


SPL 预计算机制
部分预汇总
多维分析后台的运算本质是分组汇总,可以直接对数据执行这个计算。但是,当数据量非常大的时候,很难做到即时响应。
预汇总是个容易想到的办法,即事先把各种汇总结果计算好,保存为中间结果(我们在后面称为 cube),前端应用请求时就可以直接查找 cube 返回结果。
例如,对下图 1 中的订单表做预汇总:
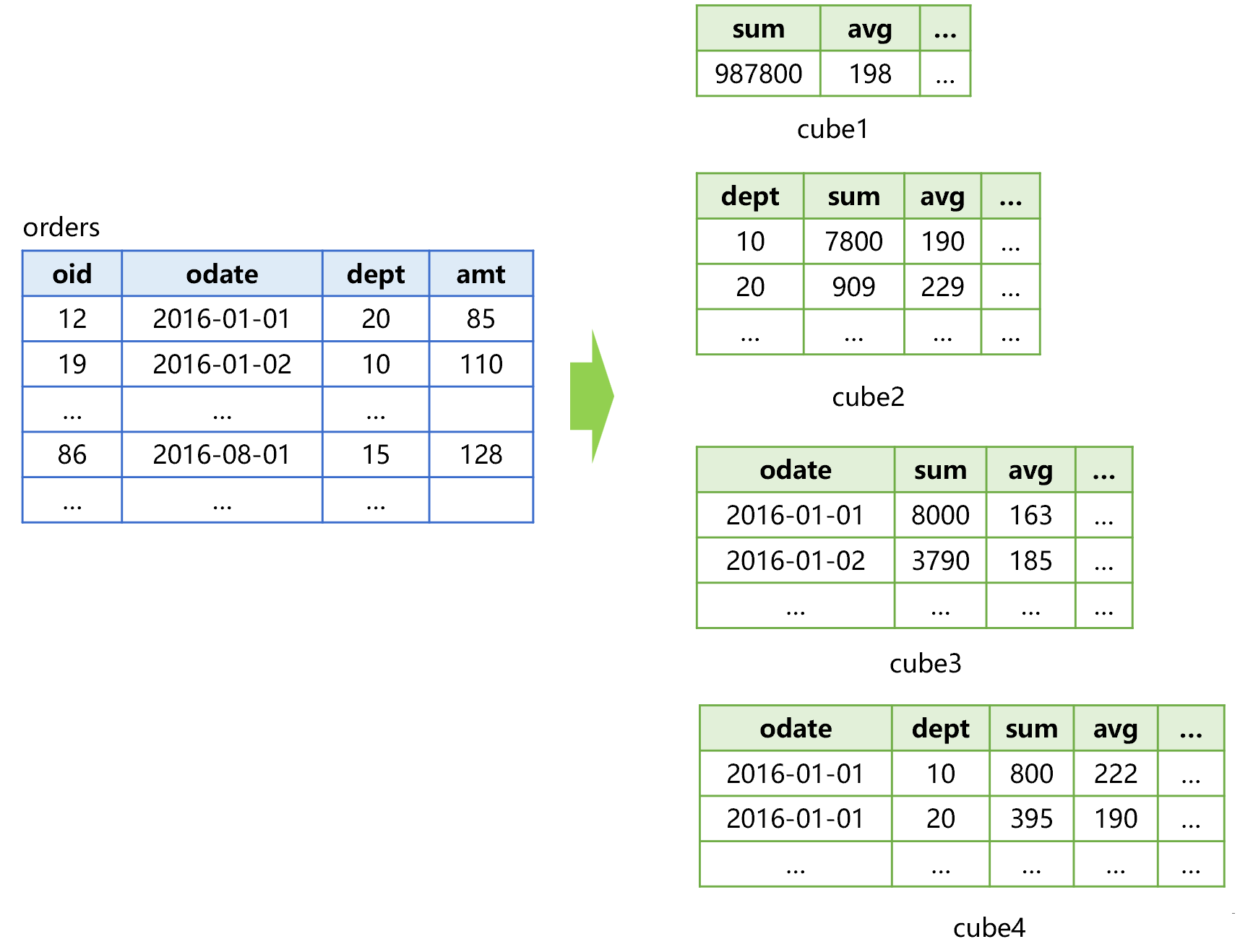
图 1 订单表的预汇总
图 1 中,订单表按照日期和部门两个维度,组合出 22=4 个中间结果 cube。每个中间结果都计算好金额的求和、平均、计数等等预汇总值。4 个 cube 包含了全部两个维度的所有组合,我们称为全量预汇总。
预汇总实际上是在用空间换时间。也就是说,中间结果虽然占用了更多的存储空间,但是,这样做将遍历问题转化为查找问题,理论上就可以做到即时响应了。
例如:要计算 dept 为 20 的部门在 2016-01-01 的订单总金额,直接查找 cube4 就可以了;要按照日期统计订单金额、平均值等,只要读取 cube3 就可以了。
不过,在实际应用中全量预汇总基本上是不可行的,简单计算一下就能知道。
