

使用报表组侦听类时 IGroupEngine 取的 IReport 为空
在报表组的侦听类中 afterCalc(Context arg0, ReportGroup arg1, IGroupEngine arg2) 方法内,通过 IReport iReport = arg2.getReport(0); 取得 iReport 对象为空。如下图所示:
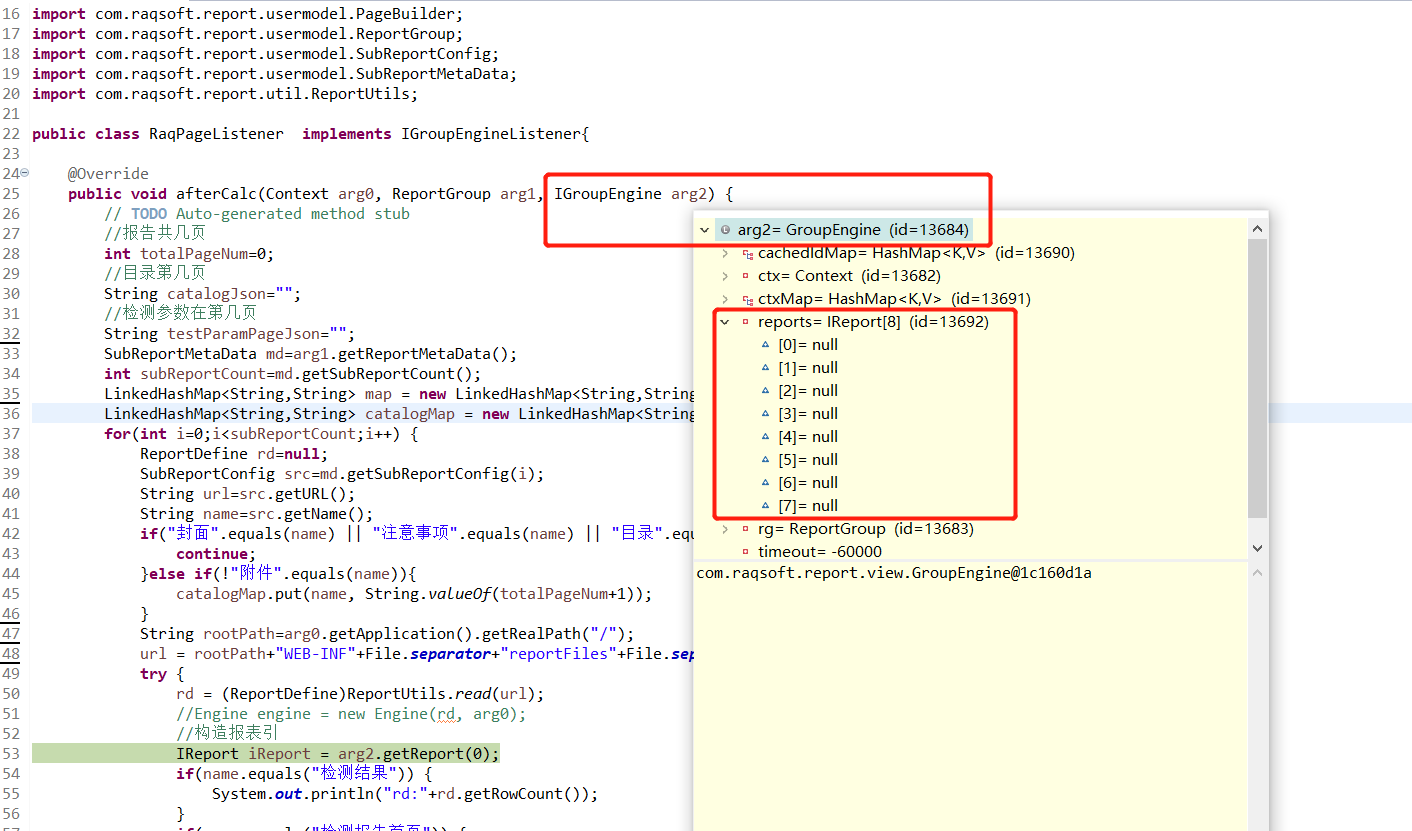
我想取得报表组中某个报表的内容,即 IReport 对象的内容。
谢谢。

"在报表组的侦听类中 afterCalc(Context arg0, ReportGroup arg1, IGroupEngine arg2) 方法内,通过 IReport iReport = .."
