


SPL 的宏
除了常见的静态代码外,有时候也需要用动态代码解决问题,比如根据参数生成代码(或一部分)并动态执行。对于缺乏动态代码机制的程序语言,通常要将代码的可变部分写成字符串形式,比如Python中的引用数据集字段名时都要写成字符串,这样才能实现动态代码的效果,但会导致更常见的静态代码的阅读和书写都不方便。而SQL则可以直接在代码中书写字段名(以及过滤条件、分组表达式等),不必写进字符串中,这样更方便阅读和书写静态代码,但却很难处理动态代码。
SPL在静态代码中延用SQL的风格,可以直接书写代码的部分,比如字段名就直接写在语句中,不必写成字符串。SPL另外提供了宏来实现动态代码的效果。
例 1:根据参数 pSortList 对订单表进行动态排序,pSortList 含有数量不定的排序字段并以逗号分隔。
用 SPL 的宏可以实现这种动态代码:T("Orders.txt").sort(${pSortList})
格式:${返回字段串的计算表达式,可以用变量或常量}
SPL 引擎在解析语句时,先检查是否含有宏,如果有宏,则将宏内的表达式计算出来拼到原语句中,形成一个新的语句再来执行。
更多例子
例 2:根据参数 pFields 里的多个维度字段(及计算列),对事实表 OrdersFact.csv 进行动态分组,并对 Amount 字段进行求和。pFields 形如"year(OrderDate),Product,Client"。
SPL 代码:T("d:/OrdersFact.csv").groups(${pFields};sum(Amount))
例 3:根据参数 pConditon 里的条件,对订单表 Orders.xls 进行动态查询,选出符合条件的订单记录。pCondition 形如:year(OrderDate)==2009 && Amount>1000 && Amount<3000
SPL 代码:T("d:/Orders.xls").select(${pCondition})
例 4:先根据起止日期参数过滤事实表 OrdersFact.csv,再根据维度参数 pGroup 进行动态分组,按月份横向转置并统计每个月的金额。如果 pGroup="Product",计算结果应当像下面:
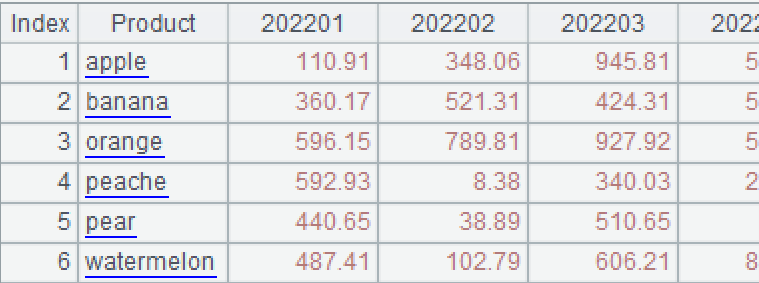
如果 pGroup="Area",计算结果应当像下面:
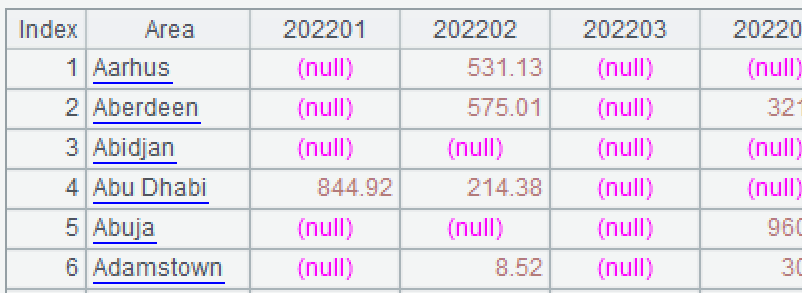
SPL 代码:
A |
|
1 |
=T("d:/OrdersFact.csv") |
2 |
=A1.select(OrderDate>=pBegin && OrderDate<=pEnd) |
3 |
=A2.pivot(${pGroup};year(OrderDate)*100+month(OrderDate),Amount) |
宏的其他用法
有时候需要重复生成形式类似的代码,虽然难度不高,但枯燥费力,这种情况也适合用宏来解决。
例 5:某文件记录了许多设备各时间点的电压,从第 2 列开始理论上都是浮点值,但实际存在带引号的脏数据,需要把这些脏数据转换成正常的浮点。部分数据:
point |
N_2102 |
N_2104 |
T1_903 |
N_2203 |
… |
00:00:01 |
"221.4" |
220.3 |
224.5 |
221.0 |
… |
00:00:02 |
218.0 |
217.5 |
229.8 |
233.1 |
… |
00:00:03 |
197.4 |
219.8 |
220.0 |
224.4 |
… |
00:00:04 |
207.1 |
201.8 |
230.3 |
207.3 |
… |
00:00:05 |
201.5 |
"227.0" |
224.5 |
203.4 |
… |
