1.20 有序:用相邻区间筛选
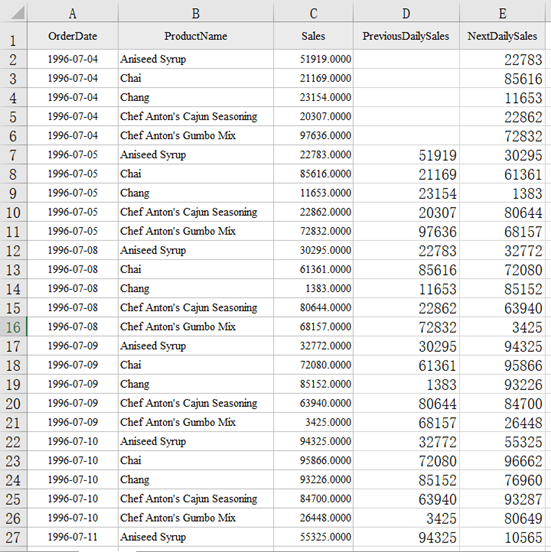
有如下产品日销售额表:
| OrderDate | ProductName | Sales |
|---|---|---|
| 1996-07-04 | Aniseed Syrup | 51919.0000 |
| 1996-07-04 | Chai | 21169.0000 |
| 1996-07-04 | Chang | 23154.0000 |
| 1996-07-04 | Chef Anton’s Cajun Seasoning | 20307.0000 |
| 1996-07-04 | Chef Anton’s Gumbo Mix | 97636.0000 |
| … | … | … |
需要增加 PreviousDailySales 和 NextDailySales 两个列,分别填写上一个销售日和下一个销售日当前产品的销售额。
问题分析:数据是先按日期排序,后按产品排序的,如果把产品相同的行视为一个组,则问题转变为同一组内取上一行和下一行的值。问题的难点在于如何不改变记录顺序的情况下去找同一组内的上一行和下一行
实现思路有两种:
1、 在相邻区间内查找和筛选:不改变数据的顺序,直接往前找和往后找,找到第一条同名产品的记录,就是上一个销售日 / 下一个销售日的销售额。
| A | |
|---|---|
| 1 | =T(“ProductDailySales.xls”) |
| 2 | =A1.derive(~[:-1].select@1z(ProductName==A1.ProductName).Sales:PreviousDailySales, ~[1:].select@1(ProductName==A1.ProductName).Sales:NextDailySales) |
A2 ~[:-1] 表示从开头到上一行为止的所有记录集合,~[1:] 表示从下一行到结束的所有记录集合
2、 取同分类内的相邻行值:把数据按产品分组,组内直接取上一行的值和下一行的值,就是上一个销售日 / 下一个销售日的销售额。
| A | |
|---|---|
| 1 | =T(“ProductDailySales.xls”).derive(:PreviousDailySales,:NextDailySales) |
| 2 | =A1.group(ProductName).run(~.run(PreviousDailySales=Sales[-1], NextDailySales=Sales[1])) |
| 3 | return A1 |
A2 Sales[-1] 表示上一行的 Sales 字段值,Sales[1] 表示下一行的 Sales 字段值
运行结果: