


聚类 -kmeans
使用kmeans()可以将样本按照指定的类数,进行聚类。目前SPL中的聚类数暂且只支持2。
例如,有一组样本[[1,2,3,4],[2,3,1,2],[1,1,1,-1],[1,0,-2,-6]],使用kmeans()聚为2类,并使用聚类模型预测样本[[6,2,3,5],[0,3,1,5],[1,2,1,-1],[1,5,2,-6]]
A |
|
1 |
[[1,2,3,4],[2,3,1,2],[1,1,1,-1],[1,0,-2,-6]] |
2 |
[[6,2,3,5],[0,3,1,5],[1,2,1,-1],[1,5,2,-6]] |
3 |
=kmeans(A1,2) |
4 |
=kmeans(A3,A2) |
5 |
=kmeans(A1,2,A2) |
A1 输入训练样本
A2 输入预测样本
A3 以k=2为参数,在样本A1上建立聚类模型,返回模型信息R
A4 使用A3的模型R,对样本A2进行预测返回预测结果,1号、2号和3号样本为一类,4号样本为一类。
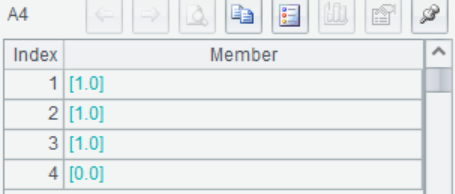
A5 连续进行建模和预测,直接返回预测结果,效果等同于A3+A4

