




怎样实现 T+0 的实时报表?
T+0 的概念,运用比较广泛的是在金融领域,T(Transaction)表示交易日期,+0 就是指交易当天,+N 就代表交易的 N 天后
现在大数据、数据分析领域,也总用到这个概念,含义仍然相同,T+0 表示当天的实时数据,T+N 则表示当天的数据 N 天后才能看到
放到报表中 T+0 就是今天的报表就可以看到今天实时的数据,T+1 就是今天的数据,明天才能看到
T+0 报表的难点在哪里
如果所有数据都存在一个数据库中,那 T+0 报表其实没什么难度,直接查就是最新的实时数据
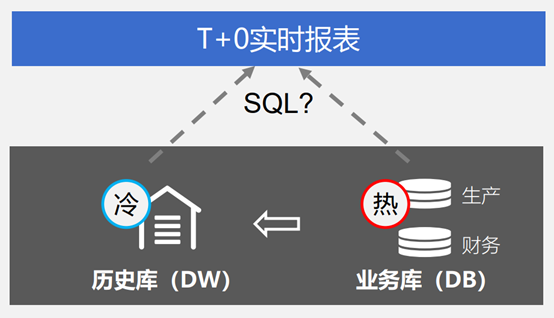
但实际应用中,很多场景下,数据是会分开存储的,比如下图这样,由于历史数据过于庞大,为了保证业务库的性能不受影响,就只能把老的历史数据迁移到别的库去存储,这时候,如果报表需要同时分析历史数据和当前最新数据做 T+0 报表,就需要从不同的分库中同时取数,而且历史库和业务库很多时候又不是一个类型,怎么跨库查询取数就成了一难题,这也正是 T+0 报表的难点所在
如果解决不了这个难题,那就只能用 ETL 等方式,定时把冷热库的数据抽取到一起,然后再出报表,那就是 T+1 甚至严重到会 T+7 了
目前有什么手段
报表本身的多数据集
好一些的报表工具,其实提供了一个初级的解决方案,就是报表本身的多数据集功能,它可以直接进行跨库查询,获取最新数据,做出 T+0 报表,比如下面这样的
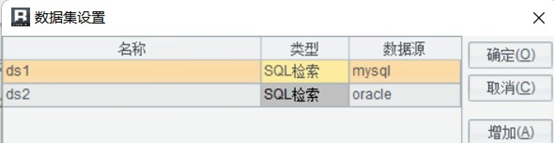

但是报表工具计算能力有限,只能做一些初级简单的,比如上面的分组汇总,两个数据集的分组情况如果相同,或者第一个数据集包含第二个的,那可以这样做,否则分组就会错乱,就不好做了,就得用自定义数据集提前把数据合并好了
还有一些其他复杂的计算单凭报表的计算能力也无法实现,也得用定义数据集算
另外分库的数据一般数据量非常大,全部把计算放到报表内,在性能上也不一定能保证,不是很适用
所以报表工具的多源混算在简单场景下可以做出 T+0 报表,复杂情况下不能胜任,是比较初级的功能
数据库的跨库查询
数据库本身也有跨库查询的功能,比如 Oracle 的 DBLink,MySQL 的 FEDERATED 引擎,都可以进行跨库查询,也可以做到 T+0 查询,再把数据给到报表,就能做出 T+0 报表,但是这些功能都对异构数据支持的不是很好,对非关系型数据源更是无能为力,适用的场景也比较窄
JAVA 编码
这是工程师的杀手锏,没有好办法,那就敲代码呗,没有什么是代码搞不定的,一个跨库取数难不倒 JAVA, 不管你是同构异构还是非关系数据库,各种情况都能搞定
但话又说回来,但凡有更简单的办法,谁愿意做个查询取数还得用 JAVA 实现呢
JAVA 写起来难,算起来慢
JAVA 这类高级语言,对结构化数据的计算支持很有限,虽然都能做,但却能力比较弱,写起来非常繁琐,简单做个求和运算都需要写数行代码的循环来实现,而报表数据源处理则大量涉及批量数据运算,采用高级语言开发时会导致动辄数百行的冗长代码,编写、调试和后续维护都会很困难,而且性能也无法保证,高手懂算法,写出来的就算的快一些,普通人写的可能就会出现性能问题
JAVA 还破坏应用架构
JAVA 代码需要和应用程序一起编译、打包,造成和应用的高度耦合,给后续维护带来困难
每次修改,都得重新编译,就需要整个应用陪着重启甚至停机,影响应用稳定
所以 JAVA 虽然什么都可以搞定,能力很强,但却也不是一个很好的选择
更好的方法
看过各种手段的不足后,我们也就明了了,更好的方案,需要它支持跨库运算,支持同构异构数据,支持各类不同数据源,支持大数据量,书写简单,性能好,不会破坏应用
有这样的方案吗?
有
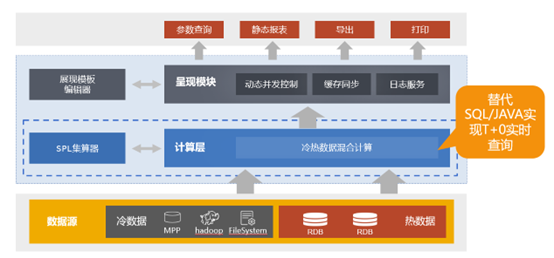
润乾报表集成SPL 集算器以后就具备了这样的能力
SPL 是一款流行的专业的数据计算处理工具,很多项目开发商都在用,因为它不仅好用,而且还免费,开源,是常年做项目,总需要做数据处理的工程师的好帮手
SPL 支持各类数据源
集成 SPL 后,润乾报表相当于多了一个计算层,这个计算层支持常见的各类数据源,可以同时计算来自不同数据源的数据,不管它是同构还是异构,不管你怎么分库,分到哪里,都能做到 T+0