50 个维度做全量预汇总,需要 250 个 cube,保守估算也要上百万 T 的容量,这就没有可操作性了。即使只预汇总其中 10 个维度(分组维度加切片维度,10 个不算多了),也仍然需要数百 T 以上存储空间,实用性很差。
SPL 提供部分预汇总机制,只预汇总部分维度的组合。前端有请求时,寻找某个条件预汇总数据再来汇总。上面讲到的订单表,部分预汇总可以采用下图 2 这样的方案:
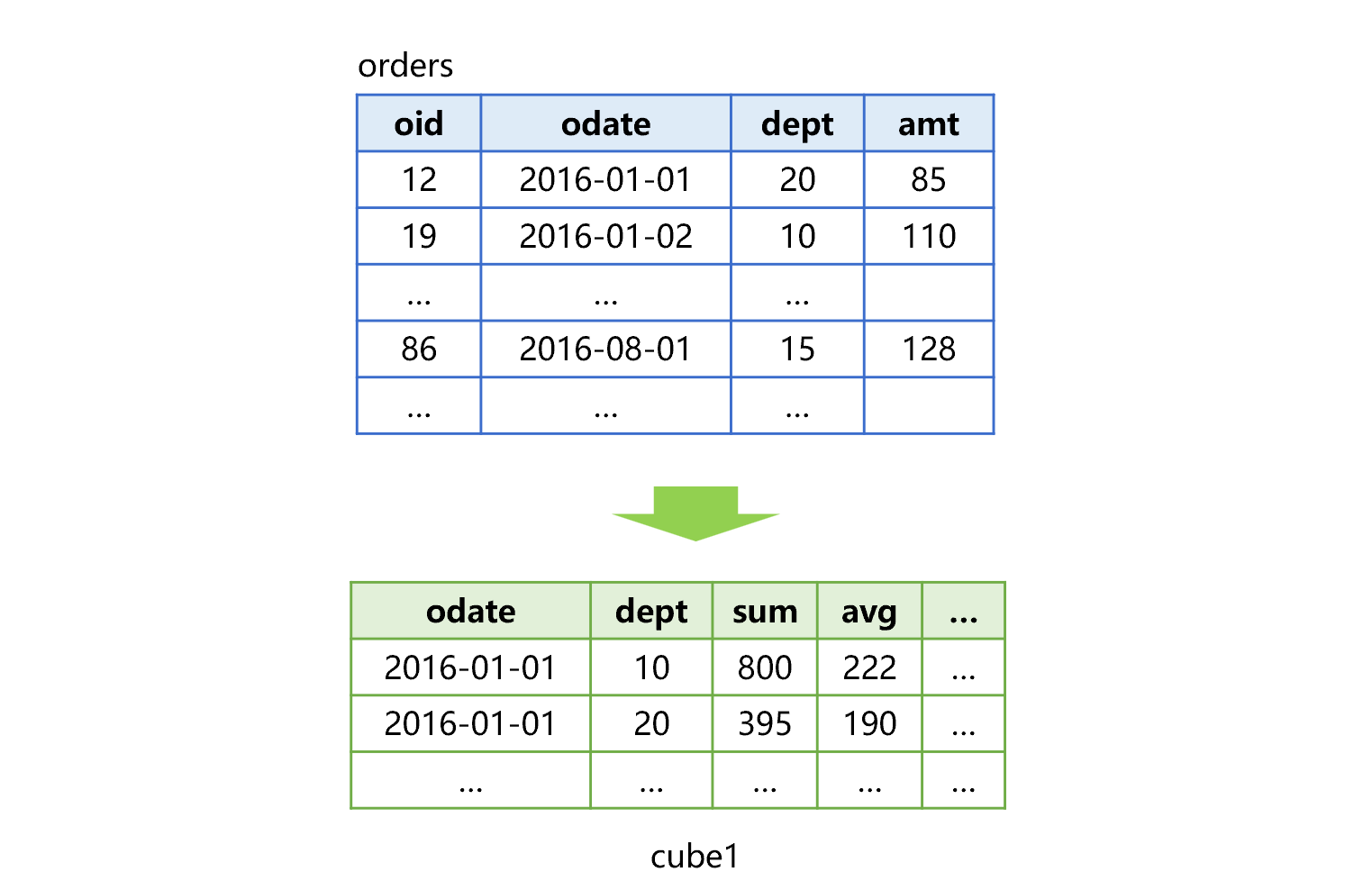
图 2 订单表部分预汇总
图 2 中,预先只生成一个中间结果 cube1。如果要计算 dept=20 的部门在 2016-01-01 的订单金额,还是直接查找 cube1 就可以了。但是,按日期统计订单金额、平均值时,就要在 cube1 基础上,再按日期做一次分组汇总。
部分预汇总相比全量预汇总占用的存储空间大大减少,但却可以把性能平均提高数十倍,也常常能满足要求了。
实际应用中,SPL 可以根据需要建立多个预汇总的中间结果。例如,数据表 T 有 A、B、C、D、E 五个维度。根据业务经验,我们预先计算出来了几个最常用的中间结果,如下图 3:
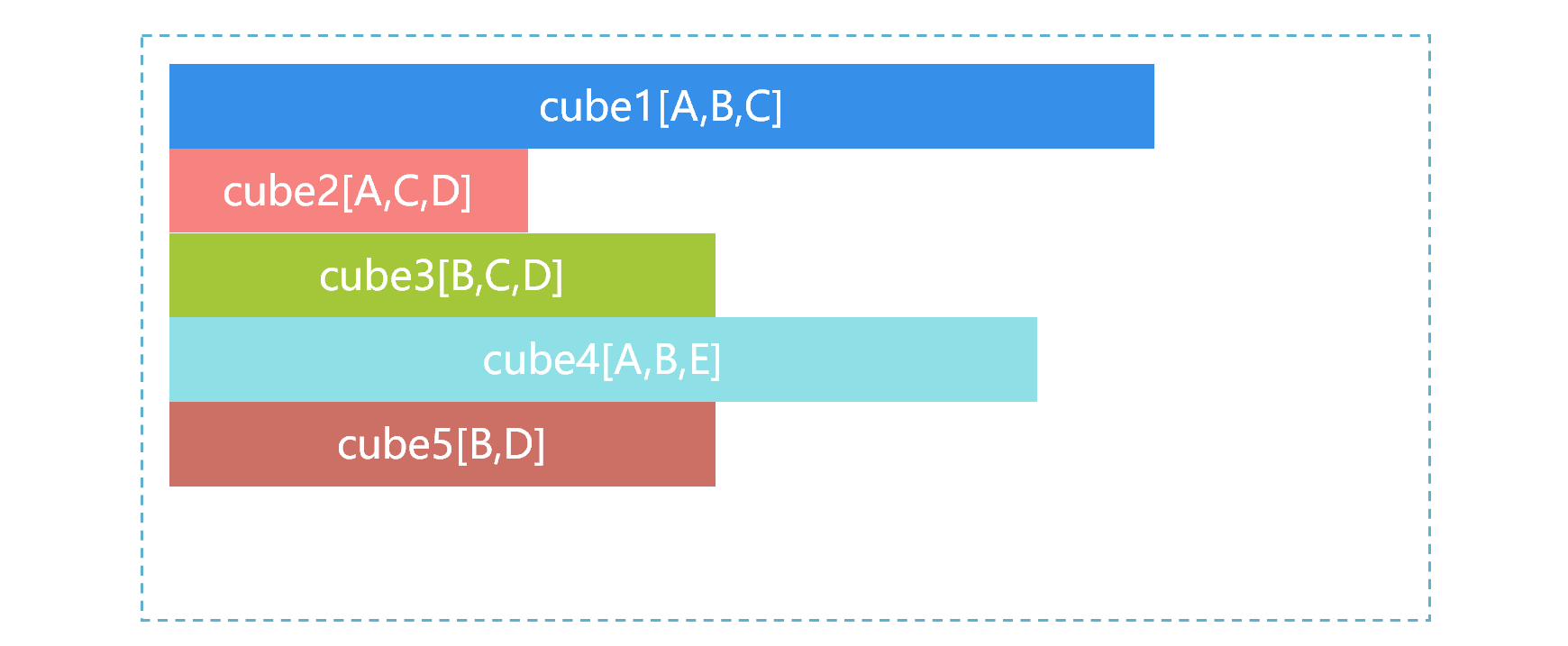
图 3 多个预汇总中间结果
