分类数据探索
分类数据属于定性数据,通常可以从以下几个维度来探索分析
 在SPL中可以使用A.id(), A.group(),A.groups()等函数来进行相关的操作。
在SPL中可以使用A.id(), A.group(),A.groups()等函数来进行相关的操作。
例如,在泰坦尼克的数据中,有一个”Embarked”的变量表示乘客的登船信息,是一个分类变量,用上述几个函数探索如下:
A |
|
1 |
=file("D://titanic.csv").import@qtc() |
2 |
=A1.id(Embarked) |
3 |
=A1.(Embarked).mode() |
4 |
=A1.group(Embarked) |
5 |
=A1.groups(Embarked;count(~):count,count(~)/A1.len():freq) |
6 |
=A4.run(if(Embarked,Embarked,"null"):Embarked) |
7 |
=canvas() |
8 |
=A6.plot("EnumAxis","name":"x","location":3,"polarX":0.55, "allowLabels":false) |
9 |
=A6.plot("NumericAxis","name":"y","location":4,"allowLabels":false) |
10 |
=A6.plot("Sector","text":A4.(count),"axis1":"x","data1":A4.(Embarked),"axis2":"y","data2":A4.(count)) |
11 |
=A6.draw@p(600,450) |
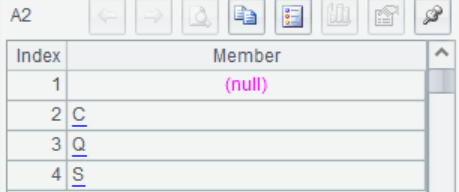
A2 使用A.id()可以查看变量有哪些类别,如图可以知道乘客有C, Q, S三种登船口,还有乘客缺失登船信息
A3 计算变量的众数,得到Embarked众数为”S”
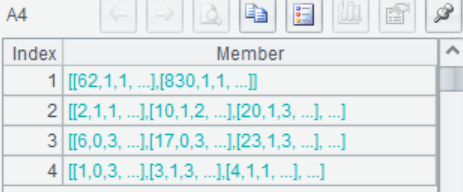
A4 使用A.group(),可以对变量进行分组,如图根据乘客的登船口的不同分成了4组,第1组中是Embared信息缺失的乘客样本。
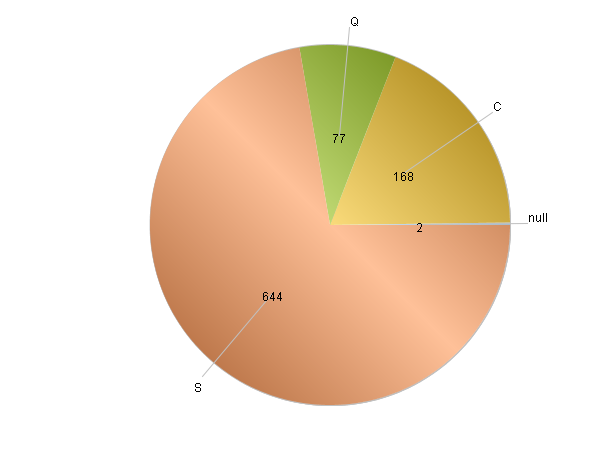
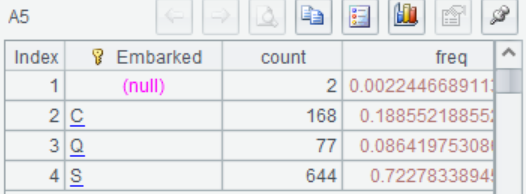
A5 A.groups()可以进行分组聚合计算,计算出变量Embarked每种分类的数量和占比。比如登船口为”C”的乘客有168名,占比约18.85%。
groups除了可以计算count,还支持sum/max/min/top/avg/iterate/icount/median
对于分类变量还可以用可视化的方式来进行查看
A7-A11 表示绘画饼图来查看变量Embarked,需要主要的是画图时数据中是不允许有缺失值,因此对于缺失值画图前需要特殊处理,在这里我们在A6中将缺失值作为一个单独的类别’’null”来处理。画图如下,可以直观的看到变量的分布情况。