


SPL:访问 InfluxDB
InfluxDB是时序数据库,数据存储在它的bucket中,多个bucket又组成一个organization。每条数据由measurement、多个维度、多个字段值、时间戳构成:
airSensors, sensor_id=TLM0201 temperature=73.97038159354763, humidity=35.23103248356096, co=0.48445310567793615 1647607324916
InfluxDB针对这些时序数据提供了一系列的查询操作,但因为数据结构不同于关系数据库,复杂计算能力有限,不得不把数据取出来进行库外计算时,用计算引擎SPL语言会比较方便,它提供了一些函数通过调用InfluxDB Java API读写其数据;也提供了Influx2_rest()函数调用InfluxDB Restful API,这些API中的查询参数、结果数据大多以csv、json格式组织,SPL中有json()、csvStr.import()等函数容易加载这些格式的数据,加载成SPL序表后,就容易做各种数据变换、计算了。
InfluxDB Java API有1.x、2.x两个版本,SPL针对它们提供了不同的函数。
Java API for InfluxDB1.x
创建/关闭InfluxDB连接
使用方式类似关系数据库的JDBC连接,SPL也用成对的“创建/关闭”方式连接InfluxDB。
influx_open(url,database,retentionPolicy, username,password),参数依次为服务器地址、数据库名、保留策略、登录的用户名、密码。
influx_close(influxConn),influxConn是要关闭的InfluxDB连接。
示例:A1创建连接,中间做一些读写及计算操作后,A3关闭A1创建的连接
A |
|
1 |
=influx_open("http://127.0.0.1:8086", "esprocDB", "autogen", "admin", "admin") |
2 |
…… |
3 |
=influx_close(A1) |
向InfluxDB写入
influx_insert(influxConn, rows),rows是由多行待写入数据组成的SPL序列,如下A2中是待写入数据,A3执行写入:
A |
|
2 |
splTable,location=santa_monica,direct=5 water_level=2.064 1566086400000000000 splTable,location=beijing,direct=3 water_level=1.6 1568086400000000000 splTable,location=beijing,direct=7 water_level=5.5 1606086400000000000 |
3 |
=influx_insert(A1, A2.split("\n")) |
查询InfluxDB数据
influx_query(influxConn,InfluxQL),InfluxQL 是 Influx 的查询语言:
A |
|
4 |
=influx_query(A1, "SELECT * FROM splTable") |
5 |
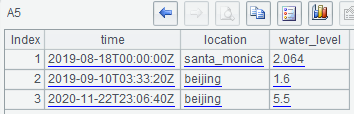
=influx_query(A1, "SELECT location::tag,water_level FROM splTable") |
6 |
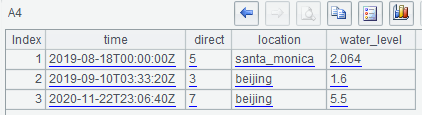