在报表组的侦听类中 afterCalc(Context arg0, ReportGroup arg1, IGroupEngine arg2) 方法内,通过 IReport iReport = arg2.getReport(0); 取得 iReport 对象为空。如下图所示:
我想取得报表组中某个报表的内容,即 IReport 对象的内容。
谢谢。


侦听器的 afterCalc,实际的执行时间是在初始参数计算完成后,各个子报表项计算之前执行的,只有这个时候才能通过设置参数等操作之类影响计算结果。而在报表计算完成后,计算结果目前是不能改变的。
谢谢,因为我在这个方法内已经把子报表都计算好了,然后想进行内容替换。能不能让报表组不进行子报表后续计算,这样可以避免二次数据加载计算和覆盖已经替换好的内容。
目前二次数据从数据库获取和计算感觉很耗费时间 。
主要想要提升这块的效率,看您这边有合适的办法吗?
这种需求用报表组的侦听目前是不可以的,报表组的计算机制中只能通过设置参数调整,而不能改变计算后的结果。如果需要改变子报表的结果,只能是在子报表的侦听或者子报表的分页侦听中处理,当然这样也不能在各个子报表项中关联处理。
针对我们这样的需求,您建议怎么处理比较好?
把目标的报表和计算逻辑贴出来看看。如果是读数和计算导致的性能问题,通常可以在数据准备阶段处理好,而不要在报表中再计算,报表只管填数。
实现逻辑上图,通过计算子表的内容后取得子报表的内容和页数。请问具体应该怎么优化和提升效率?
这代码里没有如何读数据库和计算的逻辑。
要看目标报表本身及其和数据源的关系,然后看看是不是可以完全换一种办法来生成,不是要看怎么算子表,算子表的路线下面的讨论已经说明搞不通了。
前面说是希望减少读数和计算成本,那可以想办法在数据准备环节来优化。如果是因为摆布局的性能差,那数据源环节帮不上忙。
您说的 "要看目标报表本身及其和数据源的关系", 是指报表的数据源类型吗?报表的数据源类型都是 sql 检索
从这些对话上看,你试图自己算子报表,是为了解决子报表重复计数和计算导致慢的问题。
那么慢在哪里呢?读了什么多少数?要花多少时间,做了什么计算,花多少时间?如果有办法让这个读数和计算变快是不是就能 ( 不再自己计算子报表而)解决问题了?
您好,我大体讲一下我们的使用场景:
1、我们的一份报告假设有两个部分组成,一个是目录,一个是内容页,目录每行的页码对应内容页所在的页码。
2、此报告模板我们采用了报表组的开发形式,报表组内包含两个报表文件,分别是目录.rpx 和内容.rpx
目前按照润乾提供的目录制作方式,涉及到从内容.rpx 报表生成的内容中获取页码,故涉及到子报表的重复计算,不知道我们这样的使用场景,是否有更好的解决办法,重复的计算导致时间加倍,用户的体验比较差。
要看看报表是怎么算的啊,才知道有没可能不重复算,或者不用子报表是不是能做出来?
