"[图片] 集算器版本:20230228"
集算器版本:20230228
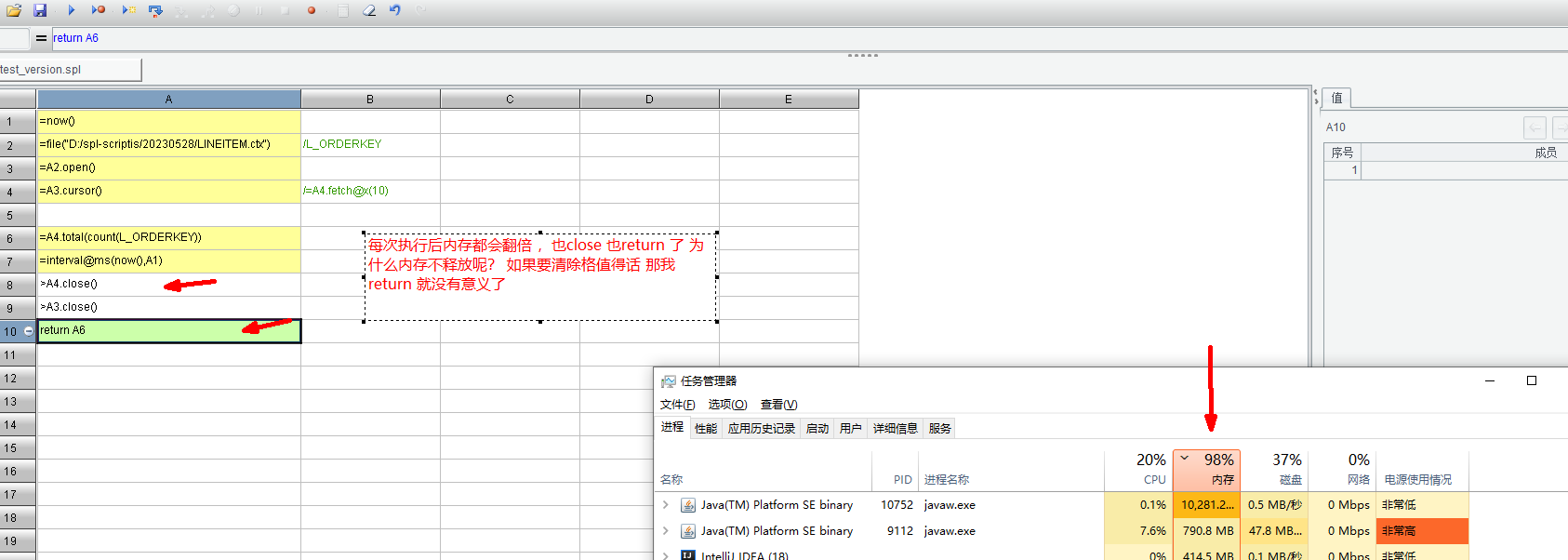
网格程序这样写没问题的。jvm 参数 -Xms、Xmx 分别配置的多少?
是 ide 里执行多次有这个现象,还是是通过 jdbc 调用出的这个现象?如果是 jdbc 的话更新下最新的 jar 包,这个问题做过修改。
ide
-Xms14664m -Xmx14664m 最大最小 都是这个 ,我这个组表有 8 百万数据 如果内存设置过小 会导致 老是频繁 gc 在 open()函数得时候 cpu 会飙升
你这个最新得 jar 是要多新?你们官网发布的新的版本 我也是测试过的 一样的问题
把 -Xms 调小,xms 是 java 初始堆大小,启动 ide 就会直接占用这个设定的内存大小。8 百万数据用游标占不了多少内存的,初始堆大小 2g 都足够了。
用任务管理器看不出 JVM 实际内存消耗,OS 看到的是 JVM 申请的内存,不是 JVM 分配给 Java 程序的内存。这个问题说过多次了。判定是不是有内存泄露,一般也就是(减少内存后)反复执行看会不会爆掉,或者用 Java 的专门工具。
而且,用游标做统计,这种不并行的情况,几百 M 内存都能轻松跑通,和数据有多少行没什么关系。如果频繁 gc,已经不正常了。 换其它场景,比如用文本文件跑是不是也会这样。
2g 是肯定 不够的 2g 太小了 第一次执行就会导致 cpu 飙升 马上就无响应了
这个就是反复执行多次就会爆掉了 ,晚点我这边有时间 会录个视频 或者把多次执行的照片上传给到你们或者你们要是有时间 可以那个 大表 多次执行 几次 一看便知 ,
难道说我这个文件有问题 这样子吧 我把文件跟脚本 都上传到我的百度网盘 上面 你们 有时间可以看看链接:https://pan.baidu.com/s/1S0SdJo9xHjrErgPQiHMNRg?pwd=zyye提取码:zyye–来自百度网盘超级会员 V3 的分享
有可能是文件问题 ,我们这个用这个文件链接:https://pan.baidu.com/s/1IuTf7JDlQEdrWIBqojX77A?pwd=uygr提取码:uygr–来自百度网盘超级会员 V3 的分享就没这个问题 ,麻烦各位大佬有时间帮忙分析分析 为啥差距这么大
好像找到问题了 我 reset 之后 文件大小缩小到 4 百多兆了 然后就很正常了 ,为啥 没 reset 之前会这么慢了 能否解释下 或者说有相关文档介绍
这个 ctx 文件的数据是怎么加进去的,是不是大量使用了 update 函数?ctx 文件包含了两个区:数据区和补区,数据区存放 append 函数传入的数据,补区存放 update 函数传入的数据。补区是为了应对少量数据的修改,这个区是全部加载在内存进行处理的。所以为了提高效率,新增的数据都应该调用 append 函数加入到 ctx 文件中,对老数据的修改才调用 update。随着修改数据的增多组表访问的速度会变慢,到达一定程度就需要调用 reset 函数重新整理一下数据以提高访问效率。
有 update 但也是少量 没有说大量的 update有没有什么函数 去查看 当前这个组表文件 数据区 跟补区的大小呢?
