


SPL 的序号化
序号是从 1(或 0)开始依次增长的自然数,可用于数组和序列的下标、数据集和序表的行号,以及自然数字段。
SQL 对序号的支持不足,作为基础数据类型的记录集合(表)是无序的,没有天然行号,SQL 程序员也没有意识主动去利用序号解决问题,特殊情况必须使用行号时,要使用函数或伪字段临时生成,比如 row_number() 或 rownum,这样的临时行号限制很多,要掌握一定的技巧才能简单使用。Java 对序号支持的较好,但不擅长结构化数据计算,通常只有用行号进行取成员这类单一的操作,缺乏深入应用的场景。
SPL 对序号提供了全面的支持,其基础数据类型(序表)是有序的,天然带有行号。SPL 不仅提供了常规的用行号取成员的方法,还可以利用行号和自然数字段简化复杂的计算,提高低效计算的性能,进行更灵活更深入的应用。
序号的常规应用
用序号取序表成员,SPL 用括号内的序号来表示:Orders(3)
上面代码表示取序表 Orders 的第 3 个成员,写法上类似 Java,执行原理也同样是内存随机读取,区别在于 Java 的下标从 0 开始,SPL 的下标(行号)从 1 开始。
用序号取序表成员子集,SPL 用函数 m 来实现,下面是几个不同场景下的例子:
Orders.m(1,3,5) #基本用法,按行号集合取子集,即行号为 1、3、5 的成员。
Orders.m(1,3,-5) #倒数,用负号表示,即行号为 1、3,以及倒数第 5 的成员。
Orders.m(4:6) #区间,用冒号表示,即第 4 至第 6 共 3 个成员。
Orders.m(:10) #省略起始(或终止)区间,即第 1 个至第 10 个成员。
Orders.m(1,3,-5,4:6,10:) #综合应用
m 函数经过了精心设计,可用简单方便的语法实现各种场景下取子集的需求。
类似函数 m,SPL 内置了大量与序号相关的函数,可以利用序号简化复杂代码,提高开发效率。比如,取所有奇数位置的成员,虽然可以用 Orders.m(1,3,5…直到行尾) 来表示,但显然过于繁琐,这时就可以用 step 函数来简化,写作 Orders.step(2,1),表示每隔 2 个取第 1 个。与序号相关的计算函数还有 to、top、psort、pmax、pselect、swap 等,类似的序表维护函数则有 delete、insert、modify 等。
用序号分组
常规的分组通常不涉及行号,但有些特殊的场景要求序号满足一定的条件再分组,SQL 对序号支持不足,实现起来不容易;SPL 对序号提供了全面的支持,相对方便许多。
