


SPL 离向量数据库有多远
ChatGPT带火了大模型,也带火了向量数据库。大模型训练成本高,学习新知识的周期太长,而向量数据库刚好可以充当大模型的“记忆”模块,找到与新问题相似的旧问题交给大模型处理,极大地扩展了大模型的应用范围,这才有了这一轮向量数据库的火爆。其实在传统的 AI 和机器学习场景中,向量数据库已经有所应用,比如人脸识别、图像搜索、语音识别等。
向量数据库的主要任务是从海量向量数据中寻找与目标向量相似的向量。这在逻辑上没啥难的,就是个 TopN 而已,用传统关系数据库的 SQL 也很容易写出这种查询。但是,高维向量无法定义次序,也就无法事先建立索引,传统数据库中只能硬遍历,计算量非常巨大,性能很差。向量数据库则对这件事做了特别优化,提供了一些高效查找相似向量的方法,大幅度提高性能。
看起来,向量数据库就是一种有特殊用途的数据库,只要把向量数据装进去,就可以实现向量查找了。毕竟我们就是这么使用关系数据库的,把结构化数据装进去,然后就可以用 SQL 查询,通常不用关心 SQL 是如何被数据库解析和优化的。
然而,向量数据库并没有这么简单,使用它实现向量查找的过程是复杂且个性化的。
1. 向量数据库通常没有像关系数据库那个简单易用的 SQL 语法,只有基础算法的 API,需要用较基础的程序语言(C/C++,Java, 好一点会有 Python 接口)调用这些 API 自行完成向量查找任务,除 Python 外的这些语言都没有成熟通行的向量数据类型,用来开发向量相关的计算并不方便。即使 Python 有向量数据类型,受限于它有限的大数据处理能力和并行能力,做向量计算也有不少困难。关系数据库就没有这种问题,直接用 SQL 查询数据即可,通常不需要依赖基础程序语言的计算能力。
2. 向量计算需要个性化的数据预处理,没有这个过程,后续的运算就会失去意义。比如浮点数向量需要归一化、降维、变换等;二值向量要数据转换、维度排序和选择等。即使是相同格式的数据,预处理方式可能也不同,比如文本向量,可能只需要正常的降维,而图像数据还要进行卷积。这些预处理不仅方法众多,还都有许多要调配的参数,而且经常和具体的数据相关,具有很强的个性化。一般的向量数据库并不提供这类预处理方法,或者即使提供也只有固定的几种方式,无法满足个性化的需求。结果这工作只能依赖于外围的程序语言或再引入第三方技术来完成。相比之下,在关系数据库中使用结构化数据就简单得多,通常不需要预处理,即使有也都很简单,无非就是编码和数据类型转换等,SQL 本身都能做。
3. 需要选择创建索引的算法甚至是选择向量数据库。高效查找向量的关键是有适应数据分布特点的索引,但索引算法太多,比如 k-means 聚类、IVF-PQ 算法、Faiss 算法、HNSW 算法、LSH 算法等,仅仅是了解这些方法都需要相当的数学知识,况且通常还要反复调整算法参数(比如 k-means 的参数 k,对数据不了解或者经验不足的开发人员几乎不可能设置出合适的 k)才可能得到查找效率高且精度也较高的聚类算法。还有更坏的消息,向量数据库通常只提供了几种索引算法,而这些方法并不是“放之四海而皆准”的,还需要根据数据分布特点而定,如果随意选择了一款向量数据库,在调了很久的算法参数后,发现该向量数据库的索引根本不适合自己的数据(查找效率或者精度无法满足要求),这时再换数据库恐怕会是一场灾难。下图是目前排名靠前的几个向量数据库的索引创建方法:

4. 相似度评估方法也没有定论,向量数据库能提供常用的几种,比如目前最火的向量数据库 Pinecone 就只提供了欧几里德距离、余弦相似度和点积相似度。但评估相似度的方法需要根据应用场景和数据特点来定义。常用的方法还有皮尔逊相关系数、异或距离等。每一种评估方法都有不同的适用场景,对应的索引创建方法也可能不同,比如浮点数向量通常考虑用欧几里得距离或余弦相似度评估相似度,用 HNSW 算法创建索引,但二值向量可能需要用异或距离评估相似度,用 IVF 算法创建索引。相似度评估的选择直接影响向量查找的效率和准确率,所以通常需要对这些创建索引方法和相似度评估方法反复组合和调参,直到达到理想的查询效果(和创建索引时类似,有时可能还需要尝试另一种向量数据库)。
