


SPL 工业智能:原料与产品的拟合
问题提出
工业生产活动的目标是利用原料生产产品,从而产生利润。原料经过一系列加工过程,包括物理反应和化学反应,最终形成产品,生产的理想状态是原料到产品的转换率是确定的,工厂想生产多少产品就知道需要准备多少原料,提高生产效率。
许多工艺原理和生产经验都表明,在简化情况下,可以认为原料用量和产品产量之间近似是线性关系。这样,每一种原料和每一种产品之间都会有一个与原料用量无关的恒定转换率,在化工界称为收率。
我们的目标是根据历史的原料量和产量计算出一个较准确的收率,然后在下一个生产周期(比如第二天)中根据原料用量预测产量,预测产量与实际产量越接近说明收率越准确。如下图:
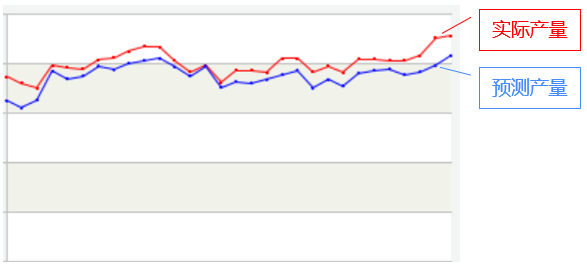
反应在图上,目标就是使两条曲线尽可能重合。
怎么才能算出一个较准确的收率呢?
既然原料用量和产品产量之间近似是线性关系,而线性拟合又是非常成熟的技术,那么很容易想到,直接用历史数据进行线性拟合就可以解决问题了。
可是,现实情况并没有这么简单,由于数据的各种测量误差,直接使用线性拟合算法会得出非常荒唐的结果:
1. 收率大于1,这意味着产品产量大于原料用量,凭空造出很多产品;
2. 收率小于0,这更加离谱,原料越多反而产量越少。
这两种情况显然都违背了质量守恒定律,在现实场景中是不可能发生的,这样拟合出来的收率也没有任何用于预测的意义。
如此看来,原料和产品的拟合并不是完全无条件的,需要满足质量守恒定律,即所有产品产量小于原料用量且不会因原料增多而减少,这要求所有收率必须在[0,1]范围内。
质量守恒定律还要求任一种原料最终都转化成各种产品,不会有没有用掉的原料,也不会凭空产生产品,即各种产品对某一种原料的收率和等于1。
常规的线性拟合算法,只考虑拟合结果与目标最接近,并不考虑这些约束,所以当原始数据有误差时,拟合出荒唐的结果也就不奇怪了。
此外,工艺知识还提供了基础收率,它是个长期均值,直接用它预测“明天” 的产品产量效果很差,好比用年均气温去预测明天气温,显然无效,所以基础收率不能直接使用,只能作为参考,就像预测“明天”气温可以把年均气温作为参考一样,不能偏离特别远,否则即使拟合结果误差很小也不合适用于预测。
综上所述,约束条件有3个,分别是:
约束1:所有收率都在[0,1]范围内。
约束2:各种产品对某一种原料的收率和等于1。
约束3:不可以偏离基础收率太远。
我们的任务是研究如何在这些约束条件下利用原料和产品数据计算出较准确的收率,使其可以用于预测第二天的产量。
算法思路
利用历史数据,考虑用不同的数学方法来满足3个约束条件:
1. 有边界的线性拟合法来满足约束1
我们可以把0和1作为边界,问题就转化成有边界的线性拟合,最优解一定会在边界或者是线性拟合结果处。把问题简单化以后就是我们中学时期解的二元一次函数在指定范围内的最大或最小值问题,如下图:
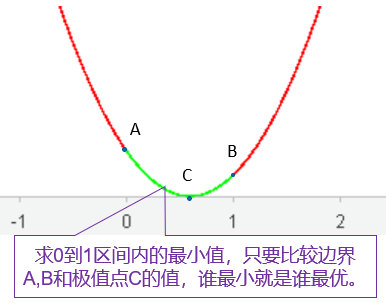
所幸实际生产中原料的种类不会特别多,穷举所有这些情况,最后找到误差最小的解即可满足收率范围在[0,1]内这一约束条件。
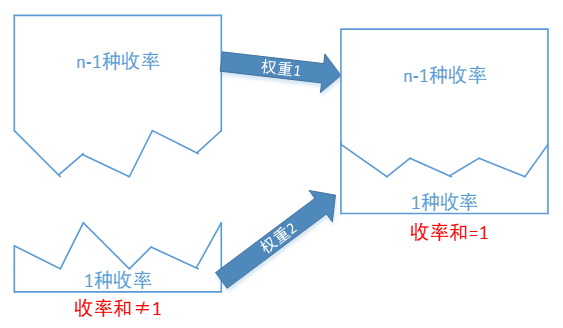
2. 线性变换方法来满足约束2。