例 1:根据某班的学生名单,将学生分成多个小组进行活动,要求尽量每 3 人分一组(总人数可能不是 3 的整数倍),请给出一份新名单,列出每人所属的组号。
这道题有多种做法,基本做法是在原名单的基础上,按顺序每 3 行分一组,即 [1,2,3] 行分到第 1 组,[4,5,6]行分到第 2 组,如此依次分组。代码如下:
A |
|
1 |
=connect("myDB") |
2 |
=A1.query@x("select Name, GENDER, AGE, null as GID from students where ClassID=1") |
3 |
=A2.group((#-1)\3) |
4 |
=A3.run(~.run(GID=A3.#)) |
A2:取原名单,并新增一个空的组号字段 GID。根据具体要求,可以按某种规则排序,比如按学号,也可以随机排序。如果随机排序,可以用数据库的随机函数,写成…order by rand(),如果担心不好移植,还可以使用与数据源无关的 SPL 随机函数,写成 sort(rand())。
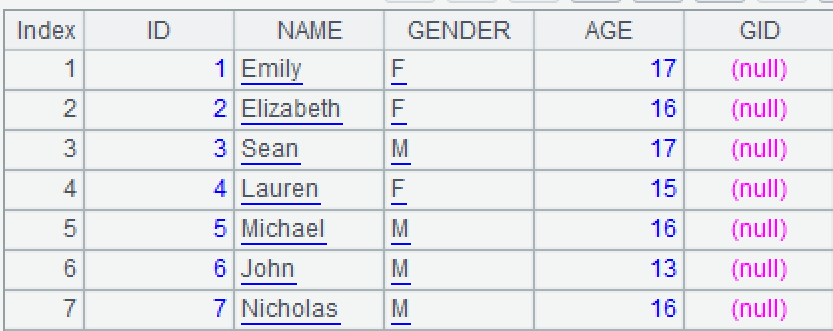
A3:用序号分组。group 是分组函数,分组键值相等的记录会分到同一组(本题分组后不必聚合),# 为行号,\ 符号表示整除后取整数部分,(#-1)\3 即 [0,0,0,1,1,1,2]。A3 计算结果如下。
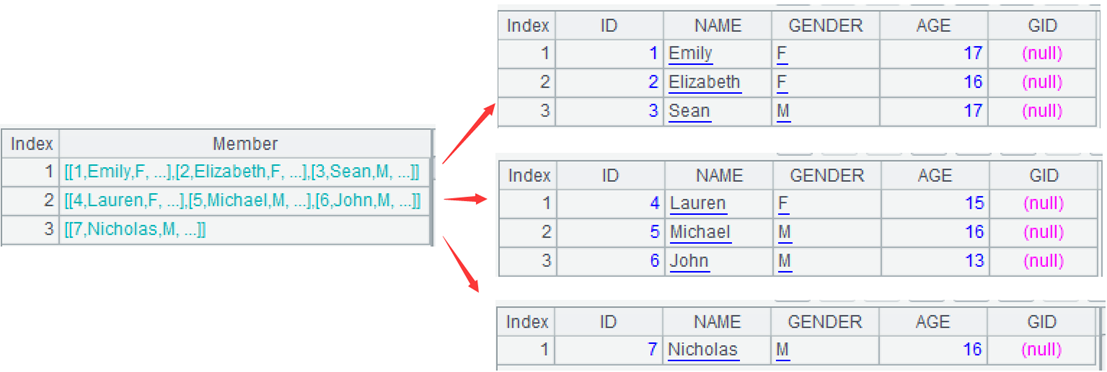
A4:修改 A3 中每一组的 GID 字段,改为 A3 的行号 #。最终结果如下。
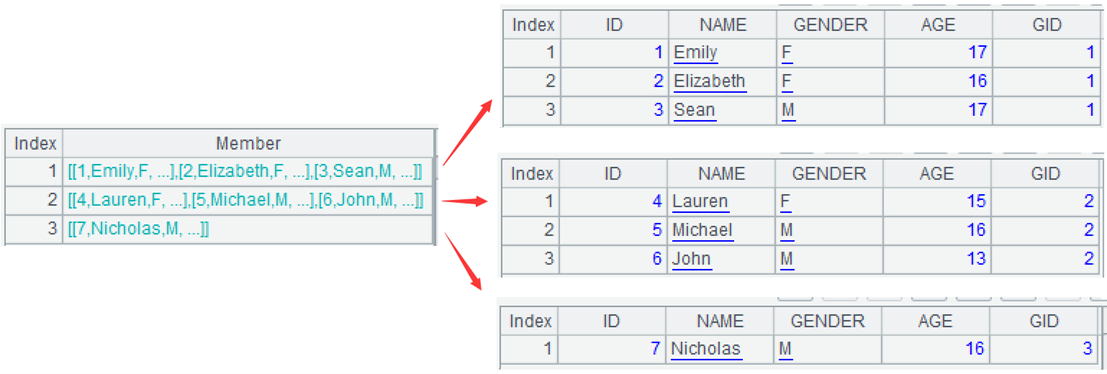
例 2:将原名单按顺序尽量均分成 3 组,即行号 [1,2,3] 为第 1 组,[4,5]为第 2 组,[6,7]为第 3 组。上个例子的限制条件是每组成员数,这个例子是总的组数,虽然逻辑区别较大,但 SPL 都容易解决。
其他代码不变,只要把 A3 改为:A2.group((#-1)*3\A2.len())。
代码中 group 的分组键值是 [0,0,0,1,1,2,2],按照 group 函数的分组规则,键值相等的记录分到同一组,比较键值可知行号[1,2,3] 为第 1 组,以此类推。
还可以利用序号换一种分法,例 3:不是将相邻记录顺序分到同一组,而是隔 3 行取一次记录分到同一组,分组键值为 [0,1,2,0,1,2,0]。
相应的代码:A2.group((#-1)%3)