图 3 中,cube 占用存储空间的大小用条形长度来表示,cube1 最大,cube2 最小。
这时候,前端应用来了一个请求,要按照 B、C 做统计汇总。这时 SPL 对多个 cube 自动选择的过程大致是下图 4 这样:
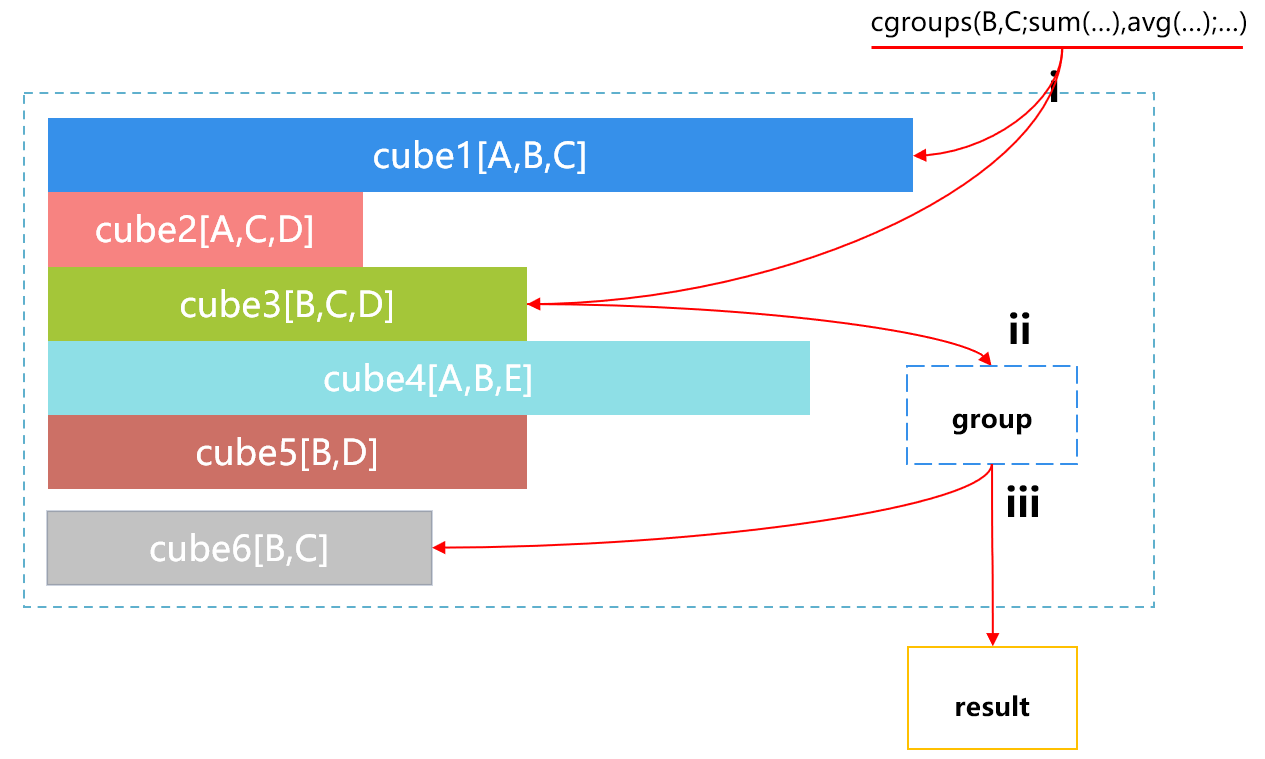
图 4 SPL 对多个 cube 的选择
图 4 中第 i 步,SPL 会自动找到可以利用的 cube 是 cube1 和 cube3。第 ii 步,SPL 发现 cube1 比较大,就会自动选择比较小的 cube3,并在其基础上按 B、C 做分组汇总。第 iii 步,返回结果。
如果将返回的结果保存下来,以后再碰到 B、C 做分组汇总,就可以直接用了。但是 SPL 无法判断是否需要保存,程序员要自行判断实现。类似的,还可以自行实现其他的工程手段,比如记录历史查询请求后统计分析,及时删除不常用的 cube 等。
SPL 预先计算 cube 的代码大致是这样的:
A |
|
1 |
=file("T.ctx").open() |
2 |
=A1.cuboid(file("1.cube"),A,B,C;sum(…),avg(…),…) |
3 |
=A1.cuboid(file("2.cube"),A,C,D;sum(…),avg(…),…) |
