K-means 聚类填补
K-means聚类又称为快速聚类,是一种需要事先确定类别个数的聚类方法。使用K-means聚类可以将全部样本分成若干个组,如果假定包含缺失值的变量在不同分组具有不同的取值,则可以使用该变量非缺失部分在每个分组的均值为相应位置的缺失值进行填补。
在SPL中可使用kmeans()函数进行快速聚类
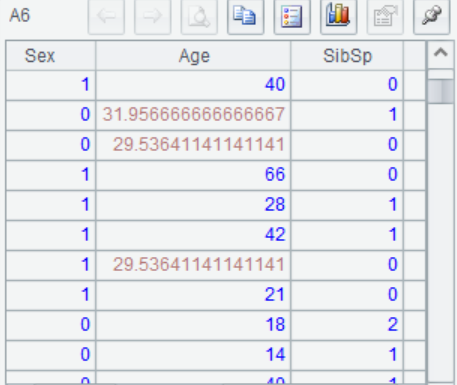
例如,使用k-means聚类方法对titanic.csv中的”Age”变量进行填补。
由于在titanic.csv的数据中存在字符型变量,不能直接用于k-means算法,因此提前对数据中的分类变量做了处理,处理后的数据为titanic_impute.csv。
A |
|
1 |
=file("D://titanic_impute.csv").import@qtc() |
2 |
=A1.fname().delete(4).concat@c() |
3 |
=A1.new(${A2}) |
4 |
=A3.array().to(2:) |
5 |
=kmeans(A4,2,A4).conj() |
6 |
=A1.derive(A5(#):kmeans) |
7 |
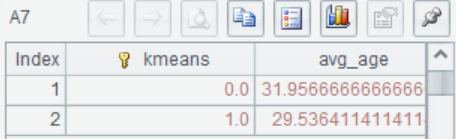
=A6.groups(kmeans;avg(Age):avg_age) |
8 |
=A6.run(Age=if(!Age,if(kmeans>0,A7(2).avg_age,A7(1).avg_age),Age)) |
A1 导入数据titanic_impute.csv
A2-A3 去掉变量Age
A4 将去掉Age变量的序表转为向量形式
A5 使用kmeans()建模和预测,将数据样本分为2类
A6 将每个样本的分类结果添加到表格
A7 计算每组分类的Age平均值
A8 使用每组的平均值填补该组内的缺失值。如图,不同组的样本,填补值不同。