根据 group 函数的分组规则可知,记录数越多,比较键值是否相等的计算量就越大, 这里有一些优化性能的技巧,讲其中一个技巧:不使用等值键值做分组依据,而是用自然数组号(从 1 开始),这样就避免了比较键值,只要把组号为 N 的记录直接分到第 N 组即可。
利用组号分组改进例 3 的性能:A2.group@n((#-1)%3+1)
@n 表示按组号直接分组,组号是 [1,2,3,1,2,3,1]。注意,例 3 之前按键值分组,键值没有数据范围的限制,可以从 0 开始;改成按组号分组,必须从 1 开始,要在原代码的基础上加 1。
同样的道理,例 1 也可以改成按组号分组,而且性能更好:A2.group@n((#-1)\3+1)
上面例子主要根据行号来计算组号,其实也可以根据常规字段来计算,比如分组字段为月份时,可以先把月份换算成自然数,再按组号进行分组,这里就不展开了。
用序号排序
有些特殊的场景下,序号会参与排序计算,SPL 对序号提供了全面的支持,实现起来比较方便。
例子:xls 存储了近 3 年每位客户的消费额,按照客户的注册时间排列,部分数据如下:
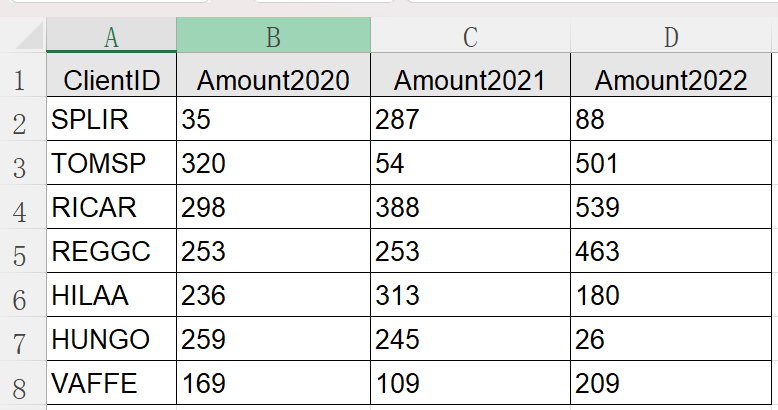
按客户重要性对上述数据排序,重要性与消费额的多少和注册时间的排名(行号)有关,具体算法:每年平均的消费额 +(客户总数 - 行号)*10
SPL 代码:
A |
|
1 |
=T("d:/ClientAmount.xlsx") |
2 |
=A1.sort@z([Amount2020,Amount2021,Amount2022].avg()+(A1.len()-#)*10) |
A2:函数 sort 可按表达式对记录进行排序,行号 #可作为保留的字段名直接参与表达式的计算,@z 表示逆序。
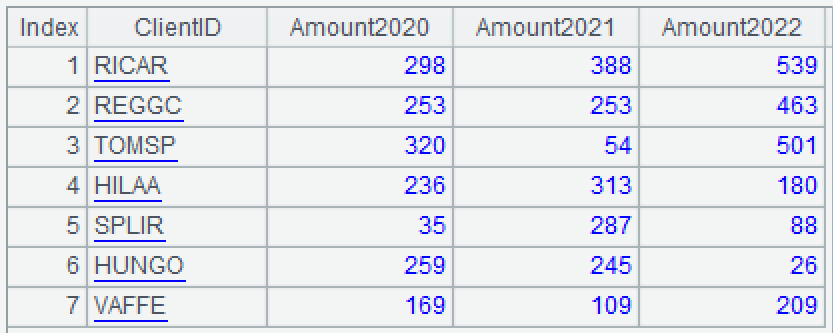
用序号对齐
与序号相关的对齐计算通常难度较大,比如记录集合的字段是不连续的自然数,需要对齐到连续的自然数上进行计算,对齐后每个自然数可能对应一条记录、多条记录、空值等多种情况,常规计算语言很难实现这种缺失数据的对齐。SPL 全面支持序号,可简化此类难题。
例 1:某社区修复自己的 29 栋旧公寓楼,公寓楼的楼号是自然数,每栋楼完工进度不同,数据库表记录了已完工的公寓楼的花费情况,不记录尚未完工的公寓楼。数据如下:
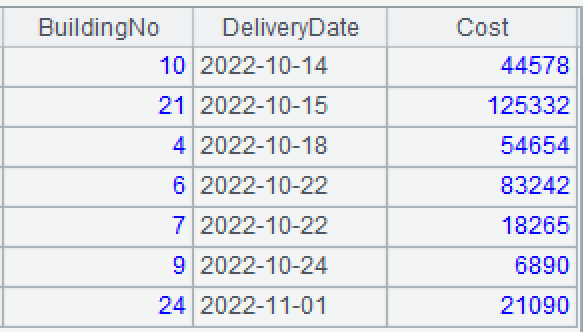
要求:输入楼号,查询修复该楼的花费,尚未完工的为空。
SPL 代码:
A |
|
1 |
=connect("myDB").query@x("select * from BuildingRepair") |