| A | ||
|---|---|---|
| 1 | =cold=db1.cursor(“select * from orders where odate<?”,date(now())) | / 冷数据从历史库中取,昨天及以前的数据 |
| 2 | =hot=db2.cursor(“select * from orders where odate>=?”,date(now())) | / 热数据从生产库中取,今天的数据 |
| 3 | =[cold,hot].conjx() | |
| 4 | =A3.groups(area,customer;sum(amout):amout) |
开发简单,性能好
SPL 不仅可以像上面的代码一样,简单写出跨库的取数查询,比 JAVA 简单的多,它还比 SQL 写起来简单
看个小例:查出各科成绩都在前 10 名的学生
用 SQL 写起来,比较复杂,也很难理解
from (select name
from (select name,
rank() over(partition by subject order by score DESC) ranking
from score_table)
where ranking<=10)
group by name
having count(*)=(select count(distinct subject) from score_table)
用 SPL,则按思路过程写出计算就行,写起来简单,还容易理解,性能也比 SQL 要更好,而且在 SPL 中, 这样的高性能函数和算法还有很多,谁都可以直接用,不需要非得高手才能写出性能好的算法了
| A | |
|---|---|
| 1 | =score_table.group(subject) |
| 2 | =A1.(~.rank(score).pselect@a(~<=10)) |
| 3 | =A1.(~(A2(#)).(name)).isect() |
说到性能,还要提到开源 SPL 有自己的存储,它提供了高效的二进制文件存储方式,文件存储具备很多优势,不仅读取效率更高,还可以有效利用文件压缩、并行等机制提速,同时还不会像数据库那样容易受到容量的限制,在一些传统的历史库无法保证计算性能和时效的情况下,甚至可以用 SPL 的二进制文件存储当做历史库来提升性能了
低耦合热切换
SPL 作为润乾报表的计算层,它编写的计算脚本是存储在报表模板里的,是解释执行的,这就避免了和应用的耦合
解释执行的 SPL 同时也具备了热切换的能力,不会像 JAVA 一样影响应用的稳定了
总结
大数据时代,数据的分库存储很常见,T+0 实时报表的需求更常见,用常规的手段来做,简单的、少量的情况还能应付,复杂,大量的时候,就需要用更好更新的技术了,润乾的 SPL 计算层,不仅可以轻松应对各类跨库实时查询,而且在开发效率和性能上也比常规手段更简单高效的多,它还开源免费,并不需要在报表以外再多加成本,另外润乾报表本身价格也很亲民,1W 一套,3W 一年随便用,一套润乾,就把报表需求和各类数据准备的外围难题都解决了
对润乾产品感兴趣的小伙伴,一定要知道软件还能这样卖哟性价比还不过瘾? 欢迎加入好多乾计划。
这里可以低价购买软件产品,让已经亲民的价格更加便宜!
这里可以销售产品获取佣金,赚满钱包成为土豪不再是梦!
这里还可以推荐分享抢红包,每次都是好几块钱的巨款哟!
来吧,现在就加入,拿起手机扫码,开始乾包之旅

嗯,还不太了解好多乾?