… |
使用 cuboid 函数可建立预汇总数据,需要起个名字 ,剩下的参数就和分组汇总一样了。
使用时也很简单:
A |
|
1 |
=file("T.ctx").open() |
2 |
=A1.cgroups(B,C;sum(…),avg(…);file("1.cube"),file("2.cube"),...) |
cgroups 函数会按上述的逻辑自动寻找最合适的预汇总数据再计算。
预汇总方案很简单,但受限于容量,其应用局限也很多,只能应对最常见的情况。
时间段预汇总
对于时间段上的统计,SPL 提供专门的时间段预汇总机制。
例如,订单表已经有一个按照日期 odate 预汇总的 cube1,那么我们可以在此基础上再增加一个按月预汇总的 cube2,如下图 5:
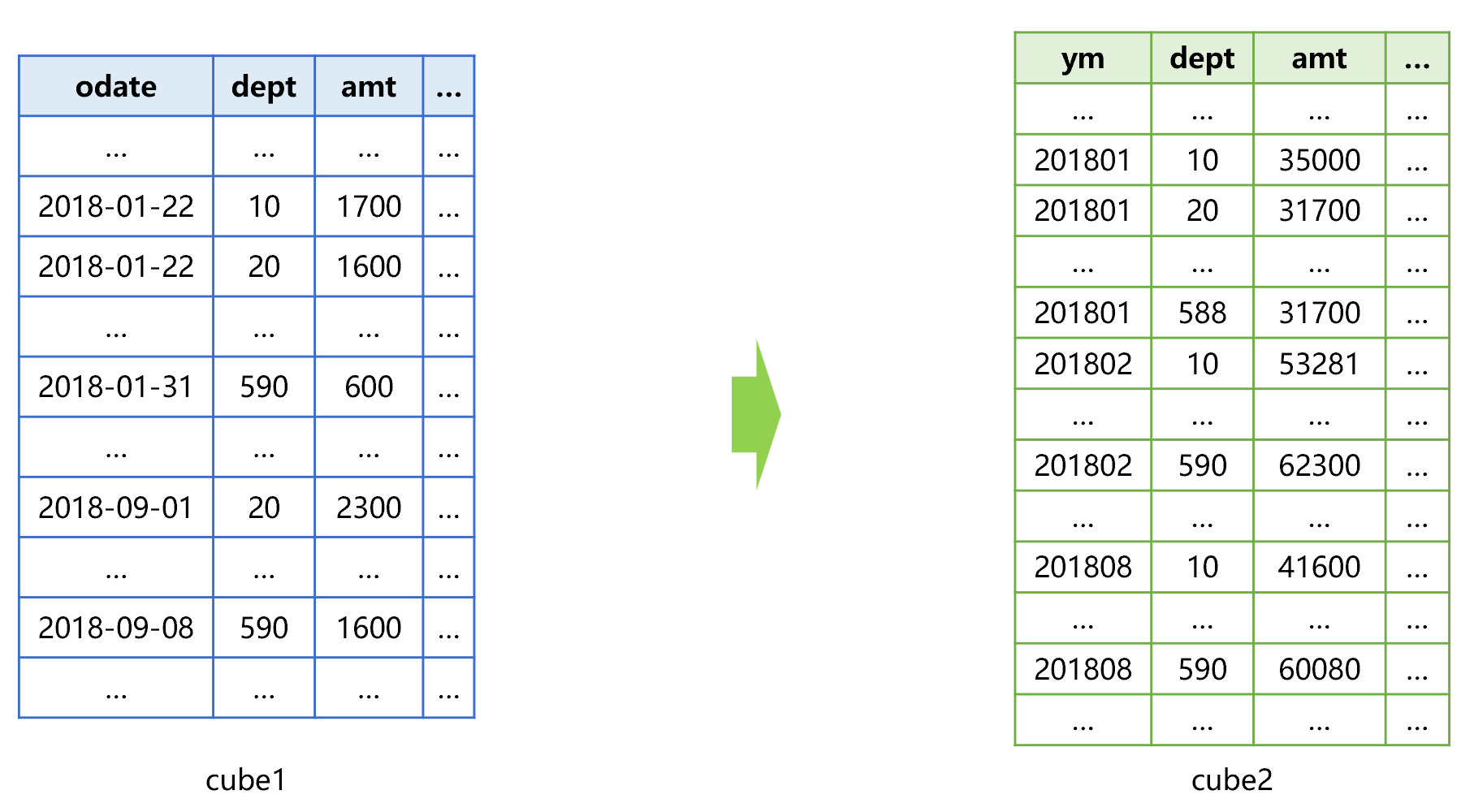
图 5 增加一个按月预汇总的 cube2
SPL 不仅能将 cube2 用于按月汇总提速,也可以用于更细粒度的时间区间汇总。比如说,要按照 dept 分组计算 2018 年 1 月 22 日到 9 月 8 日的金额汇总值,大致过程是下图 6 这样:
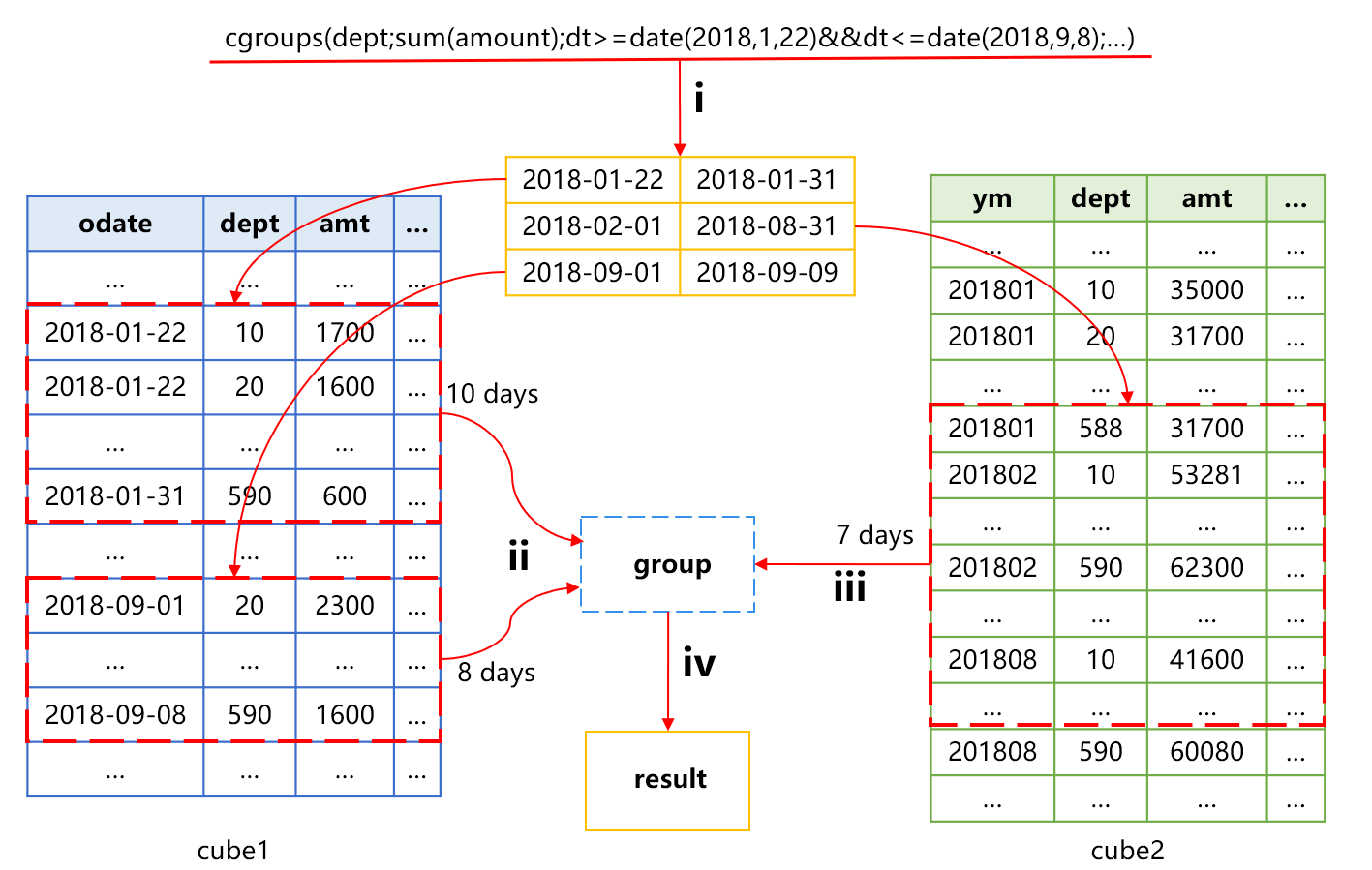