2 |
=A1.align(29,BuildingNo) |
3 |
=A2(arg_No).Cost |
A2:将楼房修复表的记录对应到完整的楼号序列上。函数 align 用 A1 的 BuildingNo 字段对齐从 1 到 29 的自然数序列。
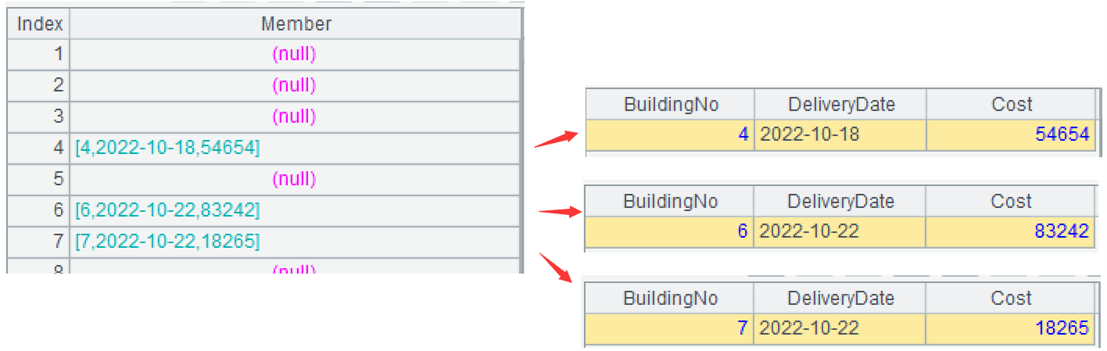
A3:查询对齐的结果,arg_No 为外部参数。当 arg_No=4 时,结果为 54654;arg_No=5 时,结果为 null。
可以看到,对齐和排序有一定的关系,对齐相当于一种自定义顺序的特殊排序,排序结果中可以有空记录。利用这个特点,可以实现一些常规方法难以实现的排序。
例 1 的对齐结果为单条记录,有时候对齐的结果还可以是记录集合(多条记录)。例 2:某文件存储一年的订单,但不是每个月都有订单,现在要统计每个月的订单金额,如果有缺失的月份,则该月金额显示为空。SPL 代码:
A |
|
1 |
=T("d:/Orders2019.txt") |
2 |
=A1.align@a(12,MONTH) |
3 |
=A2.new(#:mon,~.sum(AMOUNT):amt) |
A1:取数,某些月份无记录。
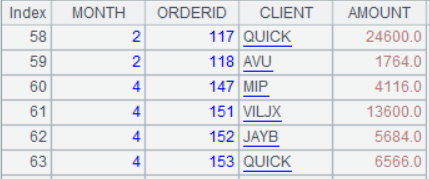
A2:将 A1 的 MONTH 字段按 1-12 的自然数列对齐。函数 align@a() 表示按第 1 个参数的成员对齐订单,每个成员对应一组订单记录。注意,对齐结果中包含订单为空的月份。
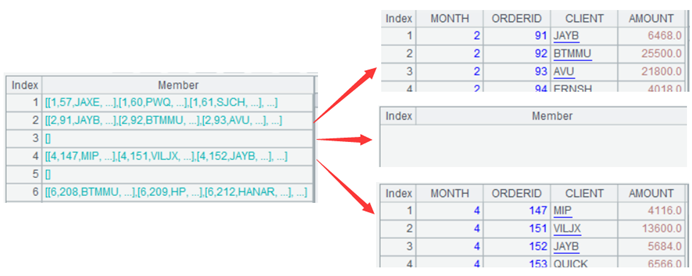
A3:根据 A2 生成新序表,mon 字段取自 A2 的行号(月份),amt 字段取自各组订单对 AMOUNT 的求和。
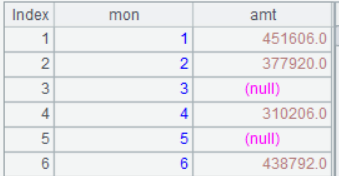
如果这个例子里的 MONTH 字段值包含 12,那么 A2 还可以写作 A1.group@n(MONTH),这是因为 align@a(12) 是按照 1-12 每个成员的值和位置对齐的,如果 MONTH 的值包含 12,则 A1.group@n(MONTH) 的组号也是 1-12,空缺的组也会按补齐。类似的,例 1 也可以改写成 group@n(BuildingNo)。
用序号关联
常规关联计算通常用哈希算法查找数据,如果外键值恰好是序号,则可以改用性能更高的位置查找来关联记录,但 SQL 没有这种概念,即使知道关联键是序号也仍然要计算哈希,SPL 全面支持序号,可以直接用序号关联。
