低频分类数据处理
当分类变量的分类数较多时,可能会存在一些频数极小的类别,例如极少数分类,异常分类,疑似错误分类等情况,这时可以通过合并低频变量来降低分类个数。
例如Titanic.csv中的“Name”是一个分类变量,在每个乘客的名字中都含有”Mr”,”Mrs”这样的称呼,我们将其提取出来生成新的变量”Title”,然后对”Title”进行分析并合并低频分类。
代码如下:
A |
|
1 |
=file("D://titanic.csv").import@qtc() |
2 |
=A1.derive(Name.split@b(",")(2).split(".")(1):Title) |
3 |
=A2.groups(Title;count(~):count) |
4 |
=A2.group(Title) |
5 |
=A4.align@a([true,false],~.len()<10) |
6 |
=A5(1).(~.run(Title="others")) |
7 |
=A2 |
8 |
=A7.groups(Title;count(~):count) |
A2 提取”Name”中的Title信息
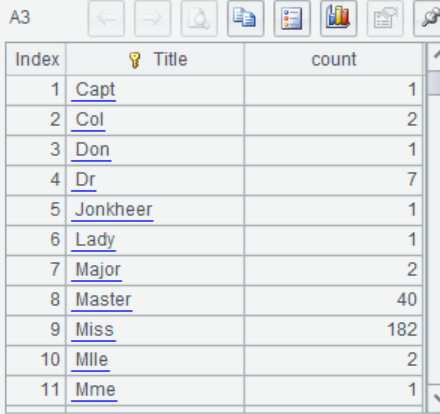
A3 查看Title中的分类情况,其中有一些低频类别,比如“Capt”,”Don”…
A4 将A2中的样本按照Title分组
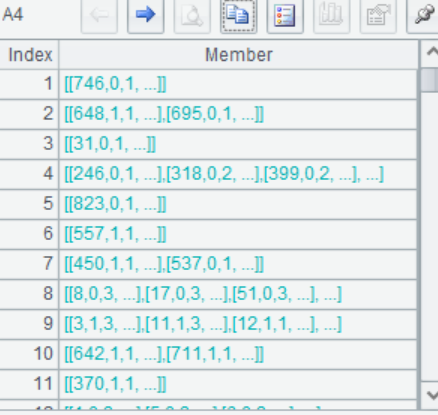
A5 将Title分类数<10的分为一组,>=10的分为一组
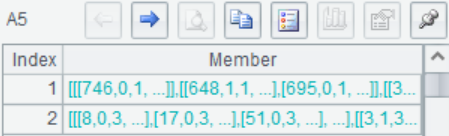
A6 将分类数小于10的样本Title统一改为”others”
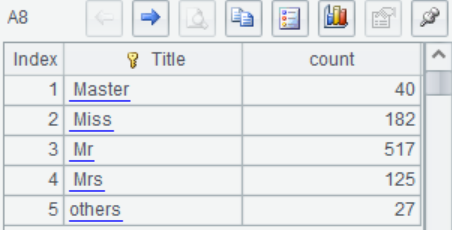
A8 再次查看Title的分类情况,低频分类被统一合并为”others”