


分类模型评估:准确率,精确率,查全率,特异度,F1
计算各种评估指标之前,首先需要计算混肴矩阵:
真正类数(True Positive , TP):被模型预测为正的正样本。
假正类数(False Positive , FP):被模型预测为正的负样本。
假负类数(False Negative , FN):被模型预测为负的正样本。
真负类数(True Negative , TN):被模型预测为负的负样本。
各指标计算公式如下:
准确率(Accuracy), ACC=(TP+TN)/N,
精确率/查准率(Precision), PPV=TP/(TP+FP),
灵敏度/召回率/查全率(Sensitivity/Recall) , TPR=TP/(TP+FN),
特异度(Specificity) , TNR=TN/(FP+TN),
F1=2*Precision*Recall/(Precision+Recall)
例如在titanic_export.csv的数据中,有目标变量的真实值Survived,阈值0.5时预测值Survived_predict 和目标变量为 1 的概率预测值 Survived_1_percentage
Survived_1_percentage |
PassengerId |
Survived |
Survived_predict |
0.146539017 |
1 |
0 |
0 |
0.966226989 |
2 |
1 |
1 |
0.644612591 |
3 |
1 |
1 |
0.970606942 |
4 |
1 |
1 |
0.096753954 |
5 |
0 |
0 |
… |
… |
… |
… |
根据计算公式,对阈值0.5时的预测结果Survived_predict进行评估
A |
B |
|
1 |
=T("D://titanic_export.csv") |
|
2 |
=A1.select(Survived==1 && Survived_predict==1) |
|
3 |
=A1.select(Survived==0 && Survived_predict==1) |
|
4 |
=A1.select(Survived==1 && Survived_predict==0) |
|
5 |
=A1.select(Survived==0 && Survived_predict==0) |
|
6 |
>TP=A2.len(),FP=A3.len(),FN=A4.len(),TN=A5.len(),N=A1.len() |
|
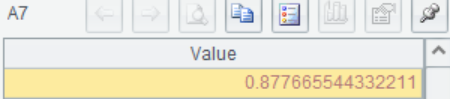
7 |
=(TP+TN)/N |
/Accuracy |
8 |
=TP/(TP+FP) |
/Precision |
9 |
=TP/(TP+FN) |
/Sensitivity/Recall |
10 |
=TN/(FP+TN) |
/Specificity |
11 |
=2*A8*A9/(A8+A9) |
/F1 |
A2 被模型预测为正的正样本
A3 被模型预测为正的负样本
A4 被模型预测为负的正样本
A5 被模型预测为负的负样本
A6 计算TP,FP,FN,TN,N
A7 计算准确率Accuracy
A8-A11 同理,根据计算公式计算其他指标

