分类变量数值化
分类变量通常是字符形式,字符是无法直接被算法识别和计算的,必须转化成数值型数据。
在SPL中提供了可以自动处理分类变量的函数。
对于分类数不高于6的低频分类变量,可以使用A.bi()或P.bi(cn)函数,将分类变量拆分为多个取值为0,1的二值变量。
对于分类数较多的高频分类变量,则可使用A.setenum()或P.setenum(cn)将变量映射成整数。
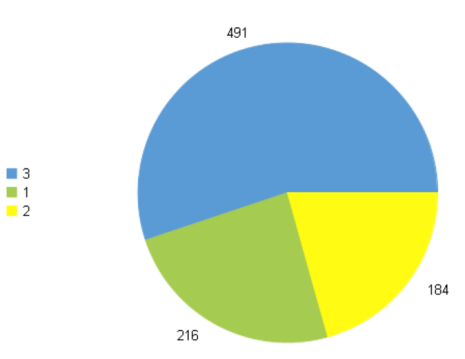
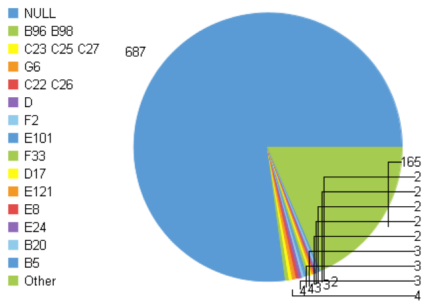
例如在泰坦尼克的数据中,变量“Pclass”的分类数为3为低频分类变量,变量”Cabin”的分类数为148,为高频分类变量。
SPL处理如下:
A |
|
1 |
=file("D://titanic.csv").import@qtc() |
2 |
=file("D://titanic_t.csv").import@qtc() |
3 |
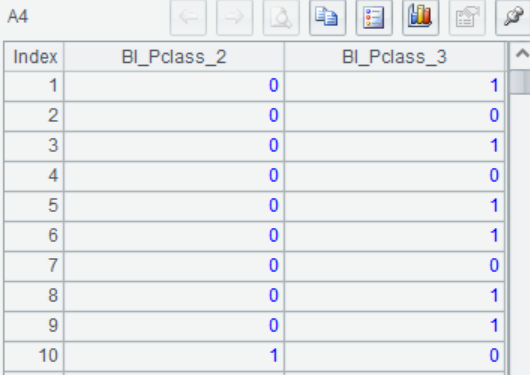
=A1.bi("Pclass") |
4 |
=A2.bi@r("Pclass",A3(2)) |
5 |
=A1.setenum@c("Ticket") |
6 |
=A2.setenum@rc("Ticket",A5(2)) |
A1 导入建模数据
A2 导入预测数据
A3 在建模数据里,对“Pclass“衍生多个二值变量,A3(1)返回处理结果,A3(2)返回处理记录Rec
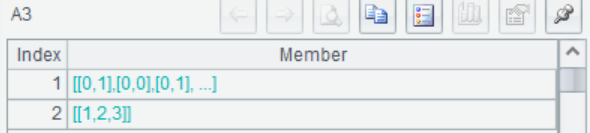
A4 根据A3的处理记录Rec,在预测集上对同一数据进行衍生
A5 将分类变量”Ticket”,映射成整数,返回映射结果和映射记录Rec。@c表示将原始数据改为映射结果。
A6根据A5的映射记录,在预测数据上,对同一变量进行映射,返回映射结果