图 6 时间段预汇总机制
图 6 中第 i 个动作,将时间分成三段。第 1 段是开头 10 天,第 2 段是中间 7 个整月,第 3 段是结尾 8 天。
第 ii 个动作,使用 cube1 计算第 1、3 段的聚合值,包含 18 天的数据。我们假设每天包含的 dept 个数平均值是 m,则涉及到的数据量是 18*m 条记录。
第 iii 个动作,基于 cube2 计算第 2 段的汇总值,包含 7 个整月数据。每个整月平均记录数应该也接近 m,涉及的计算量就是 7*m 条记录。
第 iv 个动作,用已经得到的结果再做分组汇总。
这样做共涉及计算量是 18*m+7*m=25*m 条。如果直接使用 cube1 聚合,其计算量是从 1 月 22 日到 9 月 8 日共 223*m 条。所以,采用时间段预汇总机制,计算量几乎减少了 10 倍。
SPL 实现时间段预汇总机制的代码,大致是下面这样:
A |
|
1 |
=file("orders.ctx").open() |
2 |
=A1.cuboid(file("day.cube"),odate,dept;sum(amt)) |
3 |
=A1.cuboid(file("month.cube"),month@y(odate),dept;sum(amt)) |
4 |
=A1.cgroups(dept;sum(amt);odate>=date(2018,1,22)&&dt<=date(2018,9,8);file("day.cube"),file("month.cube")) |
cgroups 函数增加了条件参数,SPL 发现有时间段条件和更高层次的预汇总数据,则会使用时间段预汇总机制来减少运算量。本例中,就会分别从 cube1 和 cube2 中读取相应数据再来汇总。
冗余排序
没有任何切片过滤条件时,汇总运算涉及全量数据。如果也找不到合适的 cube,就没办法减少计算量了。但是,有过滤条件时,如果数据能合理组织,即使没有合适的 cube,也可以想办法避免遍历所有数据。
简单在维度上建立索引会有些作用,但并不会太好。索引能够迅速定位满足条件的记录,但如果这些记录的物理存储位置并不连续,那么读取时仍然会有很多浪费,在目标数据过于分散时,未必比全遍历好多少。因为多维分析运算中,即使切片后要读出的数据量也常常很大,索引主要的应用场景还是选出少量数据。
如果数据存储时对某个维度有序,则可以用该维度的切片条件把目标数据限定在一个连续的存储区域,就不必遍历所有数据了,读取量就能有效减少。但是,理论上每个维度都可能有切片条件,如果把数据按每个维度都排序,那就要被复制若干倍,这样的存储成本就有些高了。