一直在问这个,光定性地说是搞不清的,虽然看到了也不见得就能搞得定,但看不到肯定是搞不定啊。
从需求来看,目录页放在前面,但是它需要后面各个子报表的分页情况。问题的难点实际就是第一个目录页的生成,它需要后面各个子报表完成分页才可以处理。对于一个报表组而言,这不是一个常规性的需求。如果用目前能够实现的方式去处理,各个子报表的两次计算是不能避免的,可以放在报表组的侦听里面去做,把子报表的分页结果通过参数传递给首个目录表。这个分页的情况,也不一定需要真实去执行分页,也可能可以在目录表里,根据各个子报表数据量情况去估算,这样的话相关数据集的查询会执行两次,计算目录表时可能只需要查询个 count 的结果。
如果用后面那个方式,在目录表中去计算,是可以避免子表的两次计算以及分页处理的,甚至都不需要侦听类去传递分页情况。但是由于此时子表页数是根据数据库查询预估的,预估会比较复杂也可能不准确,特别是在数据中存在文本数量不定的时候,占行变化很大的情况下。
原始需求:
客户需要生成一个实验检测报告,报告内容包括封面页、目录页和多个检测项目结果页,有三个具体要求,如下:
1、封面页、目录页各有不低于 5 个的呈现形式,用户每次出具报告会根据要求选择用哪个封面、哪个目录和检测项目结果页组合出具一份完整的报告出来。
2、检测项目结果页一般会有多个检测项目,且有顺序显示的要求,每个检测项目的展现方式不一样,比如心电图项目的结果展现是心电图图片,身高项目的结果展现是表格,身体过敏反应项目的结果展示是一段文字描述。根据用户目前的梳理情况,该医院所有检测项目大概 4000+,但归纳起来大概只有 10 种呈现形式,用户希望根据每个人的体检项目不同,能将检测结果页按照检测项目的顺序及展现形式,自动组合出来报告。
3、目录页每行的页码对应检测项目结果页对应位置的页码。
目前的实现方式是:
第 1 个需求,我们采用了将所有的封面页展现形式和目录页展现形式做成独立的报表,用报表组提前组合好这些独立的报表,这样既方便单个报表的整改,又满足了用户组合的需求。—我们该项已完成。
第 2 个需求,我们采用了动态子报表的方式,即将每个检测项目的展现形式做成独立的报表,根据检测项目的顺序,采用程序代码的方式动态加载这些报表。
第 3 个需求,我们采用了润乾论坛推荐的目录制作方式,根据内容定位返回对应的页码进行目录显示,附地址:https://www.cnblogs.com/shiGuangShiYi/p/12112617.html
目前遇到的问题:
第 1 个需求:我们已经完成,无问题;
第 2 个需求:我们已经完成,但是存在一个问题一直未解决,即独立的报表如果设置了分组表头,目的是当数据超过 1 页的时候,第 2 页也显示表头,但是当采用动态子报表后,分组表头即使设置了也无效,第 2 页不会出现表头,用户希望第 2 页也出现表头;
第 3 个需求:我们已经完成,但是发现只要用到目录(目录是采用侦听类的方式实现),报表组每次都进行了两次计算,导致效率比较低,时间比较长。
目录页获取页码的话,需要把报表项都计算一遍才可以知道页码,然后知道页码后再写入目录页那个报表,从而生成完整报告(已经写代码实现且跑通了)。这样就会导致计算两遍才可以,性能就会比较低,用户体验很差,附地址:https://www.cnblogs.com/shiGuangShiYi/p/12112617.html
希望得到的答复:
报表组实现方式是否有可优化空间?有的话,如何优化?