我们用关系数据库做性能测试时,通常只要随机生成足够数量的数据就可以了,最多也只是考虑字段的数据类型和取值范围。但向量计算并不行,高维向量所处的空间太大,完全随机生成的数据几乎没有任何聚集性,如果用聚类的方法来创建索引,每个类别的数量都不会很多,很难起到减少遍历量的效果,也就无法提高查找效率了。而实际的向量数据(比如指纹数据,人脸数据)通常会在高维空间中的某些位置聚集,这就很容易创建出有效的索引,从而保证查询相似向量的效率和准确率,而这些只有拿到实际数据后才能完成测试。这个现象也可以从侧面说明向量计算的个性化。
如此看来,向量数据库完全不像关系数据库那样是一个即装即用的产品,它完成任务的过程伴随了太多的个性化和实验过程,更像是一种编程实践。这样看来,向量数据库更像是一个实施项目,而不是一个直接可用的产品。
既然是在基础类库上再编程,那选择某种开发方便且有相关算法类库的程序语言都可以了,专门去采购向量数据库的必要性并不大。
SPL就是可以胜任这种功能的程序语言。
相较于向量数据库常用的宿主语言(C++、Python 等),SPL 在程序逻辑、编写程序、数据存储等方面有明显优势。只要有足够的基础类库,实现这些向量查找任务会更方便。
1. 向量计算和预处理
SPL本身提供了丰富且灵活的向量计算方法和预处理方法,可以快捷的进行向量间的运算。
比如向量的乘积:
A=[[1,2],[2,3],[3,4]]
B=[[1],[2]]
M=mul(A,B)
向量的欧式距离:
A1=10.(rand())
A2=10.(rand())
D= dis(A1, A2)
向量归一化后的余弦相似度:
C=( A1** A2).sum()
PCA降维:
A=[[1,2,3,4],[2,3,1,2],[1,1,1,-1],[1,0,-2,-6]]
A’=pca(A,2)
2. 与向量数据类型匹配的程序逻辑
当前向量数据库的基础算法通常需要宿主程序语言(C++、Python 等)来驱动,开发效率低。SPL 拥有完善的程序逻辑,与向量数据类型和基础算法融为一体,开发效率更高,而 C++ 和 Java 并没有严格意义上的向量数据类型,而且在基础算法方面也只提供了类库,这类语言在向量计算时就很难用。
3. 开发调试便捷
SPL是网格式程序语言,这使得代码十分整齐直观。每个格子计算的结果都会保存下来,在 IDE 右侧的结果面板可以查看,程序员点击某个格子就可以实时查看该步(格)的计算结果,计算正确与否一目了然(没有了其他程序的 print 大法烦恼)。SPL 还有非常方便的调试功能,包括执行、调试执行、执行到光标、单步执行,后面还有设置断点、计算当前格等功能,可以完全满足编辑调试程序的需要。下图是 SPL 的 IDE 界面:
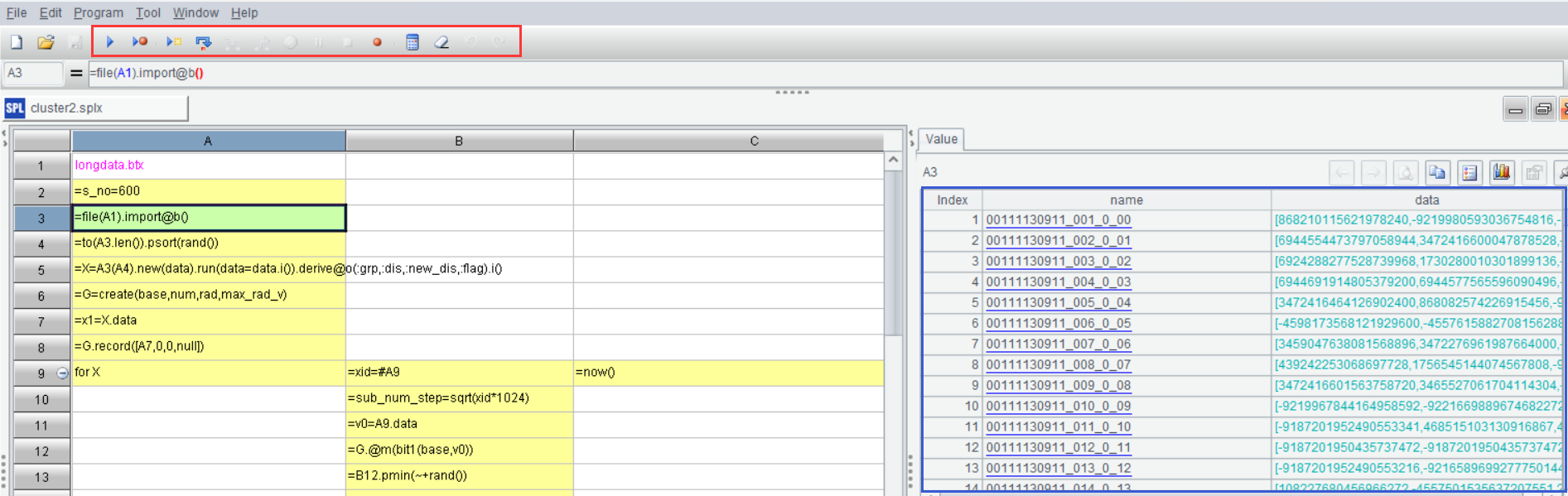
红框是 SPL 的调试功能按钮,蓝色框是结果面板,图上显示的是 A3 的结果数据。
4. 向量计算之外
相似向量查找不是单纯的一件事,通常还要有一些其他工作,比如关联其他结构化数据或者处理其他文本数据等。SPL 在这方面拥有自己独特的理解,不仅处理简单而且效率很高,这方面的内容可以参考乾学院中的相关文档。而一般向量数据库并没有这些功能,还是要借助宿主语言,有时甚至要关系数据库配合才能完成这些工作,这就太麻烦了。
5. 存储与高性能
SPL拥有完善的存储能力,可以根据个性化数据要求完成有利于高效查询的存储任务。SPL 提供了专门的二进制文件存储格式,提供了压缩、列存、有序、并行分段等机制来充分保证计算性能。这些二进制文件的存储非常灵活,可以根据任意算法来设计存储,既可以利用文件存储本身的优势,又可以根据算法调整,跑出高性能也就不奇怪了。