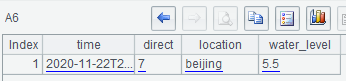
=influx_query(A1, "SELECT * FROM splTable where location ='beijing'AND time >'2020-01-01'") |
A4查询结果:
A5只选出location标签字段、water_level值字段:
A6查询时对location、time设置查询条件:
Java API for InfluxDB2.x
支持InfluxDB2.x的函数都是以influx2_开头。
创建/关闭InfluxDB连接
使用方式类似关系数据库的JDBC连接,SPL也用成对的“创建/关闭”方式连接InfluxDB。
influx2_open(url),url中,除了服务器地址、端口,还可以有organization、bucket、认证身份的token、一些超时参数等。
influx2_close(influxConn),influxConn是要关闭的InfluxDB连接。
示例:A1创建连接,中间做一些读写及计算操作后,A3关闭A1创建的连接
A |
|
1 |
=influx2_open("http://localhost:8086?org=esprocOrg&bucket=test1&token=ZHL...fxWg==") |
2 |
…… |
3 |
=influx2_close(A1) |
向InfluxDB写入
influx2_write(influxConn, rows),rows是由多行待写入数据组成的SPL序列,如下A2中是待写入数据,A3执行写入:
A |
|
2 |
temperature,location=west value=51.0 temperature,location=north value=52.0 temperature,location=south value=53.0 |
3 |
=influx2_write(A1,A2.split("\n")) |
查询InfluxDB数据
influx2_query(influxConn,FluxQL),FluxQL 是 Influx 的查询语言:
A |
|
4 |
=influx2_query(A1,"from(bucket:\"test1\") |> range(start: 0)") |
返回的结果可能有多个结构不同的序表,如上面A4查询得到两个序表:
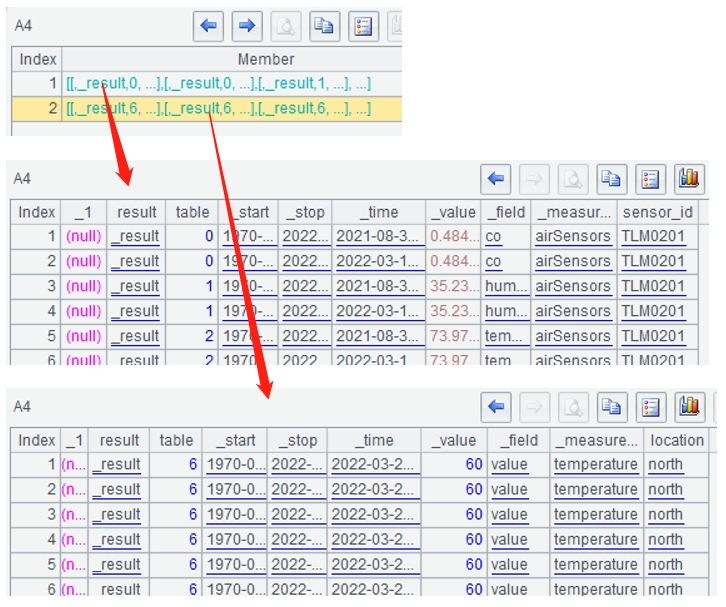
删除InfluxDB数据
influx2_delete(influxConn,beginTime,endTime,deleteStatement,bucket,organization), 参数中设置待删除数据的起止时间、查询语句、bucket 以及 organization:
A |
|
5 |
=influx2_delete(A1,"2022-03-30 01:01:01","2022-03-31 01:01:01","","test1","esprocOrg") |
Restful方式
influx2_rest(influxUrl, method, content; httpHeader1, httpHeader2, …),第一个参数是链接地址;第二个参数是HTTP method,值可能是GET/PUT/POST/DELETE/PATCH;第三个参数是HTTP请求提交的内容,但也有些操作不提交任何内容,这个参数就可以省略。分号后面是多个HTTP header,是验证身份的token、指明内容格式等一些信息。每种Rest的HTTP请求,使用哪种method,提交什么内容,设置哪些HTTP header,这些细节参考其官网《InfluxDB API》。
