


SPL:多对多连接
连接(JOIN)用于把来自两个或多个表的记录结合起来。本文将探讨对于连接问题,SPL 的解决方案和基本原理。
表之间存在的数据相互依赖关系,就叫做表间关联关系。表间关联关系可以分为以下几种:一对一、多对一、一对多和多对多。我们可以通过表间关联关系,把两个或多个表连接起来,从而实现多表关联查询的目的。
多对多关联:表 A 的一条记录能够对应表 B 中的任意条记录;同时表 B 中的一条记录也能够对应表 A 中的任意条记录。
处理多对多关联关系,可以使用交叉连接。表 A 的每条记录都会与表 B 的所有记录组成一个新的记录,所以返回结果集的行数等于两个表行数的乘积。在 SPL 中提供了函数 xjoin() 用于交叉连接。多对多关联关系在实际应用中很少遇到。我们通过矩阵乘法的例子简单介绍一下:
【例 1】 求两个矩阵的乘积。两个矩阵表数据分别存储在 MATRIXA 和 MATRIXB 中:
MATRIXA:
ROW |
COL |
VALUE |
1 |
1 |
1 |
1 |
2 |
2 |
1 |
3 |
3 |
2 |
1 |
4 |
2 |
2 |
5 |
2 |
3 |
6 |
MATRIXB:
ROW |
COL |
VALUE |
1 |
1 |
1 |
1 |
2 |
4 |
2 |
1 |
2 |
2 |
2 |
5 |
3 |
1 |
3 |
3 |
2 |
6 |
本例的数学公式如下:
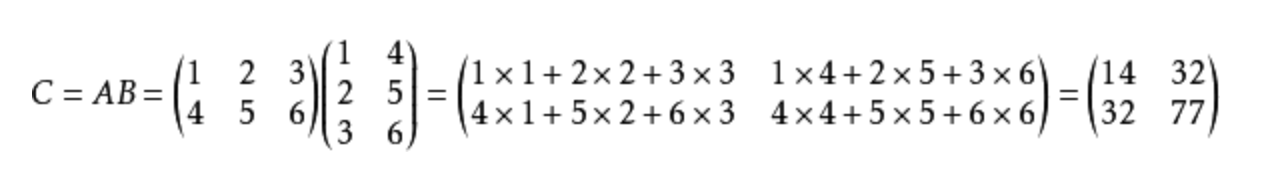
矩阵乘法是多对多的关系,SPL 提供了函数 xjoin() 用于交叉连接。
SPL脚本如下:
A |
|
1 |
=T("MatrixA.csv") |
2 |
=T("MatrixB.csv") |
3 |
=xjoin(A1:A; A2:B, A.COL==A2.ROW) |
4 |
=A3.groups(A.ROW, B.COL; sum(A.VALUE * B.VALUE):VALUE) |
A1:导入矩阵表 A。
A2:导入矩阵表 B。
A3:使用函数 xjoin() 进行交叉连接,在连接的同时按照条件过滤。
A4:分组汇总相同行列号的值的乘积之和。
连接条件不是等值比较时,称为非等值连接。比如年龄是否在某个年龄区间内,收入是否在某个收入区间内等等。
【例 2】 根据社区居民表和年龄区间表,查询社区居民所处的年龄段。部分数据如下:
COMMUNITY:
ID |
NAME |
AGE |
1 |
David |
28 |
2 |
Daniel |
15 |
3 |
Andrew |
65 |
4 |
Rudy |
|
… |
… |
… |
AGE_GROUP:
GROUP_NAME |
START |
END |
Children |
0 |
15 |
Youth |
16 |
40 |
Middle |
41 |
60 |
Old |
61 |
100 |
在社区居民表中,有的居民没有登记年龄,所以本例可以在交叉连接时通过左连接来实现。函数 xjoin() 用于交叉连接,选项 @1 时使用左连接。
SPL脚本如下:
A |
|
1 |
=T("Community.txt") |
2 |
=T("AgeGroup.txt") |
3 |
=xjoin@1(A1:C; A2:A, A2.START<=C.AGE && A2.END>=C.AGE) |
4 |
=A3.new(C.ID, C.NAME, C.AGE,A.GROUP_NAME) |
A1:导入社区居民表。
A2:导入年龄区间表。
A3:使用函数 xjoin@1() 按照第一个表左连接,在连接的同时选出年龄在相应区间内的记录。当年龄区间无法匹配时保留社区居民记录,年龄段置为空。
A4:返回社区居民所处的年龄段。


英文版