例 1:事实表 Orders.txt 的 SellerId 是外键,对应维表 Seller.txt 的主键 EId,EId 是自然数。现在要关联两表,并分组汇总。SPL 代码:
A |
B |
|
1 |
=Orders=T("d:/Orders.txt") |
=Seller=T("d:/Seller.txt") |
2 |
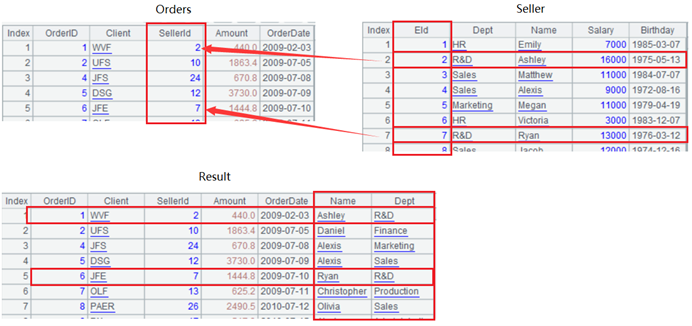
=Orders.join(SellerId,Seller:#,Name,Dept) |
|
3 |
=A2.groups(Dept,Name;sum(Amount):amt,count(1):cnt) |
A1,B1:读取事实表和维表,注意维表 Seller 的 Eid 字段是自然数,其数值与行号 #相等。
A2:按行号关联,并将 Seller 的 Name 和 Dept 字段附加到 Orders 中。其中,join 函数里 Seller 的关联字段是行号 #。关联过程如下,观察 Eid 为 2 和 7 的 Seller 记录更容易理解关联过程。
A3:分组汇总。
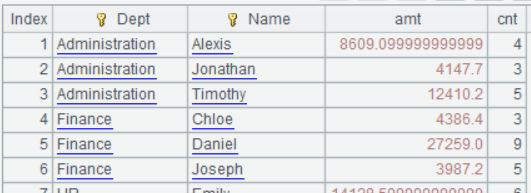
上面的维表主键恰好是自然数,可直接利用序号进行关联。如果维表主键不是自然数,可以先改造数据,再利用序号进行高性能关联,当然,改造的前提是不影响业务逻辑。
例 2:Orders 的外键 Client 和对应的 Customer 的主键 ID 是字符串:
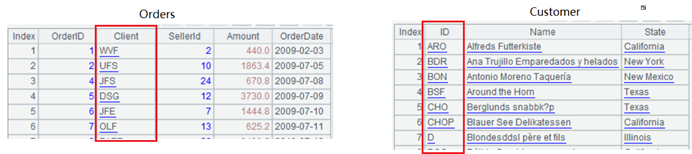
改造过程:事先把 Orders 的 Client 替换成 Customer 的 ID 对应的行号,Customer 这样的维表通常不必改动。将来正式关联时,只要保持 Customer 里记录的行号不变,就可以利用行号进行关联。保持记录的行号不变容易做到,如果数据源是数据库,只要按固定的字段排序;如果数据源是文件,直接按文件顺序取出。
改造或预处理代码:
A |
B |
|
1 |
=Orders=T("d:/Orders.txt") |
=Cust=T("d:/Customer.txt") |
2 |
=Orders.join(Client,Cust:ID,# : Client) |
|
3 |
=file("d:/OrdersS.btx").export@b(A2) |
A2:用 Orders 的外键 Client 关联 Cust 的 ID 字段,关联后只取 Cust 的行号 #,并命名为 Client,以便替换 Orders 的原来的 Client 字段。