去掉某列的引号不难,比如第 2 列:A.run(flaot(#2):#2)。但如果字段较多,就需要写大量重复代码:A.run(float(#2):#2, float(#3):#3...),这就比较费力了。宏可以方便地生成重复代码,实现起来轻松许多。
A |
B |
|
1 |
=file("d:/2020-02-01.txt").import@tq() |
读文件,@q去掉引号 |
2 |
=to(2,A1.fname().len()) |
第 2 至第 N 个字段的序号列表 |
3 |
=A2.("float(#"/ ~/ "):#"/ ~).concat@c() |
拼成串 float(#2):#2, float(#3):#3... |
4 |
=A1.run(${A3}) |
批量转换字段 |
5 |
=file("d:/2020-02-01.txt").export@t(A1) |
写文件 |
注意事项
每个语句中出现的宏,只会在执行到这个语句时被解析替换一次,如果宏表达式在语句执行过程中还在变化,则不会再重新解析替换了,这和语句中的变量不同。
例 6:用另一种方法实现例 5,即先用大循环遍历字段名,再用小循环对每个字段分别清洗一次。
A |
B |
|
1 |
=file("d:/2020-02-01.txt").import@tq() |
|
2 |
=A1.fname().to(2,) |
字段名列表 |
3 |
=A2.run(A1.run( float(${A2.~}):${A2.~})) |
|
4 |
=file("d:/2020-02-01.txt").export@t(A1) |
上面 A3 里的代码是错的,因为 A2.~ 只会被解析一次,只有第 1 个字段会被转换。
把 A3 换成下面这样就对了:
A |
B |
|
3 |
for A2 |
=A1.run(float(${A3}):${A3}) |
虽然还是在循环里,但 B3 会被多次执行到,每次都会重新解析一遍里面的宏。
如果要写成一句,并且循环中的宏表达式每次都被解析,可以用 eval 函数,把 A3 写成:A2.run(eval("A1.run(float(" / A2.~ / "):" / A2.~ / ")"))
eval 函数的性能不如宏,要谨慎使用。


多谢大佬解惑,让我对 ${} 宏有了进一步的认识。
我在 SPLEXCEL 插件中使用 ${} 宏时,碰到了一些小问题,比如,
1、在 xjoin 里使用 ${}, 用于笛卡尔积展开,当前算出结果后把 excel 关掉,过一段时间打开 excel 再去敲回车时,结果就不见了。
必须把 ${} 这部分表达式重新写一遍,回车才会出结果;
2、如以下练习,把表格中的数值拼接上各自所在列的列名,我们不追究题目本身的意义,纯粹是为了练习 ${}。
结果出来后,更改数据源表中的某一个字段名后敲回车,结果就不见了,再敲一次回车,才会出结果。
=spl(“=(t=E(?),f=t.fname().(““string(””/~/”“,"”““/~/””-000"“):”“/~).concat@c(),t.run(${f}))”,A1:D4)
更改第一个字段名后,敲回车,结果变空白:
需再敲一次回车,才会出结果。
3、如果在当前工作表的不同区域中写了多个 ${} 表达式,只要更改数据源时,不同的区域中的结果会乱串,需重新执行多次才会返回正确结果。
下图中,红色框中的两部分是用不同的 ${} 写的,修改第一个字段名后,结果就出现混乱了,上下颠倒了:
=spl(“=(t=E(?),f=t.fname().(”“"”““/~/””-"“/”“/~/”“:”“/~).concat@c(),f,t.run(${f}))”,A1:D4)
正确的结果应该如下图所示,需敲好几次回车才会返回正确结果:
以上在 EXCEL 插件中使用 ${} 的问题,望大佬得闲时测试一下,看能不能改进。
Thx in advance!