

file 函数使用 chardetect 判断出的编码作为参数,读取文件后仍然乱码!
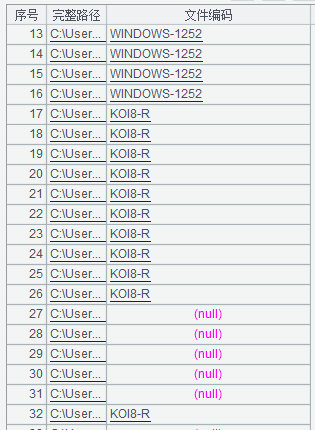
1. 为什么 chardetect 识别出的编码很奇怪?我原始文件只有两种编码:GBK 和 utf8. 它判断出来的 KO 是什么?另外,那些 null 是怎么回事?
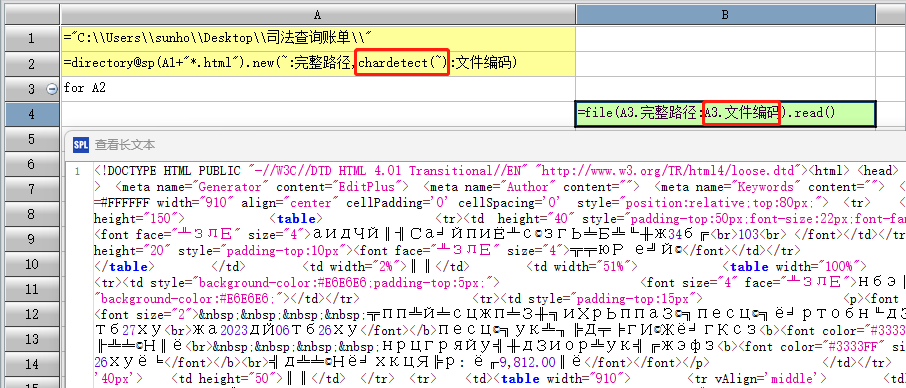
2. 我用它判断出的编码,作为 file 函数的参数,为什么仍然无法正确读取文件?
3. 另外,那个 charencode 函数是干嘛用的?不理解


"1. 为什么 chardetect 识别出的编码很奇怪?我原始文件只有两种编码:GBK 和 utf8. 它判断出来的 KO 是什么?另外,那些 null 是怎么回事? 2. 我用它判断出的编码 .."
1. 为什么 chardetect 识别出的编码很奇怪?我原始文件只有两种编码:GBK 和 utf8. 它判断出来的 KO 是什么?另外,那些 null 是怎么回事?
2. 我用它判断出的编码,作为 file 函数的参数,为什么仍然无法正确读取文件?
3. 另外,那个 charencode 函数是干嘛用的?不理解


从图示上看并没有检测错,因为文件里所有字节都在 KOI8-R 编码里找到了对应的字符,只不过从语义上看不正确
1、文件内容可能在多种编码下都正确,所以 chatdetect 应该要检测出多个编码
2、多个编码时可能要定义一个优先级,如果只想返回一个的话
大佬,早! 谢谢关注此帖!
这个问题在 @oradt 的帮助下已经解决了 (就目前已知的编码信息)。
chardetect 涉及到概率统计和优选,以后碰到了问题再向大佬求助。
谢谢大佬们的帮助🙏