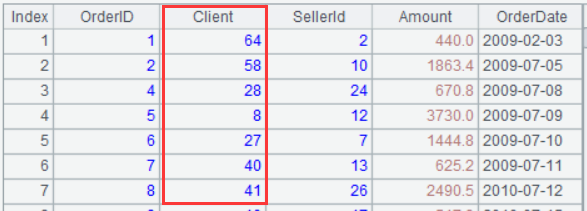
A3:存储改造后的 Orders,格式不限,这里使用了 SPL 的 btx 文件格式,具有较好的读写性能。
之后,就可以继续利用序号进行高性能关联计算,代码逻辑不变。
这个例子没有对维表进行条件过滤,主要因为过滤维表的场景不适合直接用序号关联,具体来说,先过滤再关联会导致维表的行号发生变化,关联将发生错误;而先关联后再过滤相当于对事实表过滤,事实表通常较大导致性能不高。如果遇到这样的场景,可以利用对位序列进行间接的序号关联,不仅可以在序号不变的前提下实现等价于过滤维表的操作,还可以对大事实表进行高性能关联。
对位序列是指与维表长度相等的序列,序列的每个成员表示对应位置的维表记录是否符合过滤条件,符合条件的为 true,不符合的为 false。下面用具体例子说明。
例 3:沿用例 1 的数据、关联关系,及汇总计算,但这次 Orders 体积较大,无法放入内存,且需要对小维表 Seller.txt 进行过滤。
SPL 代码:
A |
B |
|
1 |
=Orders=file("d:/Orders.btx").cursor@b(SellerId,Amount) |
=Seller=T("d:/Seller.txt") |
2 |
=Seller.(["HR","Sales"].contain(Dept) && Salary>10000) |
|
3 |
=Orders.select(B2(SellerId)) |
|
4 |
=B3.groups(Seller(SellerId).Dept,Seller(SellerId).Name;sum(Amount):amt,count(1):cnt) |
A1、B1:取数据。用游标取大事实表,只取用到的 2 个字段以提升性能。
B2:对维表进行条件过滤,生成对位序列。
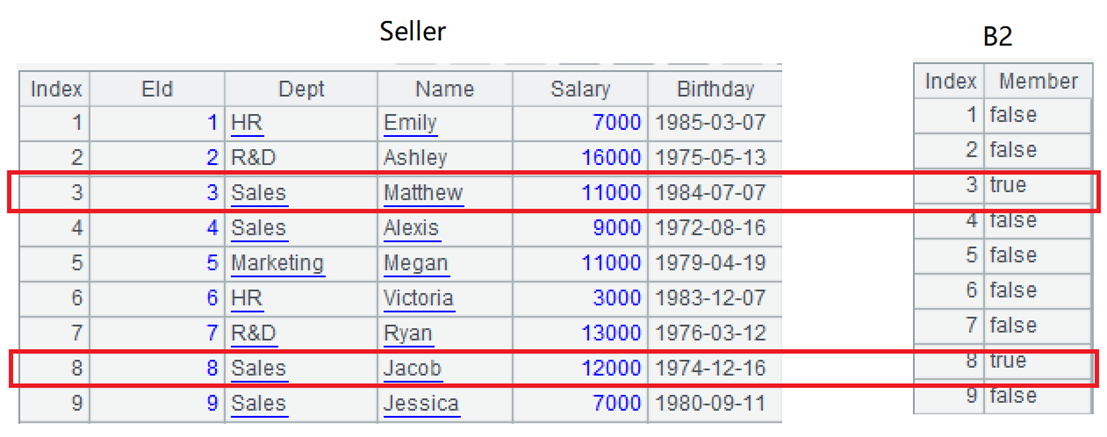
B3:用对位序列过滤事实表,过滤出符合条件的记录。用员工编号(即维表行号)进行位置查找去获取 B2 的成员时,可以知道该员工是否符合条件,比如 B2(5)=false,B2(8)=true,在 select 函数中,参数值为 true 时表示选出该条记录。注意,因为事实表是游标,所以这一步的过滤操作会在分组汇总才延迟执行,这里不能立即看到结果。后面实际执行时,过滤过程将如下所示:

B4:对过滤后的事实表进行分组汇总。其中,Seller(SellerId).Dept 用于取维表的 Dept 字段,这实际是个关联的动作。计算结果如下。



英文版