


1.4 距离法
数据中远离其他点的数据是不常见数据,比较数据中的每个点与其他所有点的距离(绝对差)之和,以最小距离和作为基准,超过该基准一定倍数的点就是异常值。
找出距离其他点都“不远”的数据,可以认为这些是正常数据,正常数据的最大值与最小值之外的数据可以认为是异常数据。
选定阈值型异常度函数:
TA[tu,td](x)=max(x-tu, td-x,0)/(tu-td)
其中tu、td是通过X[-k]i学习得到的上下限。
用X[-k]i计算tu、td的方法如下:
1.计算X[-k]i中每个点到其他所有点的距离和
第p个点xp的距离和记为dp
dp=sum(|xp-xq|),xq∈X[-k]i
其中xp是X[-k]i中的第p个点,xq是X[-k]i中的第q个点。距离和形成的序列用D表示。
2.最小距离和记为dmi
dmi=min(D)
3.将不大于n倍最小距离和(n*dmi)的xp序列看作距离其他点“不远”的数据,记为SX,把它的最小值作为下限值td,最大值最为上限值tu。
SX=[xp,dp≤n*dmi]
td=min(SX)
u= max(SX)
异常度od这样计算:
od=max(xi-tu, td-xi,0)/(tu-td)
SPL例程:
A |
B |
|
1 |
=data=file(“1Ddata.csv”).import@tci().to(100) |
|
2 |
=n=2 |
/距离倍数n |
3 |
=ldata=data.m(:100) |
/区间是100的学习数据x[-k]i |
4 |
=xi=data(101) |
/xi |
5 |
=D=ldata.((v=~,ldata.(abs(v-~))).sum()) |
/每个点与其他点的距离和D |
6 |
=dmi=D.min() |
/最小距离和dmi |
7 |
=D.pselect@a(~<=n*dmi) |
/小于n倍最小距离和的索引 |
8 |
=SX=ldata(A7) |
/正常数据SX |
9 |
=td=SX.min() |
/下限值td |
10 |
=tu=SX.max() |
/上限值tu |
11 |
=od=max(xi-tu,td-xi,0)/(tu-td) |
/异常度od |
调整n的大小可以调整上下限, n的默认值可以设置为2。
计算结果示例:
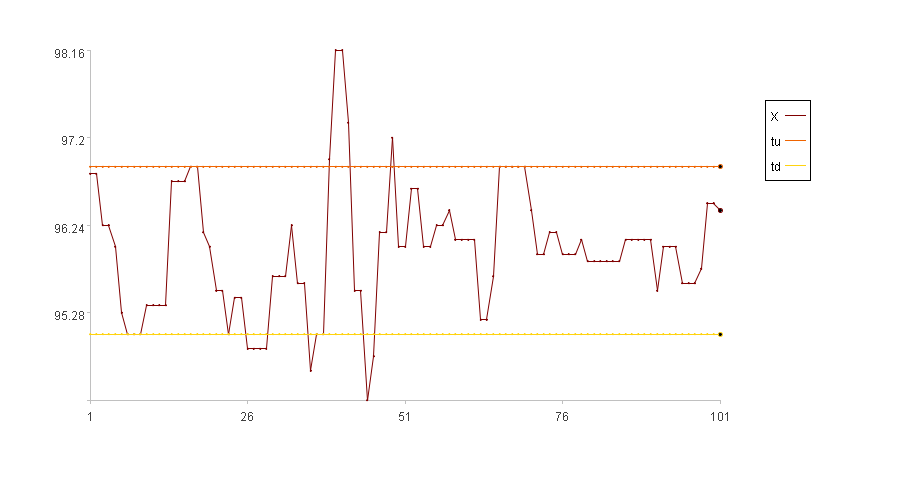
xi在tu和td之间,所以异常度是0。

