缺失值信息提取
提取单变量缺失信息
为每个包含缺失值的变量建立一个哑变量形式的新变量,用于将该变量的缺失信息标识出来。
在SPL中A.mi()和P.mi()会自动生成一个变量来标记缺失信息
例如,对titanic.csv中的变量缺失情况进行标记:
A |
|
1 |
=file("D://titanic.csv").import@qtc() |
2 |
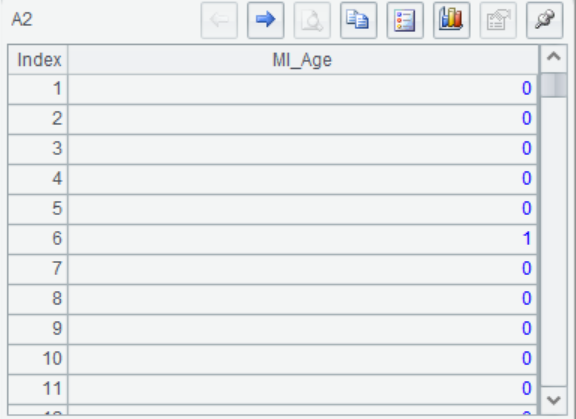
=A1.mi("Age") |
3 |
=A1.fname() |
4 |
=A3.(A1.mi(~)) |
A2 生成一个MI_Age的变量来标记Age是否缺失
mi()函数会判断变量的缺失率,当缺失率小于5%或大于95%时则不会指示变量,而是返回null
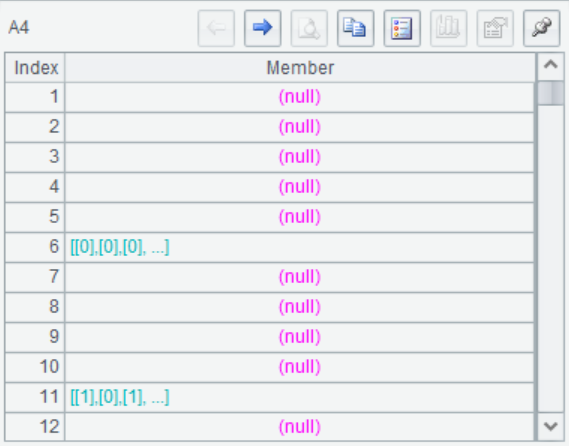
A4 标记所有字段的缺失信息,可以看到只有第6和第11个字段生成了MI指示变量。
提取多个变量缺失信息
当数据集中包含缺失值的变量较多时,单个变量的提取方式会极大地增加模型的复杂度,这时可以通过只建立一个新变量,将每一个样本在所有变量上的缺失值情况标识出来。这种方法虽无法体现具体变量影响,但是对模型复杂度影响不大。
在SPL使用A.mvp(T)或P.mvp(cns, T)可以整合多个MI,用mvp变量来表示多变量的缺失信息,并且对mvp变量自动进行后续处理。
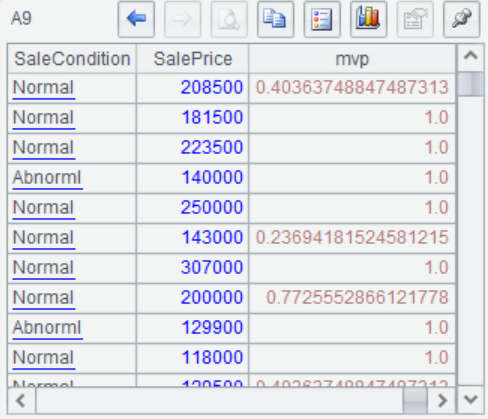
例如在房价预测的数据中有81个变量,使用mvp函数提取多个变量的缺失信息
A |
|
1 |
=file("D://house_prices_train.csv").import@qtc() |
2 |
=A1.fname() |
3 |
=A2.(A1.mi(~)) |
4 |
=A3.group(!~) |
5 |
=to(A4(1).len()).("A4(1)("/~/")(#).field(1):MI_"/~).concat@c() |
6 |
=A1.derive(${A5}) |
7 |
=to(A4(1).len()).("\""/"MI_"/~/"\"").concat@c() |
8 |
=A6.mvp([${A7}],A1.(SalePrice)) |
9 |
=A1.derive(A8(1)(#).field(1):mvp) |
A2 获取变量名称
A3 提取每个变量的缺失值信息,存在缺失值的变量返回MI指标,无缺失值的变量会返回空值
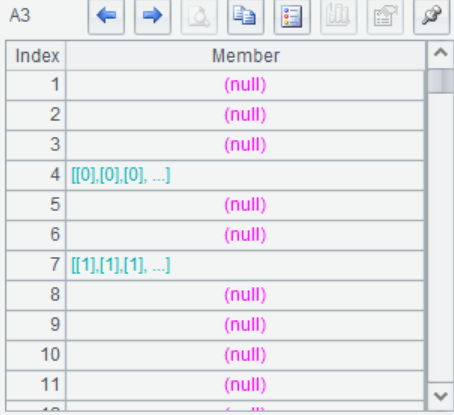
A4 根据MI指标是否为空,分成两组
A5-A6 将MI指标添加到序表A1
A7 提取各个MI指标字段名称,作为A8的输入参数
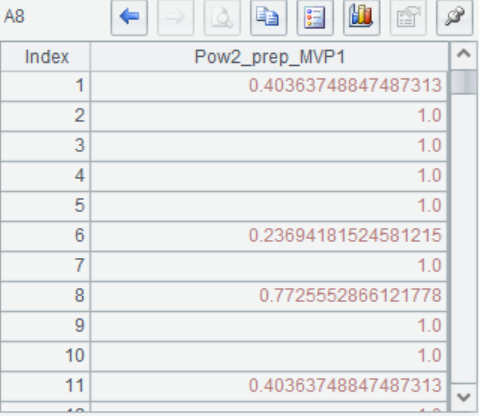
A8 使用P.mvp(cns, T)函数整个多个MI指标,生成一个mvp变量来表示多变量的缺失信息,并且自动对mvp变量做预处理操作,比如图中Pow2表示幂变换。有关mvp()的详细使用说明请参考http://d.raqsoft.com.cn:6999/esproc/func/math.html
A9 将mvp变量添加到建模数据A1