如果有其他方案可以实现此需求,请不吝赐教。
报表组本身的展示和使用,都是有规范流程的。侦听类参与的环节就是在报表组执行计算之前通过改变参数影响结果。所以它执行的计算过程是没有办法被复用的,后期报表组执行计算时所使用的只有上下文以及报表组中的报表定义,而报表组计算时,并不会执行分页。也就是说使用报表组时,它在 ide 端浏览或者 web 端展示时,每个子报表都是占 1 页的,只有在导出时才会执行分页处理。如果不使用报表组的流程,那等于就需要用自定义的代码去执行计算生成分页结果了,那后续的处理也需要去另行处理,如页面端需要的展示以及缓存、或者导出处理等等。
从需求看,如果是实验检测报告,那子报表的形式通常是不太可控的,想预估子报表会占几页难度通常会比较大,特别是所有检测项目超过 4000 的情况下,各项报告恐怕是没法根据数据去估算占几页的,这种情况下,目录页只能在各个子报表分页处理完成后才能获得需要的信息。
问题描述中,组头无法呈现的情况似乎有些怪,即使使用报表组,它的各个子报表项的分页也是分别处理的,分页时表头和组头的重复按说不应该有问题。
另外,应该考虑用户需要的结果到底是什么,是导出的文件还是在线浏览。作为报表组,它在线浏览时,每个子报表应该都是不分页的,会在一个页面里展示,只有导出时才会根据每个子报表的分页设置去分页呈现,前面提到的组头的展示也只有在导出分页时才能看到效果。如果需要在线浏览,按说目录里不需要页码了,直接在报表组里切换页面就是了。
如果是需要导出文件,特别是 word 文件,那分页处理都是在导出时才会执行的,一般情况下并不会需要分页页码等数据,如果需要跨表使用这样的数据,目前不会有什么好办法,即使是自己修改代码去处理报表组的导出,也无法避免分页的计算,只可能避免各个子报表项的重复计算。
这个需求没办法在数据源层面解决,优化数据源最多是能减少子报表重复数据读入,但计算和分布还是要重复。链接中引用的例子也会重复分页,只是分页可能很快而感觉不到了。
如果是用目前模式化的流程,那由于目录页是需要其它页面的分页信息的,那其它页面的计算和分页的预算是没法避免的。如果是用自行调用报表 API 的方式,用代码处理,则有两种实现方式:
①根据报表组的情况,用 API 代码生成一个整体报表定义,用代码把封面、目录、结果等各页中的报表定义复制进去,并做必要的行数调整,而目录的设置放在分页侦听类中最好,也就是在 IPagerListener 中的 afterPage 去修改 PageBuilder 中的页面,但是要注意在 web 端使用的话在使用缓存时有可能无法修改。要不然就是用 p/12112617.html 中那个方法,在报表侦听类中处理,这个方法的问题是分页会重复执行。
②用 API 代码处理报表组的导出处理,在报表组导出时去生成目录的页码。此时报表组中的各个报表项已经计算完成,但是未做分页,这种方法能够避免报表项的重复计算,但是生成目录页码时仍然需要预算分页结果,也就是说分页部分仍然需要重复执行,只能部分提升性能。
1、4000+ 检测项目指的是医院的所有检测项目,一次人员的体检,通常会从这 4000+ 检测项目中选择部分检测项目,而非全部,通常不超过 100 个检测项目,即一次报告所包含的检测项目不超过 100 个检测项目。
2、关于您提到组头问题,之前跟您这边的技术沟通过,答复的情况当使用报表组时,分组表头即使设置了,也会自动失效。
3、关于您提到的用户需要的结果到底是什么? 用户需要先在网页上进行预览,大体看一下内容和格式,网页预览时,目录里面没有页码也是可以的,但最后用户需要一个 word 或 pdf 的报告文件,这个是需要有页码的。
粗想一下,有没有可能既然重复计算无法避免,那能不能采用类似集算器一次把数据组织好(我感觉跟数据库的 sql 交互时间是比较长的,重复计算的时间应该不是很长),类似内建数据一样,重复的计算基于集算器,是不是效率可以提升一些。
另外我上面提到的第 2 点,用户的迫切度,非常高,从去年一直在提到现在,一直还没解决,非常希望润乾能协助解决一下,非常感谢。
关于您提的这个方案,我们研发大体看了一下,没太明白,看是否方便组一个腾讯会议,我们做一个沟通,争取一次性解决掉。
我们项目对应的客户经理是沙工,看您这边什么时间方便跟沙工说一下,我们时间都比较方便,非常感谢。