


在文件上跑 SQL 的 Java 开源包 esProc SPL
esProc SPL是强大的开源计算引擎,可以在csv\txt\xls\xlsx等文件上执行语法符合SQL92标准的SQL语句。
下载、安装、集成
源代码在这里:github.com/SPLWare/esProc,不过从源码编译比较麻烦,官方提供了已经编译好的安装包,可以从c.raqsoft.com.cn/article/1595816810031下载,如果这个链接失效,则可以搜索esProc SPL找到官网下载。
安装之后,在 [安装目录]\esProc\lib下可以找到Java集成需要的3个jar包:
esproc-bin-xxxx.jar esProc SPL及其JDBC驱动包,注意:社区版时使用esproc-xxxx.jar
icu4j_60.3.jar 处理国际化
jdom-1.1.3.jar 解析配置文件
将上述 jar 包引入自己的 Java 项目,就可以通过 JDBC 接口执行 SPL 代码了:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = conn.createStatement();
ResultSet result = statement.executeQuery("=1");
result.next();
int IntResult=results.getInt(1);
上述代码能正常执行,并且在 IntResult 中可以提到结果 1,就说明集成成功了。
规范文件上的SQL
现在就可以用SPL在文件上执行SQL了。
先在格式规范的文件上跑个简单SQL。某csv文件内容:
OrderID,Client,SellerId,Amount,OrderDate
26,TAS,1,2142.4,2009-08-05
33,DSGC,1,613.2,2009-08-14
84,GC,1,88.5,2009-10-16
用 where 语句过滤该文件,Java 代码:
PreparedStatement pstmt = conn.prepareStatement("$select * from d:/Orders.csv where Amount>? and Amount<=?");
pstmt.setInt(1,1000);
pstmt.setInt(2,3000);
ResultSet result =pstmt.executeQuery();
SPL SQL 以 $ 开头,语法和常规 SQL 完全一样,同样可以在语句中用? 传递参数。
查看返回的 result,可以看到计算结果如下:
OrderID |
Client |
SellerId |
Amount |
OrderDate |
26 |
TAS |
1 |
2142.4 |
2009-08-05 |
133 |
HU |
1 |
1419.8 |
2010-12-12 |
43 |
KT |
3 |
2169 |
2009-08-27 |
上面的csv格式比较规范,不需要特殊处理就可以直接执行SQL,类似地,格式规范的txt也可以直接执行SQL。
某txt以tab为分隔符,首行为列名,数据同上。用group by…having…进行分组汇总,SQL如下:
$select year(OrderDate) y,Client,sum(Amount) amt,count(1) cnt from d:/Orders.txt group by year(OrderDate),Client having count(1)>=3
计算结果:
y |
Client |
amt |
cnt |
2009 |
BSF |
13412 |
3 |
2009 |
GAE |
5292 |
4 |
2009 |
GC |
3084.5 |
4 |
格式规范的xls/xlsx,即首行为列名,其他行都是记录,同样可以直接执行SQL。某xls部分内容:
A |
B |
C |
D |
E |
|
1 |
OrderID |
Client |
SellerId |
Amount |
OrderDate |
2 |
26 |
TAS |
1 |
2142.4 |
2009-08-05 |
3 |
33 |
DSGC |
1 |
613.2 |
2009-08-14 |
4 |
84 |
GC |
1 |
88.5 |
2009-10-16 |
