


支持向量机 SVMs
在SPL中svm()中包含了C-SVC,nu-SVC,epsilon-SVR和nu-SVR五种算法,可用于解决分类问题和回归问题。详细的语法和参数说明见函数参考文档http://d.raqsoft.com.cn:6999/esproc/func/math.html。
例如,回归问题
继续使用上节的样本数据,使用svm()进行建模和预测
A |
|
1 |
[[1.1,1.1],[1.4,1.5],[1.7,1.8],[1.7,1.7],[1.8,1.9],[1.8,1.8],[1.9,1.8],[2.0,2.1],[2.3,2.4],[2.4,2.5]] |
2 |
[16.3,16.8,19.2,18,19.5,20.9,21.1,20.9,20.3,22] |
3 |
[[2.4, 2.4]] |
4 |
>svm_type=3,kenel=0,degree=3,cache_size=100,eps=0.001,C=1,gamma=0.25,coef=0,nu=0.5,p=0.1,nr_weight=1,shrinking=1,probability=0 |
5 |
=[svm_type,kenel,degree,cache_size,eps,C,gamma,coef,nu,p,nr_weight,shrinking,probability] |
6 |
=svm(A1,A2,A5) |
7 |
=svm(A6,A3) |
8 |
=svm(A1,A2,A5,A3) |
A1 训练集x
A2 训练集y
A3 预测样本
A4 设值svm的参数,选择SVR回归算法
A5 将A4中的参数值传入到序列中,作为svm的参数param
A6 输入训练数据和参数,执行建模,返回模型R。R中成员值依次为:决策函数中支持向量的系数,每个类别的标签,类别数,总支持向量的数量,每个类别的支持向量数量,决策函数中的常数,支持向量,训练时的参数param
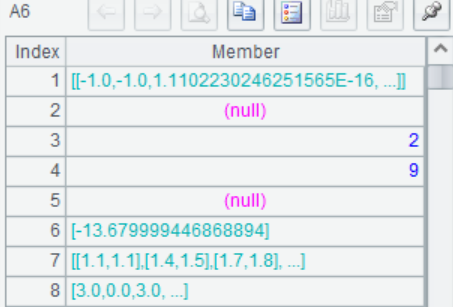
A7 根据A6的模型信息R,在预测数据进行预测,返回预测结果
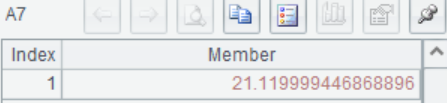
A8 连续进行建模和预测,直接返回预测结果,效果等同于A6+A7
再例如,分类问题
使用泰坦尼克的数据,由于该数据中有缺失值和字符型变量不能直接建模,因此在使用前已进行了相关处理,在本例中直接用处理过的数据进行建模演示。
A |
|
1 |
=file("D://titanic_svm.csv").import@tc() |
2 |
=A1.array().to(2:) |
3 |
=A2.(~.to(2:)).to(800) |
4 |
=A2.(~(1)).to(800) |
5 |
=A2.(~.to(2:)).to(801:) |
6 |
>svm_type=0,kenel=2,degree=3,cache_size=100,eps=0.001,C=1,gamma=0.25,coef=0,nu=0.5,p=0.1,nr_weight=1,shrinking=1,probability=0 |
7 |
=[svm_type,kenel,degree,cache_size,eps,C,gamma,coef,nu,p,nr_weight,shrinking,probability] |
8 |
=svm(A3,A4,A7) |
9 |
=svm(A8,A5) |
10 |
=svm(A3,A4,A7,A5) |
A1 导入数据,读成序表
A2 序表改为向量形式,去掉标题
A3 取前800条样本的自变量,作为训练集X
A4 取前800条样本的目标变量,作为训练集Y
A5 取800条以后的样本自变量,作为预测集
A6 设置输入svm的参数,选择SVC算法
A7 将A6中的参数值传入到序列中,作为svm的参数param
A8 用A7中的参数,在训练集上训练,返回训练结果R
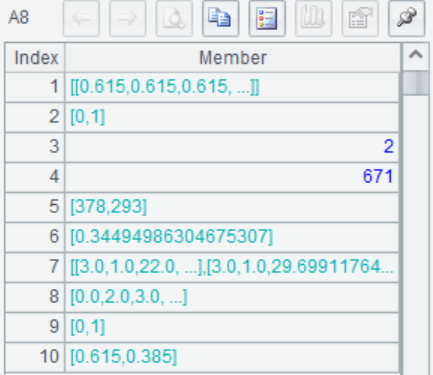
A9 根据训练结果R,在预测集上进行预测,返回预测结果
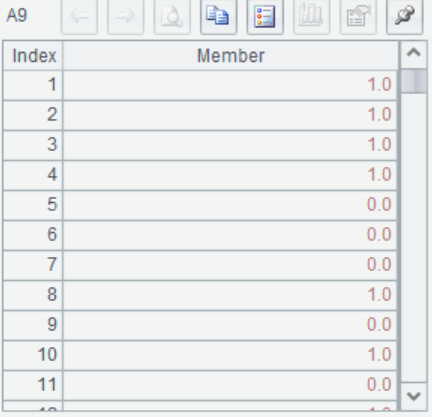
A10 连续进行建模和预测,直接返回预测结果,效果等同于A7+A8

