"测试数据如下: [图片] 每个人(emp)在某个状态(status)下有开始日期(st)和结束日期 (et)。其中下一个开始日期 = 上一个结束日期 +1, 同一个人的日期段不会有重叠。 现在 .."
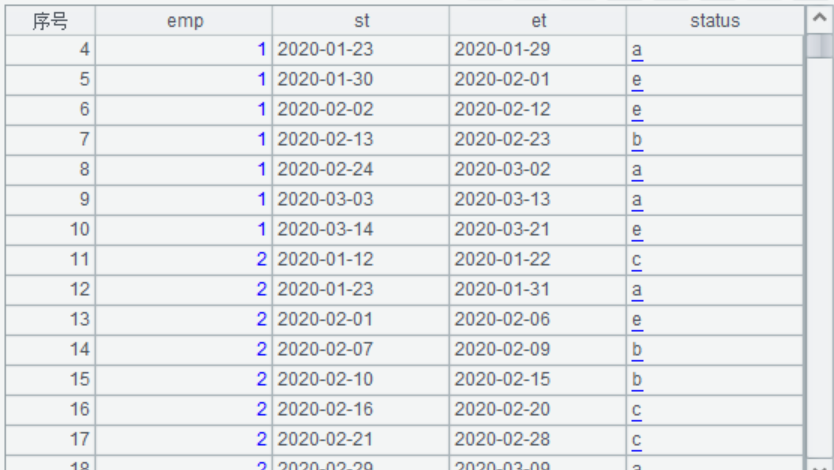
测试数据如下:
每个人(emp)在某个状态(status)下有开始日期(st)和结束日期 (et)。其中下一个开始日期 = 上一个结束日期 +1, 同一个人的日期段不会有重叠。
现在要统计:指定时间段(如一年)内,每天各种状态下有多少人。
已尝试将 st 到 et 的日期补齐(新增相差天数条记录),然后 groups@m(日期,status;count(emp)), 但效率似乎不是很高。请教一下 SPL 还有没有更优实现。
如果状态都是 abcde 这种容易序号化的东西 ,比如总共 5 种。假设日期都在一年内(第一天是 2020-1-1)
大概这样算:d0=date(“2020-1-1”)a0=asc(‘a’)-1A=366.([0]*5 )T.run(i=asc(status)-a0, s=st-d0, (et-st+1).run(A(s+~)(i)+=1 ) )A.news(~; d0+(A.#-1): 日期, char(a0+#):status, ~ )可能要调试一下里面的表达式,没测试。
类似 groups@n,但把一条记录变多条会消耗时间,所以直接算。
不好意思,测试数据是随便生成的,真实的 status 是个字符串,不过种类的确是固定的
["kllnv","qubdi","rpvgw","tmnmu","vorny"] =file("info.csv").import@cqt() =d0=date("2000-01-01") =A=366.([0]*5) =A2.run(i=A1.pos@b(status),s=st-d0,(et-st+1).run(A(s+~)(i)+=1)) =A.news(~;d0+(A.#-1):日期,A1(#):status,~)





如果状态都是 abcde 这种容易序号化的东西 ,比如总共 5 种。假设日期都在一年内(第一天是 2020-1-1)
大概这样算:
d0=date(“2020-1-1”)
a0=asc(‘a’)-1
A=366.([0]*5 )
T.run(i=asc(status)-a0, s=st-d0, (et-st+1).run(A(s+~)(i)+=1 ) )
A.news(~; d0+(A.#-1): 日期, char(a0+#):status, ~ )
可能要调试一下里面的表达式,没测试。
类似 groups@n,但把一条记录变多条会消耗时间,所以直接算。
不好意思,测试数据是随便生成的,真实的 status 是个字符串,不过种类的确是固定的