


Excel 文件 xlsx 格式的游标问题
Excel 的 xlsx 文件可以用游标读取,但在 IDE 里和 excel 插件里使用时,都存在一点小问题。我总结了三种用法,希望 SPL 大佬们帮忙看一下,问题出在哪里。且不管这些写法的实战意义,纯粹是为了学习过程中的解惑。场景如下,SPL 主目录下有一个简单的 test.xlsx 文件,只有两列 51 行,第一列的列名叫类型,值是整数 1 到 51,第二列的列名和对应的值随意。先用游标的方式读取,然后,根据类型用游标的方式分成 6 组,分别是 1-10 一组,11-20 一组,21-30,31-40,41-40,51,最后用索引为文件名输出成 csv 格式至主目录下。
第一种方法:游标分组 cursor.group@i
IDE 里的写法如下:
| A | |
| 1 | =file("test.xlsx").xlsimport@ct() |
| 2 | //=A1.group@i(类型 %10==1).fetch() |
| 3 | =A1.group@i(类型 %10==1).(file(#/".csv").export@ct(~)) |
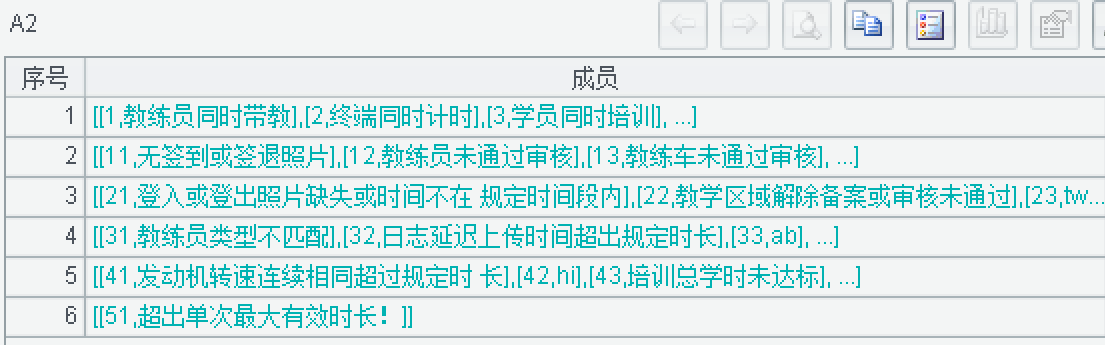
A3 在执行时已经注释了 A2,但输出结果时没有成功,主目录下并没有生成对应的 6 个 csv 文件。
如果把这 3 句语句复制粘贴至 excel 插件中去执行,情况正好相反,A2 中的语句在 excel 中显示为空,但 A3 只能输出 5 个对应的 csv 文件,少了第一组文件,文件内容被最后一组的内容给覆盖了。如果用 skip 函数去统计行数时,第一个文件的行数显示的是最后一个文件的行数,这是游标到了最后又游回到了开始的地方,继续执行?这有点迷惑。
第二种方法: 自定义区间段,用游标分段读取
IDE 里的写法如下:
| A | B | |
| 1 | ["1:10","12:20","22:30","32:40","42:50","52:"] | |
| 2 | for A1 | =file("test.xlsx").xlsimport@c(;,${A2}) |
| 3 | =file(#A2/".csv").export@ct(B2) |
第一,上一个区间的结尾跟下一个区间的开始处,要隔开 2,才能正常地连续,比如 1-10,12-20…。如果只相隔 1,就会有重复,比如 1-10,11-20,那第 10 条记录会出现两次;
第二,这种方法读取的时候不能带表头,带表头 xlsimport@tc 时,第一组是正常的,从第二组开始没有正常的表头,第一行变成了表头。
这种方法在 excel 插件里使用时也是同样的问题。另外,用 fork 并行,也用这个方法分段游标获取时,跟上述方法存在同样的问题。问题会不会是因为 xlsimport@c(;, 分段) 这个方法有问题?
第三个方法: 循环游标,固定长度。这个方法没有问题,无论是表头还是连续程度都无问题。
IDE 里的写法如下:
| A | B | |
| 1 | =file("test.xlsx").xlsimport@ct() | |
| 2 | for A1,10 | =file(#A2/".csv").export@ct(A2) |
这个方法在 excel 插件里使用也能获取正确的分组结果。


游标只能执行一次,A2 把游标遍历完了,A3 已经取不出数了,要重新定义游标
大佬,早!