SPL 提供冗余排序机制,既可以减少占用的存储空间,又可以避免遍历所有数据。例如,T 表有 10 个维度,SPL 采用两种方式排序存储,大致是下图 7 的样子:
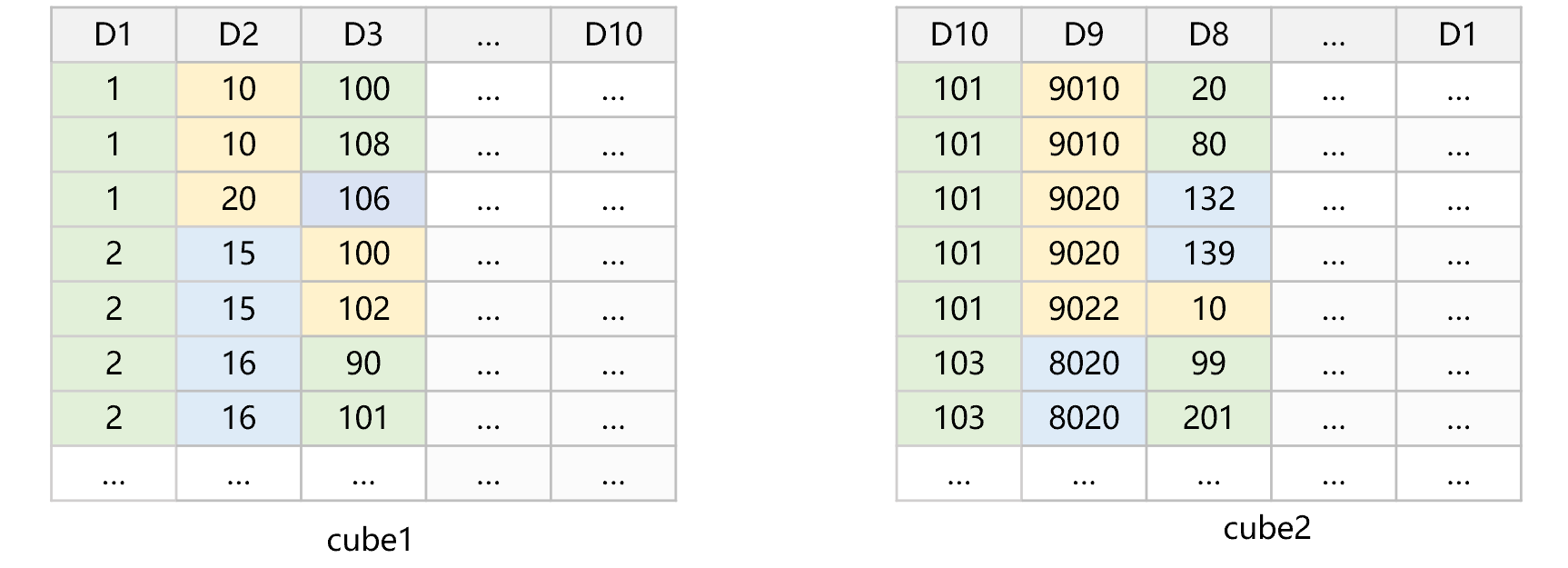
图 7 冗余排序
图 7 中,维度按照 D1,D2,…,D10 排序存储成 cube1,再按照 D10,D9,…,D1 排序存储成 cube2。这两个 cube 中,排序维度列表中越靠前的维度,过滤后数据的物理有序程度就越高。比如 cube2 中的 D10 最靠前,过滤后数据都能连成一片区域。而 D9、D8 比较靠前,虽不能连成一片区域,但也是由一些相对较大的连续区域构成的。
对于任何维度 D,总能有一个数据集使 D 在其排序维度列表中的前半部分。例如,我们要对 D7 做切片过滤。SPL 发现 D7 在 cube2 的排序维度列表中更靠前,则会自动选择 cube2。
当有多个维度上都有切片计算时,SPL 会选择切片后范围和总取值范围相比较小的维度,这样做可以让过滤后的数据量更小。
