连续型数据探索
连续型数据属于定量数据,对于定量数据通常可以从集中趋势测度、分散测度、相对位置测度和对称性测度四个维度来分析。

例如泰坦尼克数据中有一个连续型变量”Age”,表示乘客的年龄,探索代码如下:
A |
||
1 |
=file("D://titanic.csv").import@qtc() |
|
2 |
=A1.(Age) |
|
3 |
=A2.max() |
|
4 |
=A2.min() |
|
5 |
=A2.avg() |
|
6 |
=A2.mode() |
|
7 |
=A2.median() |
|
8 |
=A2.median(1:4) |
|
9 |
=A2.median(3:4) |
|
10 |
=var@s(A2) |
|
11 |
=sqrt(A9) |
|
12 |
=A2.skew() |
|
13 |
=A2.se() |
|
14 |
8 |
|
15 |
=(A2.max()-A2.min())/A14 |
|
16 |
=A14.([(~-1)*A15+A2.min(),~*A15+A2.min()]) |
|
17 |
=A16.new(~:group,(~(1)+~(2))/2:group_median, if(#==A16.len(),count(A2.(~>=group(1)&&~<=group(2))),count(A2.(~>=group(1)&&~<group(2)))):count) |
|
18 |
=canvas() |
|
19 |
=A18.plot("EnumAxis","name":"x") |
|
20 |
=A18.plot("NumericAxis","name":"y","location":2) |
|
21 |
=A18.plot("Column","text":A17.(count),"axis1":"x","data1":A17.(string(group_median)),"axis2":"y","data2":A17.(count)) |
|
22 |
=A18.draw@p(800,450) |
|
23 |
||
24 |
=A1.impute("Age") |
[0.25,0.5,0.75] |
25 |
=A24(1).sort() |
=A25(1) |
26 |
=A25.(#/A25.len()) |
=A25.m(-1) |
27 |
=canvas() |
|
28 |
=A27.plot("NumericAxis","name":"x","autoCalcValueRange":false,"maxValue":1,"scaleNum":10,"allowRegions":false) |
|
29 |
=A27.plot("NumericAxis","name":"y","location":2,"autoCalcValueRange":false,"autoRangeFromZero":false,"maxValue":A25.m(-1),"minValue":A25(1)) |
|
30 |
=A27.plot("Line","lineColor":-16776961,"markerWeight":1,"axis1":"x","data1":A26,"axis2":"y","data2":A25) |
|
31 |
for B24 |
=A27.plot("Line","lineStyle":2,"lineColor":-65281,"markerWeight":-1,"axis1":"x","data1":[A31,A31],"axis2":"y","data2":[B25,B26]) |
32 |
=A27.draw@p(800,400) |
A2-A9 计算变量的基本统计量,最大值、最小值、平均值、众数、中位数、四分位数
A10-A13 计算变量的方差、标准差、偏度、标准误
对于连续型变量,也可以通过可视化的方式来观察数据,最常用的就是直方图
A14-A22 绘画直方图。绘图之前需要先确定直方柱体的个数,然后将变量进行等距分组,统计落到每个分组区间(柱体)的样本个数。
A14 输入柱体的个数为8
A15 计算每个柱体的宽度
A16 将变量Age等距分为8组,返回每个分组的区间范围,大约每隔10岁为一组。
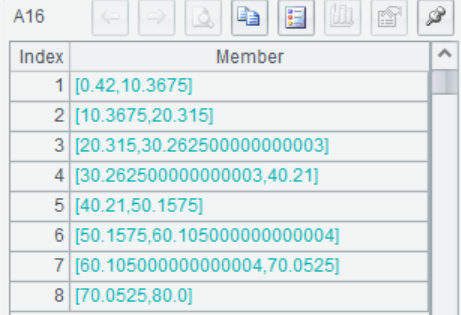
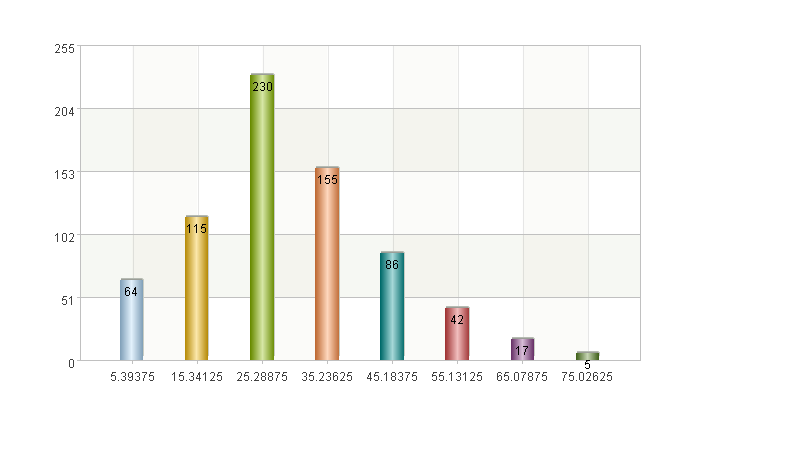
A17 计算每组的中位数和落入该组的乘客数,比如第一组0到10岁的乘客有64个

A18-A22 使用A17的数据进行绘图,可以看到每个年龄段的人数分布情况
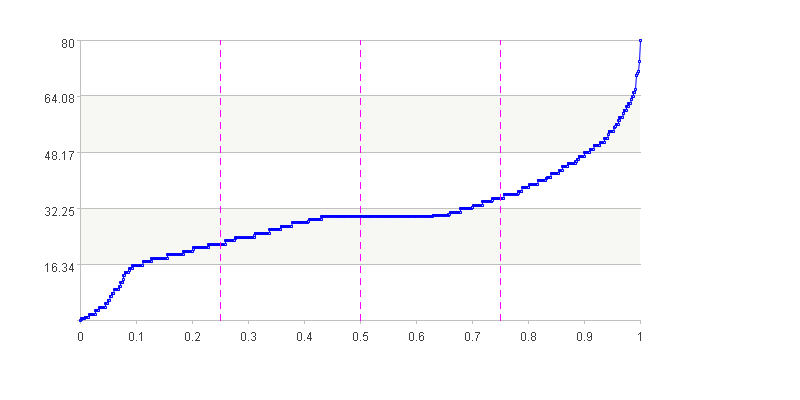
连续型变量有时也可以用分位数图来表示
A24-A32 绘画变量Age的分位数图