

A.fjoin/A.switch/A.join 问题
集算器的关联函数太多了,请问创造 A.fjoin 的初衷是什么?
看函数文档 http://d.raqsoft.com.cn:6999/esproc/func/fjoin.html#__2525
举的例子,似乎用 A.switch 或 A.derive 都能实现,那为什么还要新造一个函数呢?
效率高吗?
看说明似乎是逐行计算,是不是比其他关联效率低呢?

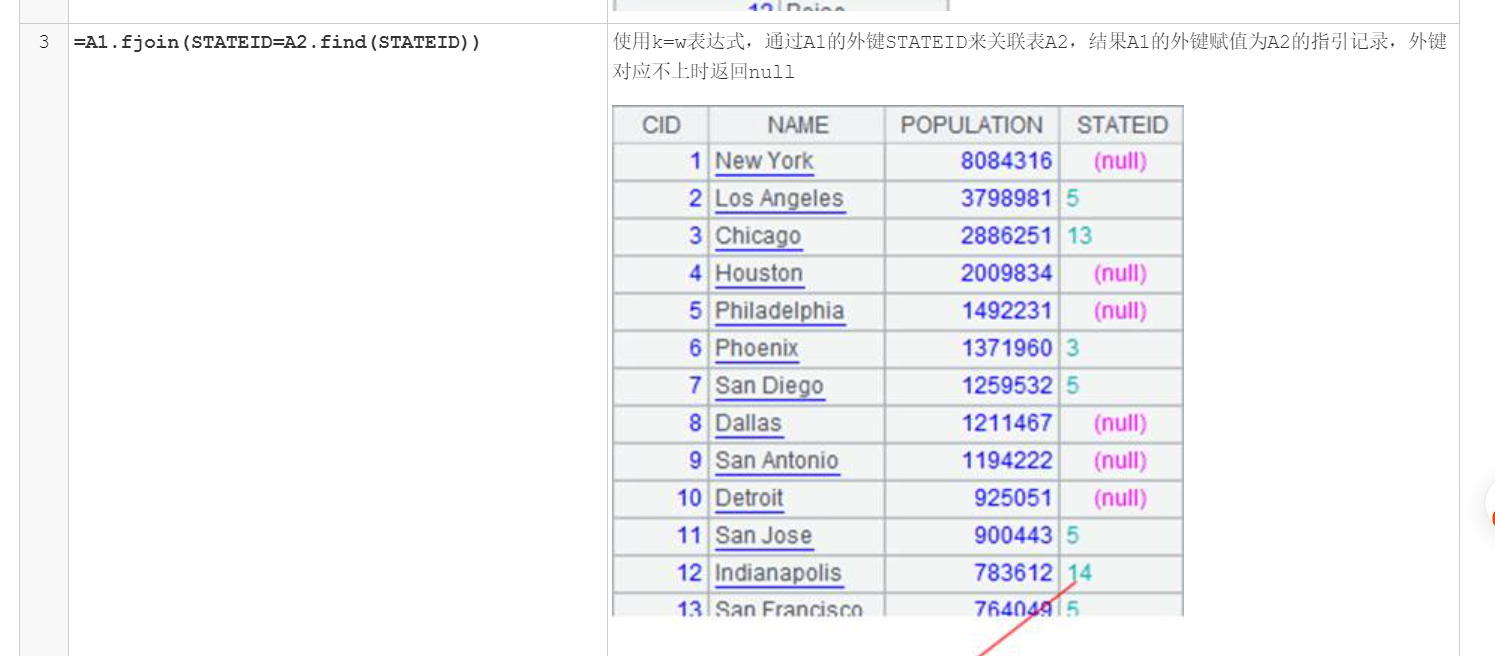

这两个可以用 switch
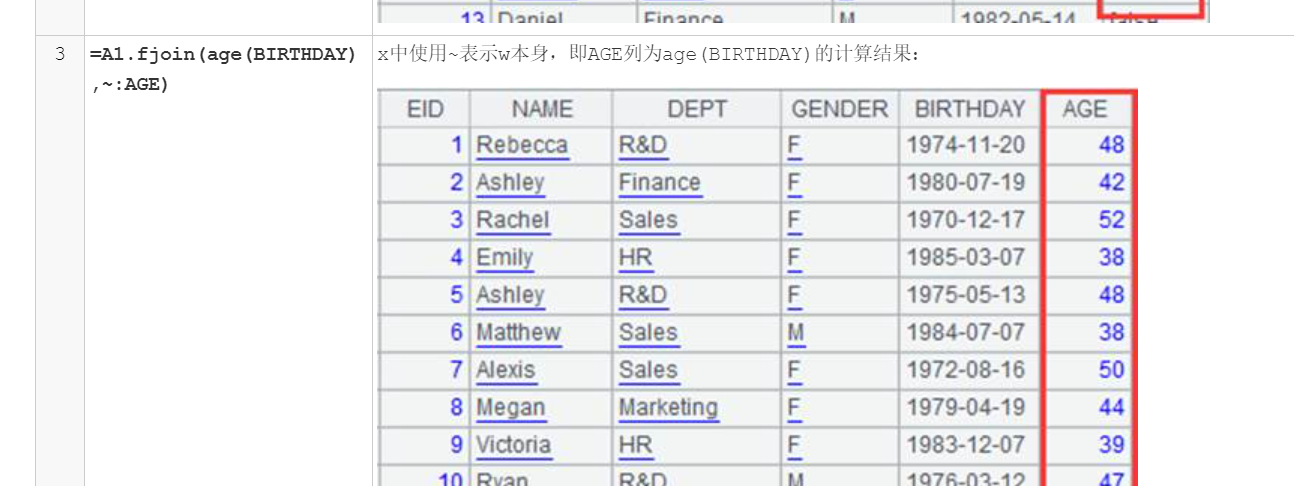
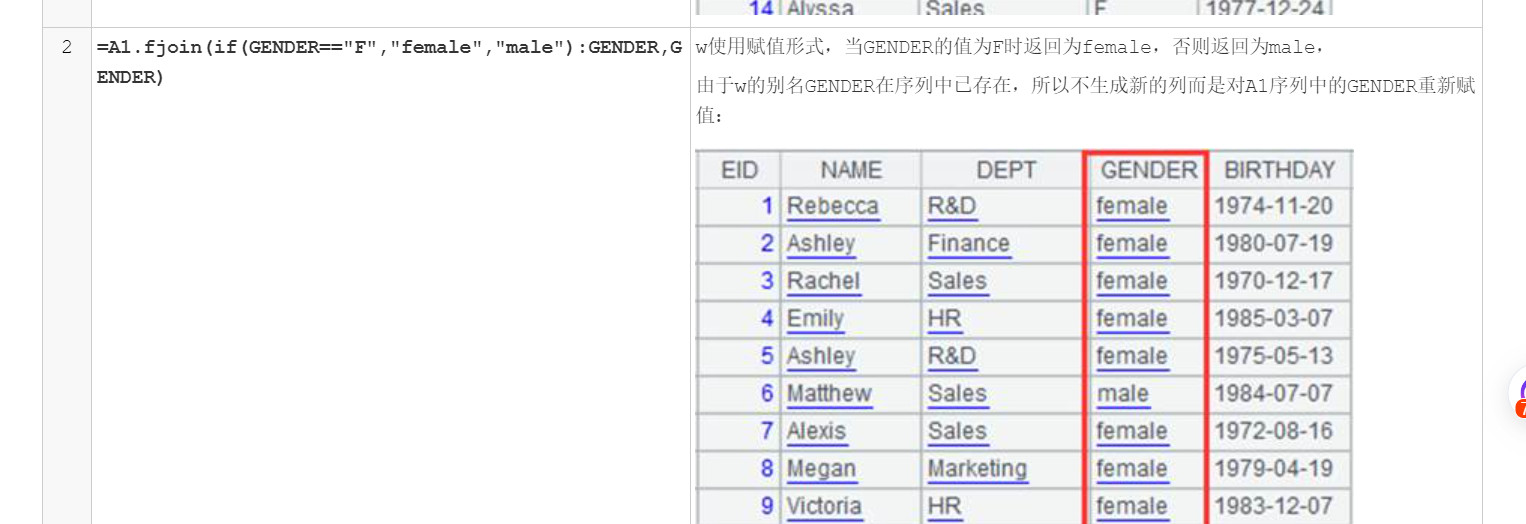
这两个可以用 derive

"集算器的关联函数太多了,请问创造 A.fjoin 的初衷是什么? 看函数文档 http://d.raqsoft.com.cn:6999/esproc/func/fjoin.html#__252 .."
集算器的关联函数太多了,请问创造 A.fjoin 的初衷是什么?
看函数文档 http://d.raqsoft.com.cn:6999/esproc/func/fjoin.html#__2525
举的例子,似乎用 A.switch 或 A.derive 都能实现,那为什么还要新造一个函数呢?
效率高吗?
看说明似乎是逐行计算,是不是比其他关联效率低呢?
这两个可以用 switch
这两个可以用 derive


switch 和 join 是标准的关联运算。switch 处理单字段外键,这时候才能转换成外键。多字段时转换不了,而且也需要不能转换的时候,就用 join。