比如 D8、D6、D4 都要切片,SPL 发现 D8 在 cube2 排序维度列表中最靠前,就会选择 D8 的切片条件来筛选,D6、D4 上的条件则仍然用遍历计算。这是因为,多维分析时某一个维度上的切片,常常都能使涉及数据量减少数倍或数十倍,在其它维度上再利用切片条件的意义就不大了,实现难度却很大。
SPL 实现冗余排序的代码大致如下:
A |
|
1 |
=file("T.ctx").open() |
2 |
=A1.cuboid(file("1.cube"),D1,D2,…,D10;sum(…)) |
3 |
=A1.cuboid(file("2.cube"),D10,D9,…,D1;sum(…)) |
4 |
=A1.cgroups(D2;sum(…);D6>=230 && D6<=910 && D8>=100 && D8<=10 &&…;file("1.cube"),file("2.cube")) |
A2、A3 中,cuboid 针对不同的维度次序会建立出不同的预汇总数据。
cgroups 函数中实现了冗余排序机制,如果发现有多个预汇总数据按不同维度排序的,且有切片条件时,则会选择最合适的那个。
我们也可以人为用 SPL 代码选择合适排序的数据集,以及存储更多种排序的数据集。
冗余排序方法并不只用于多维分析,有过滤条件的常规遍历时也可以使用。


英文版