示例:
A |
|
1 |
>token="ZHLnRWh3GsIdALAx0……1nV5ufxWg==" |
2 |
=influx2_rest("http://localhost:8086/api/v2/buckets", "GET"; "Authorization: TOKEN"+token) |
3 |
=json(A2.Content) |
4 |
=A3.buckets.new(type,name,retentionRules.everySeconds,links.org) |
5 |
=A4.select(type=="user") |
6 |
|
7 |
airSensors,sensor_id=TLM0201 temperature=73.97038159354763,humidity=35.23103248356096,co=0.48445310567793615 1647607324916 airSensors,sensor_id=TLM0202 temperature=75.30007505999716,humidity=35.651929918691714,co=0.5141876544505826 1647607324916 |
8 |
=influx2_rest("http://localhost:8086/api/v2/write?org=esprocOrg&bucket=test1&precision=ms", "POST", A5; "Authorization: TOKEN"+token, "Content-Type: text/plain; charset=utf-8","Accept: application/json") |
9 |
|
10 |
from(bucket:"test1") |> range(start: -240h) |
11 |
=influx_rest("http://localhost:8086/api/v2/query?org=esprocOrg", "POST", A8; "Authorization: TOKEN"+token, "Content-type: application/vnd.flux","Accept: application/csv") |
12 |
=A9.Content.import@t(;",") |
A1中是用户认证的token,之后的influx操作都会用到它;
A2查询所有的bucket,HTTP响应的信息都会列出来,返回的多个bucket信息在Content字段中,是一个json格式的字符串:

A3用json()函数把json字符串转换成SPL序表,这个序表和json嵌套的层次是一样的:
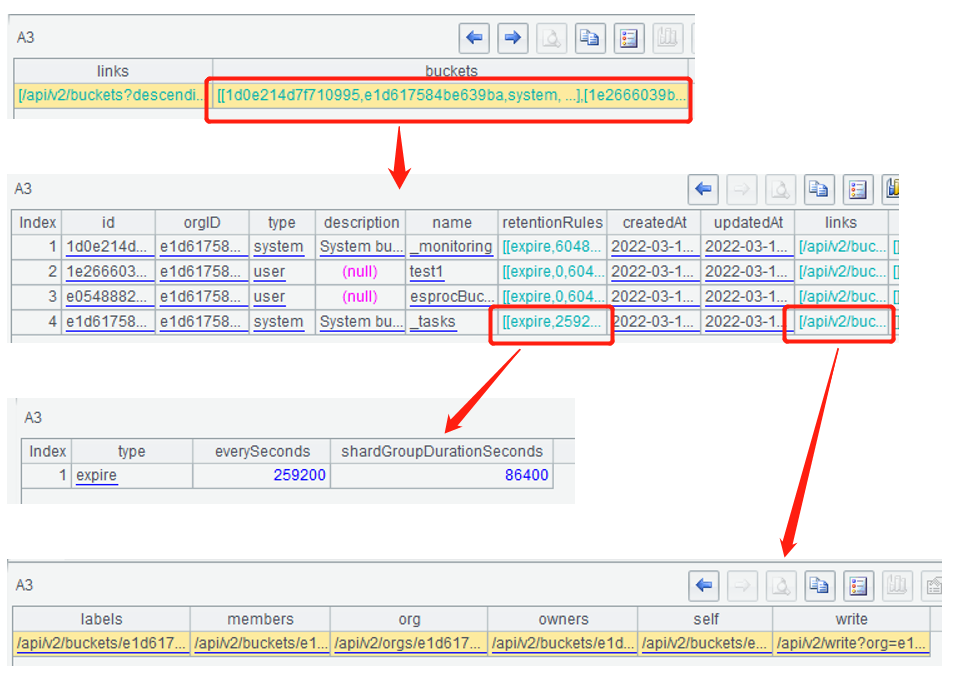
A4从A3的嵌套序表中选出一些需要的信息,组成一个简单序表,
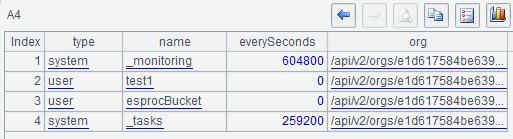
A5用select()函数过滤出user类型的bucket: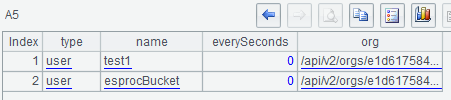
只要把数据加载成SPL序表,再做过滤、分组、排序,集合交并等等操作就都容易了。
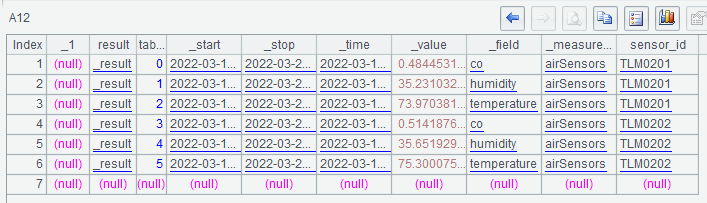
A7是待写入的数据,A8执行write操作。A10定义InfluxDB查询语句,A11执行A10的查询,得到的结果是csv格式串:

A12用import()函数把csv字符串转换成SPL序表:


英文版