说起高性能,使用的语言总得方便并行吧,这一点 Python 就很难做到,因为全局解释性锁的存在,Python 的并行实际上是伪并行,如果非要并行恐怕只能多进程并行了,这种开销就不是多线程可比的了。而 SPL 拥有完善的并行能力,而且很多情况下在写法上和单线程类似,只是增加了 @m 选项。比如计算 100 个向量与 1 个向量的欧式距离。
A |
|
1 |
=100.(10.(rand())) |
2 |
=10.(rand()) |
3 |
=A1.(dis(~,A2)) |
4 |
=A1.@m(dis(~,A2)) |
其中 A3 是单线程写法,A4 是多线程写法,两者的写法只差 @m,但计算效率提高了数倍。
《SPL实践:高维二值向量查找》(以下简称《实践》)是我们最近刚用 SPL 做的一个关于相似向量查找的案例。从本次实践中不难看出高维向量查找的个性化程度非常高,首先是聚类方法的选择上就是个难题,常用的 k-means 算法需要确定参数 k,在本例中,这个参数无法确定;在聚类过程中还有质心移动的过程,而二值向量的质心不容易定义。为了创建更有效的索引,我们只能为本例数据定制个性化的聚类算法——拆分式聚类和逐步聚类。其次是相似度评估方法的选择上,业界最常用的是余弦相似度,但对于本例中的二值向量,余弦相似度会违背人的直观感受,比如当 1 很多时,如果只有少量维度不同,算出的 cos 相似度会很大;当 0 很多时,还是少量维度不同时,算出的 cos 相似度会小很多。所以我们选择用异或距离来评估相似度,这样算出的相似度更符合人的直观感受,随之还带来另一个好处,那就是异或距离的计算量更小。
整个实践过程完美实践了 SPL 编程的便捷性,在基础算法方面,SPL 提供了 bits()函数,将二值序列转换成按位存储的长整型 (long),正是这一步使得计算变成了按位运算,大幅提高了运算效率(包括创建索引和向量比对过程);用 bit1() 函数计算两个向量的异或距离,进一步提升了计算效率。
除了这些基础算法外,SPL 还轻松的完成了的两种聚类方法——拆分式聚类和逐步聚类,两种聚类算法的逻辑还比较复杂,SPL 中的核心代码都只用了十几个代码格,如果用 C++ 或者 Java 来完成,恐怕没有几百上千行代码搞不定吧
在高性能方面,本次实践中使用了 SPL 提供的高效计算方法,比如 group@n(),其中的 @n 选项是按序号分组,比普通的哈希分组快了很多。其实 SPL 还有很多其他的高效算法,比如二分法、有序计算等,而且使用起来也很方便,一般只需要增加 @b 或 @o 选项即可。
在并行方面,聚类过程中有不少地方用到了并行,SPL 只要在普通函数中增加 @m 选项就可以实现并行(比如 group@nm()),充分利用了多核 CPU 的计算资源。而 Python 在这方面是有欠缺的,所以它也没有想象中的那么好用。
虽然实践中没有涉及大数据的内容,但其实即使是大数据运算,SPL 也不在话下,它拥有完善的游标机制,结合高效的存储方案,可以轻松写出高效的向量计算程序。
通过此次实践过程,最直观的感受就是相似向量的查找过程并没有那么简单,通常不是向量数据库提供的那些算法 API 排列组合后能完成的(其实即使是对 API 的排列组合也需要相当的统计学和数学知识,并且经过反复试验后才能实现),这种情况下,使用 SPL 来完成可能是更好的选择。
在部署时,一般的向量数据库通常很重,部署、调试和维护都很复杂,有些还必须在云上使用,但很多场景的数据因为安全原因是不能上云的。而 SPL 很轻,无论是部署、调试和维护都更简单,甚至可以嵌入应用程序中,任何地方都可以拥有向量计算能力。
SPL目前在聚类算法的完备度上还不够丰富,但随着 SPL 不断补充这些基础算法,SPL 将会比现有的向量数据库更向量数据库。


英文版