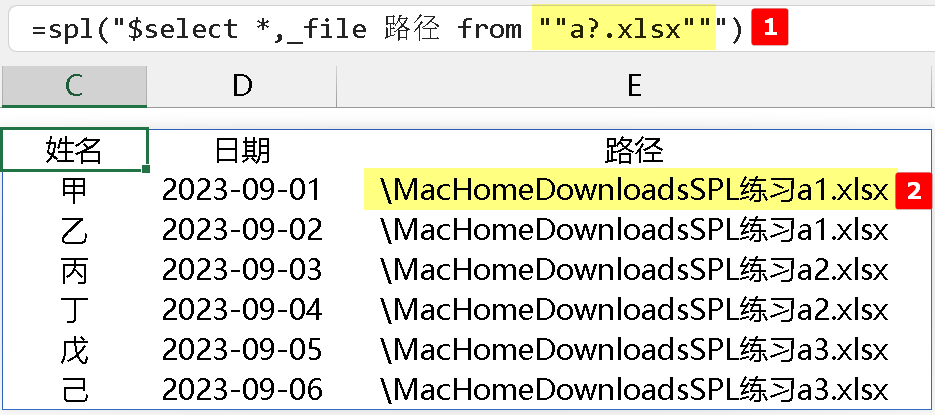
问题 1:文件名可以用通配符,那扩展名里可不可以也实现使用通配符,比如,.*x 表示 xlsx 文件和 btx 文件,.xls? 表示 xls 或者 xlsx 文件。
问题 2:用 _file 返回路径时,路径中的分隔符 "\" 不见了,具体如上图所示。
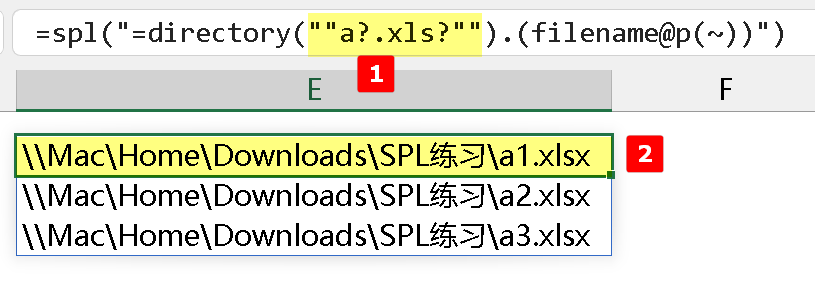
因为在 SPL 中,用 directory 时,不存在以上两个问题,通配符在文件名和扩展名里均可使用,返回的路径也是完整的,如下图所示:
二、简单 sql 语句可以读 csv 文件,这个很好用,但是如果字段对应的值里也有逗号,就会缺失部分数据。比如有一个标准的 csv 文件,用 file().import@tqc() 读出来是这样的:
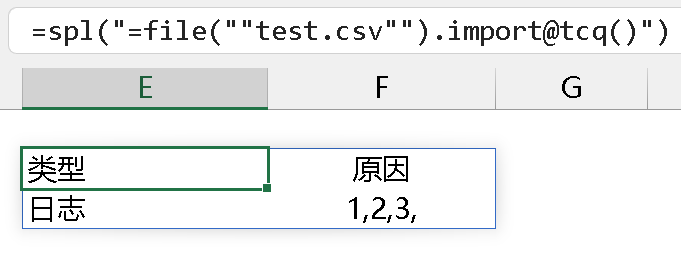
可以看到,原因字段里的值也是用逗号分隔的,此处要作为整体读出来,@q 选项很好的解决了这个问题。但是,如果用简单 sql 语句去读取时,字段值有一部分数据没了,如下:
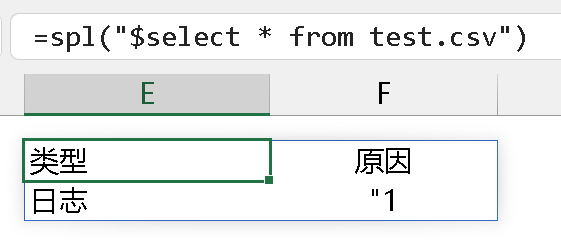
所以,问题 3:用 sql 语句读取文本文件时 (csv,txt),如果分隔符比较特殊,需要怎么处理?
问题 4:sql 语句中也有 pivot 语句,比如 sql server 里的 pivot 或者 oracle 里也有 pivot,甚至是 access 的 sql 语句也有 pivot 关键词,比如以下语句在 VBA 里调用 ADODB 是可以跑出结果来的:
TRANSFORM SUM(成绩) SELECT 姓名 FROM [成绩表 $] WHERE 成绩 >=60 GROUP BY 姓名 PIVOT 学科
在 SPL 里,sql 语句必须以 select 开始,所以这样写是跑不通的,但 SPL 又支持 with 语句,我在想 SPL 是不是也能实现一个 pivot 语句?
以上 4 个小问题,恳请大佬们得闲时给予帮助,谢谢!


学了 SPL 就别倒退回去再用 SQL 了,没意义。简单 SQL 仅是为了针对还没来得及学会 SPL 语法的同学。
这些都是这么约定的的,有基本功能不影响初上手的同学实验,有些是 SQL 本身描述能力不足导致,完善起来成本非常高。
我们没能力更没兴趣去强化 SQL 语法,这方面功能事实上已经强得过头了(对于前述目的),反而可能会进一步弱化。
早上好,老贼😄
我也是看了官网的文章,“没有 RDB 也能 SQL” 没有 RDB 也敢揽 SQL 活的开源金刚钻 SPL
感觉比较新奇,故而试了一下。正如您说的,越学越回去,意义不大。谢谢老贼解惑。
老贼,周末好。关于简单 SQL,就像您所说的,SPL 再去强化 SQL 语法确实是本末倒置了,但对现存的一些小问题,能不能 debug 一下?
1、我发现另一个问题,简单 SQL 是不是不能用表的别名?按照文档案例 11,简单 SQL 是可以用表别名的,截图如下:
我测试的结果是这样的,表别名和文件名拼接在一起了(用 as 别名时也会拼接在一起),如下所示:
2、简单 SQL 里的 left 函数能用,但 right 函数用不了,如下:
3、然后就是帖子中提到的第一点,_file 返回的路径缺少分隔符。
简单 SQL 目前还没弃用,所以 (my two cents) 以上两点,您看可不可以修改一下?
另一点, /*+parallel(n) */ 这个并行语法,有没有 + 加号? 文档说明里没有 +,举例中有 +。应该是要有 + 的。
最后一点 Transform pivot 语法,我通过其他途径解决了,用 ODBC 连接 Excel 文件时,就可以用这个语法。
表别名的 bug 改好了;
增加了 right 函数;
_file 中路径增加了 / 分隔符;
不打算支持 parallel。
谢谢大佬🙏
关于 parallel 并行,您说的 "不打算支持",意思是会取消这个 parallel,还是说这个功能根本没存在过?
![imagepng]()
那以下截图中的 parallel 关键词有没有起作用?语法是对的,能跑出来结果。😄
核实了一下,能支持,parallel 前有 +,和 oracle 保持一致;
已告知写文档的同事更正文档🙏
666👍 👍 👍 谢谢大佬,Thx for ur time!
debug 要更新 jar 包吗?今天 19:59:26 更新的 jar 包是针对本帖的需求吗?
稍等更新今天的 bin jar 包就可以了。 集算器 (SPL) 最新版发布啦『发布日期 20260507』
😄 齐活:
谢谢 xjl 大佬🙏
谢谢老贼🙏
SPL 遥遥领先👍 👍 👍