用group by…having…进行分组汇总,SQL如下:
$select year(OrderDate) y,Client,sum(Amount) amt,count(1) cnt from d:/Orders.xls group by year(OrderDate),Client having count(1)>=3
计算结果同上。
SQL 92语法内容较多,比如join\case\as\distinct\order by\with子句\from子句\in子句\嵌套子查询以及众多的数学、字符串、日期函数,这里不再一一举例,详情参考在文件上使用 SQL 查询的示例。
文件间计算
SPL SQL可以在相同或不同格式的文件之间进行混合计算,比如交并差集合运算、子查询、关联计算等。某xlsx存储员工记录:
A |
B |
C |
D |
E |
F |
G |
|
1 |
EId |
State |
Dept |
Name |
Gender |
Salary |
Birthday |
2 |
18 |
Florida |
Administration |
Jonathan |
M |
7000 |
1971-03-07 |
3 |
20 |
Florida |
Administration |
Alexis |
F |
16000 |
1977-08-07 |
4 |
26 |
Florida |
Administration |
Timothy |
M |
5000 |
1977-12-24 |
将这个xlsx与前面的订单csv进行关联计算:
$select e.Dept dept,o.CLient client, sum(o.amount) amt from d:/Orders.csv o left join d:/Employees.xlsx e on o.SellerId=e.EId group by e.Dept ,o.Client
计算结果:
dept |
client |
amt |
Administration |
BSF |
2670.4 |
Administration |
DY |
517.8 |
Administration |
GAE |
2008.8 |
写文件
SPL SQL支持select …into…语句,可将计算结果写入文件。比如,对txt分组汇总,结果写入result.csv:
$select year(OrderDate) y,Client,sum(Amount) amt,count(1) cnt into d:/result.csv from d:/Orders.txt group by year(OrderDate),Client having count(1)>=3
打开result.csv,可以看到计算结果:
y,Client,amt,cnt
2009,BSF,13412.0,3
2009,GAE,5292.0,4
2009,GC,3084.5,4
目前可写成 4 种格式规范的文件,csv\txt\xls\xlsx。如果文件已经存在,SPL 会判断数据结构是否一致,一致则追加,不一致无法写入。
不规范文件的计算
SPL SQL也可以计算格式不规范的文件,这就要用到SPL的原生语法了。
txt/csv文件无首行列名,用SQL查询该文件:
$select * from {file("d:/noColName.csv").import@c()} where _4>1000 and _4<=3000
代码中的_4是默认列名,表示第4列,{…}里是SPL的原生语法,具有强大的解析能力和计算能力,仅import函数就可以实现非默认分隔符、非默认格式的数据类型、跳过N行、处理括号引号单引号等功能。
分隔符不是常见的tab,而是双线||,用SQL查询该文件:
$select * from {file("d:/sep.txt").import@t(;,"||")} where Amount>1000 and Amount<=3000
日期类型不是默认的"2012-01-01",而是形如"01-01-2012",用SQL查询该文件:
$select * from {file("style.txt").import@t(orderid,client,sellerid,amount,orderdate📅"dd-MM-yyyy")} where Amount>1000 and Amount<=3000