原则上,join 一定程度会包含 switch 的功能(单字段也是多字段的特例),但 switch 这种外键对象化是非常好用,而单字段又特别常见。
至于用 derive 来实现关联,当然理论上也没问题,但写法明显复杂多了,也无助于关联概念的理解。而且写成这样,SPL 是很难优化的(SPL 的自动优化能力并不算强,但函数的优化也有不少)。在小数据时无所谓,如果面对大数据时,性能差距会非常大。
fjoin 是在实践中补充的,也是因为高性能。一律用 switch/join 时,某些优化手段实施不了。后面设计的 fjoin,其实可以取代 switch/join 的功能,但 switch/join 已经被大量使用,没办法删除了。作为概念理解,switch/join 也更简单些,初学者可以先忽略 fjoin,要碰到合适的场景时就会发现能用它减少计算量。
参考文档没办法写这么细致,只能写出它在逻辑上的作用,先保证正确性,但不太会涉及使用场景,这样看起来似乎是差不多的。
所以,乾学院上会有很多学习贴,比如前面讲的 switch 和 join 的区别,就会有专门讲关联运算的学习贴对着某些计算需求来举例。fjoin 刚出来时间不长,暂时还没有写相应的学习贴,过一阵都会补充。
SPL 的函数比较多,一下子全部掌握比较难,但并没有必要。碰到问题再来看,就很容易理解了。其中有相当一部分是为了高性能,为了再减少一些计算量。在性能还不是问题的场景下,一般也不用太关注它。碰到性能问题时,也就很容易理解再使用这些函数了。
我用 switch/join 效率要高于 fjoin, 不知为何速度差距非常大。
这跟 fjoin 的写法有关,switch/join 如果维表没有建索引会自动建索引,fjoin 不会自动建索引。
如果 fjoin 里的表达式用了 find 等查找函数,需要事先在维表上建索引。
fjoin 里的关连表达式写法比较自由,可以实现多条件关连。