n种产品的收率和为1,意味着这些收率线性相关。有边界的拟合方法不能保证收率和不为1,可以将误差按权重线性分拆到各产品上修正收率,反复迭代即可满足收率和为1这一约束条件。如下图:
3. 拟合偏差的方法来满足约束3。
今天的气温和明天差别不大,可以把今天和一年的平均气温之差作为计算明天气温的参考,如下图:
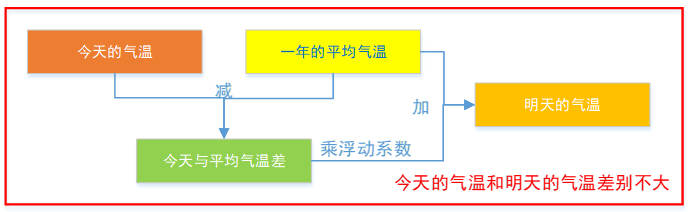
同理,实际生产中,收率同气温一样也是渐变的,即今天的收率和明天的收率差别不会很大,可以把今天的收率和基准收率得到的产品产量之差作为计算明天收率的参考,以此作为有边界拟合时的边界,保证结果收率不偏离基础收率太远。如下图:
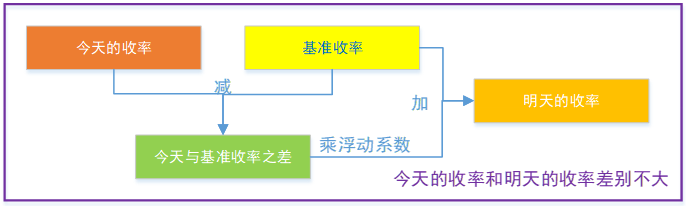
这样得到的收率就可以同时满足三个约束条件,而且准确性也高于基础收率。
实践效果
把上面思路写成代码,就可以计算收率了。
A |
|
1 |
[[30,8],[31,7],[38,10]] |
2 |
[[2,13,23],[3,15,20],[11,13,24]] |
3 |
[[0,0.5,0.5],[0.55,0.05,0.4]] |
4 |
0.1 |
5 |
=mul(A1,A3) |
6 |
=A2.(~--A5(#)) |
7 |
=bd(A1,A2,A3,A4).(~.(~.(round(~,3)))) |
8 |
=A6.~.((idx=#,bdfit(A1,A6.([~(idx)]),A7.(~(idx))).conj())) |
9 |
=transpose(A8) |
10 |
=func(A12,A9,A3) |
SPL提供了很多矩阵计算方法,可以高效的进行矩阵运算,搭配其强大的集合运算能力,可以高效的实现上述算法思路。
计算结果示例:
原料X:
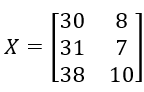
产品Y:

基础收率B:
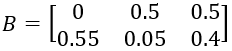
最终的收率W:
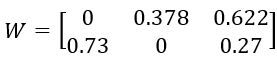
下面是直接用最小二乘法拟合得到的收率W’:
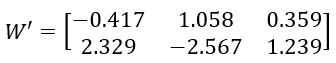
很显然,它的结果有的大于1,有的小于0,完全不满足约束条件,所以无法使用。
通过验证,W满足3个约束条件,为了进一步验证W的准确性,我们用它和基础收率B对比,以均方误差MSE作为评价标准,MSE越小,预测产品产量与实际产量差距越小,收率越准确。
先来看使用基础收率B,各出料的均方误差MSE:
MSE1=12.24
MSE2=16.24
MSE3=8.98
其中MSEj是第j个出料的MSE。
再看使用W,各出料的MSE:
MSE1=10.97
MSE2=5.13
MSE3=3.86
很明显,拟合后的W效果更好。
最后说明一下,本文只介绍优化产品收率的思路,具体的计算过程并没有详细描述。文中的代码也是示意性的,因为有边界的线性拟合、计算边界范围、线性变换等都需要大量的运算,都展示出来只会使文章变的臃肿且晦涩难懂,如果有读者对细节过程感兴趣,可以和我们联系沟通。
开发这类算法常常需要做大量实验来选择合适的函数计算式并调整参数,SPL编程的高效性会发挥巨大的作用,在同样的时间内能够尝试更多种方案。