目前没有方法,从现象上来看就是补区记录数太多导致的





网格程序这样写没问题的。
jvm 参数 -Xms、Xmx 分别配置的多少?
是 ide 里执行多次有这个现象,还是是通过 jdbc 调用出的这个现象?
如果是 jdbc 的话更新下最新的 jar 包,这个问题做过修改。
ide
-Xms14664m -Xmx14664m 最大最小 都是这个 ,我这个组表有 8 百万数据 如果内存设置过小 会导致 老是频繁 gc 在 open()函数得时候 cpu 会飙升
你这个最新得 jar 是要多新?你们官网发布的新的版本 我也是测试过的 一样的问题
把 -Xms 调小,xms 是 java 初始堆大小,启动 ide 就会直接占用这个设定的内存大小。
8 百万数据用游标占不了多少内存的,初始堆大小 2g 都足够了。
用任务管理器看不出 JVM 实际内存消耗,OS 看到的是 JVM 申请的内存,不是 JVM 分配给 Java 程序的内存。这个问题说过多次了。
判定是不是有内存泄露,一般也就是(减少内存后)反复执行看会不会爆掉,或者用 Java 的专门工具。
而且,用游标做统计,这种不并行的情况,几百 M 内存都能轻松跑通,和数据有多少行没什么关系。如果频繁 gc,已经不正常了。 换其它场景,比如用文本文件跑是不是也会这样。
2g 是肯定 不够的 2g 太小了 第一次执行就会导致 cpu 飙升 马上就无响应了
这个就是反复执行多次就会爆掉了 ,晚点我这边有时间 会录个视频 或者把多次执行的照片上传给到你们
或者你们要是有时间 可以那个 大表 多次执行 几次 一看便知 ,
难道说我这个文件有问题 这样子吧 我把文件跟脚本 都上传到我的百度网盘 上面 你们 有时间可以看看
链接:https://pan.baidu.com/s/1S0SdJo9xHjrErgPQiHMNRg?pwd=zyye
提取码:zyye
–来自百度网盘超级会员 V3 的分享
有可能是文件问题 ,我们这个用这个文件
链接:https://pan.baidu.com/s/1IuTf7JDlQEdrWIBqojX77A?pwd=uygr
提取码:uygr
–来自百度网盘超级会员 V3 的分享
就没这个问题 ,麻烦各位大佬有时间帮忙分析分析 为啥差距这么大
好像找到问题了 我 reset 之后 文件大小缩小到 4 百多兆了 然后就很正常了 ,为啥 没 reset 之前会这么慢了 能否解释下 或者说有相关文档介绍
这个 ctx 文件的数据是怎么加进去的,是不是大量使用了 update 函数?
ctx 文件包含了两个区:数据区和补区,数据区存放 append 函数传入的数据,补区存放 update 函数传入的数据。
补区是为了应对少量数据的修改,这个区是全部加载在内存进行处理的。
所以为了提高效率,新增的数据都应该调用 append 函数加入到 ctx 文件中,对老数据的修改才调用 update。
随着修改数据的增多组表访问的速度会变慢,到达一定程度就需要调用 reset 函数重新整理一下数据以提高访问效率。
有 update 但也是少量 没有说大量的 update
有没有什么函数 去查看 当前这个组表文件 数据区 跟补区的大小呢?
目前没有方法,从现象上来看就是补区记录数太多导致的