更多import函数用法参考SPL import函数
不规范的xls/xlsx,同样可以用SPL原生语法配合SQL进行计算。xlsx首行直接是数据:
$select * from {file("D:/Orders.xlsx").xlsimport()} where _4>1000 and _4<=3000
跳过前2行的标题区:
$select * from {file("D:/Orders.xlsx").xlsimport@t(;,3)} where Amount>1000 and Amount<3000
读取名为"sheet3"的特定sheet:
$select * from {file("D:/Orders.xlsx").xlsimport@t(;"sheet3")} where Amount>1000 and Amount<3000
利用xlsimport函数,还可解析更多格式复杂的文件,比如从第M行读到第N行、密码打开xls等,更多用法参考SPL xlsimport函数
复杂格式文件的计算
文件的格式或内容如果更不规范更复杂,就要用更多的SPL原生代码进行预处理,SQL无法调试,虽然可以嵌入更多SPL原生代码但会降低开发效率。这种情况下可以用SPL IDE配合SPL脚本文件:先用多步骤的SPL原生代码进行预处理,再用SQL引用预处理的结果,最后在Java里调用脚本文件。
某文件3行对应1条记录,其中第2行包含3个字段,需要按第4个字段过滤该文件。文件部分内容:
26
TAS 1 2142.4
2009-08-05
33
DSGC 2 613.2
2009-08-14
84
GC1 1 88.5
2009-10-16
首先,执行 [安装目录]\esProc\bin\esproc.exe(Linux\Mac 下为 esproc.sh), 打开 SPL IDE,编辑以下脚本文件:
A |
|
1 |
=file("D:\\threeLines.txt").import@si() |
2 |
=A1.group((#-1)\3) |
3 |
=A2.new(~(1):OrderID, (line=~(2).split@p("\t"))(1):Client,line(2):SellerId,line(3):Amount,~(3):OrderDate) |
4 |
$select * from {A3} where Amount>? and Amount<=?; arg1,arg2 |
在IDE中的样子:
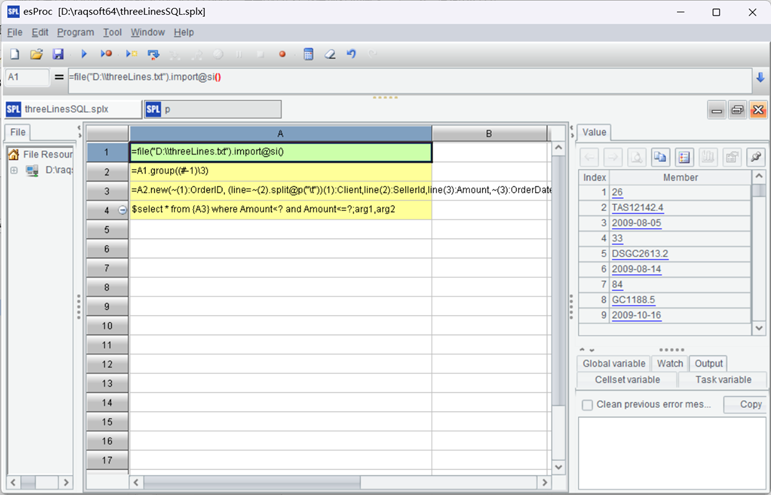
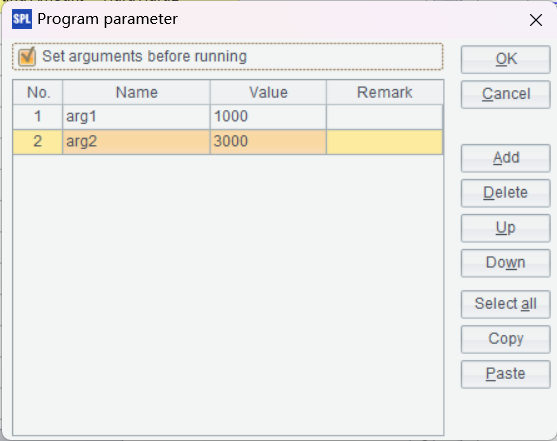
代码中的 arg1、arg1 是参数,可以来自 Java JDBC 或报表工具。通过菜单 Program->Parameter 定义参数,如下:
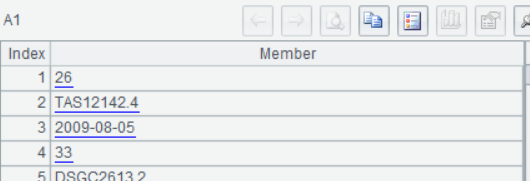
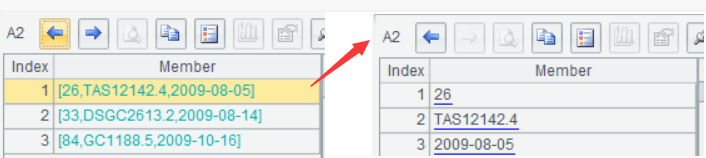
执行或调试脚本后,依次点击 A1-A4,可以在右侧看到每一步的计算结果:
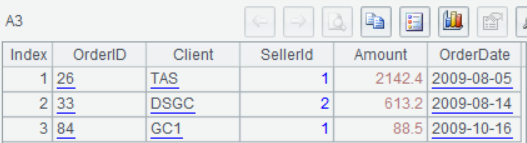
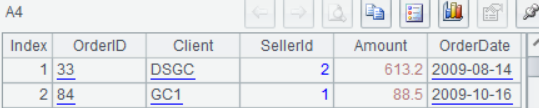
调试之后,就可以在 Java 中调用脚本文件了。将上述 SPL 脚本存为文件 (比如 threeLinesQuery.splx),再在 Java 中以存储过程的形式引用该文件名。
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
CallableStatement statement = connection.prepareCall("{call threeLinesQuery (?,?)}");
statement.setInt(1, 1000);
statement.setInt(2, 3000);
ResultSet result= statement.executeQuery();
脚本中的SPL原生语法可以参考SPL程序设计语言,对于复杂的运算要比SQL更简洁方便。
延伸阅读资料:没有 RDB 也敢揽 SQL 活的开源金刚钻 SPL、开源 SPL 助力 JAVA 处理公共数据文件(txt\csv\json\xml\xls)。