A2 我上边特地写了,只是为了展示分组的结果,跟在 EXCEL 插件里做一个对比。
因为在 excel 插件里执行 A2 时,显示为空,或者显示成一行奇怪的结果。如果分组很少,比如 3 组,又能显示出结果来。
实际上,A3 在执行的时候,A2 是注释掉的。问题一样存在。应该不是游标一次性的问题。
你有空的时候,模拟 51 行数据,帮忙测试一下。谢谢!
A3 后面要加个.skip(),现在写法是延迟游标,只定义游标,什么事都不干。
大佬,skip 加了, 结果是 6, 这个没错。问题是想要生成 6 个 csv 文件,只生成了 5 个,有一个被覆盖了。
只生成了 5 个文件:
测试文件在这里。文章里的 SPL 语句复制即可用:
testxlsx
游标里不要用 #,每次读的时候会重新计数。这里要自己算。写成 file((B1+=1)/ … )
感谢大佬指点。游标分组 cursor.group@i 后输出的问题解决了。
IDE 里要这样写,一个是游标里不能用 #,再一个是后面要跟.skip()。但在 excel 插件里使用时,可以不用跟.skip()
还有另一个问题,是在 EXCEL 插件里的这种写法,分组结果有时能显示,有时又没有。
比如,分成 3 个一组或者 17 个一组,能显示结果,因为 51 行除以 3 或者 17 能整除:
如果是任何不能整除的情况一组,就不会出结果:
关于方法二中的第一个问题 ,读取区间有问题,程序已更新,您可以去 (下载贴) 中下载 esproc-bin.jar.
关于方法二中的第二个问题,使用 @t 选项时,当表达式中有 b 参数时程序会认为标题是在 b 行中
谢谢大佬,jar 包我下载了,但没有测试出我想要的结果,我希望每一个输出的 csv 都有一个表头,表头是原表的第一行,每一个输出的 csv 都对应上自定义的区间,格式就是: 表头,1-10 行; 表头,11-20 行; 表头,21-30 行…表头,51 行。能不能麻烦你指点一下怎么写才正确?
用 b:e 写法是会认为表头在 b 行上,b:e 写法和游标有一定矛盾性。
只要产生一个就行了,然后 fetch(10) 写出去。试试这样:
A1 =…xlsimport@tc ()
A2 for A1,10 >file(#A2/“.csv”).export@tc(A2)
话说回来,在插件里用游标 ,虽然不算非法,但确实匪夷所恩,这已经超出了我们的想像力,有点像当年张瑞敏吐槽农民伯伯用洗衣机洗地瓜。
谢谢大佬!
for A1,10…. 循环游标这个写法是文章里提到的第三个方法,这个是完全没有问题的。
这些写法虽然 "匪夷所思",早上微信群里说是 "出神入化",哈哈,是学习过程中难免的,我也是在一点点摸索。知道你们都很忙,发这个帖子也是很慎重,想了 3 天才发,怕自己没学到位就乱发帖子。
主要是为了解惑,还有一个是想能不能把 xlsx 格式的文档处理速度提升上来。因为平时接触到的文件都是以 excel 文档为主,如果能依靠 SPL 有效率地处理这些文档也是一件挺有意义的事,对工作很有助益。现在处理的数据量,只能说是数据有点多,二三十万行的 excel 文档,当然多的也有五六十万行的。SPL 对 xlsx 格式不是很友好,当然也不仅仅是 SPL,Pandas,PowerQuery 等碰到几十万行的 excel 文档处理起来也很费劲。大佬得闲时能不能指点一下如何提升处理 xlsx 的速度?不要转格式 (比如转成 csv,txt 或者 ctx)。我周边很多朋友有这方面的需求。
关于 "洗衣机洗地瓜", 很希望 SPL 也能做到 "无所不洗"。
有一种方法管用就行了。
XLS 格式复杂,没有谁(包括 Excel 自己)能高速处理,这是微软自己都没法解决的事情,我们作为外人当然更没有可能。这是个理论性问题。
如果能抛开格式,只是这种行式数据处理,大数据时不要用 XLS,用 csv 要高效得多,用 SPL 的 btx 速度更快。
这种行式数据的交互计算,可以尝试一下桌面版中的工具:http://www.raqsoft.com/SPL-WIN#part5
不过这个小工具目前还不是 SPL 体系的重点,花的工夫不多,有可能测出一些错误或使用上不方便的地方,我们也会逐步完善它。
如果即要大数据量,也要复杂格式,那没有办法,只能忍着。
谢谢大佬指点!🙏 你谈话的精神基本上领会到了。
希望 SPL 越做越 special, 越来越牛 X。
推测大神用的五笔输入法