


SPL 关联定位算法
大数据表关联时,有时会先对关联表做条件过滤。对于关联字段是主键或者部分主键的情况,SPL 在有序归并关联算法(参考这里)的基础上提供关联定位算法,来提升过滤后关联的计算性能。
先来看关联表按照全部主键连接的情况(我们称这样的表互为同维表)。假设,两个大表 a 表和 b 表已经预先按照主键 id 有序存储,两个表的关联关系如下图 1:
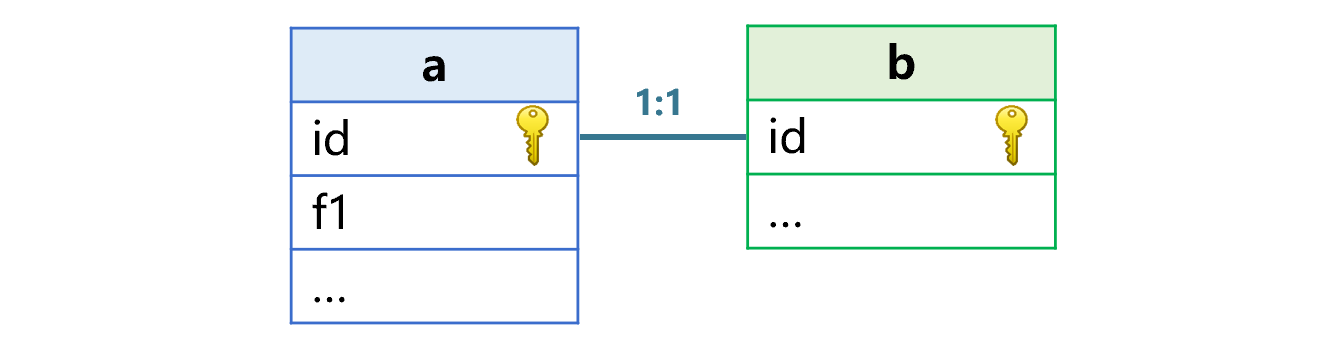
图 1 a 表和 b 表
现在,我们要用这两个同维表按照 id 做连接,并过滤出 f1 为 3 的记录。简单的做法是将两个表按照主键关联之后再做过滤。大致过程如下图 2:
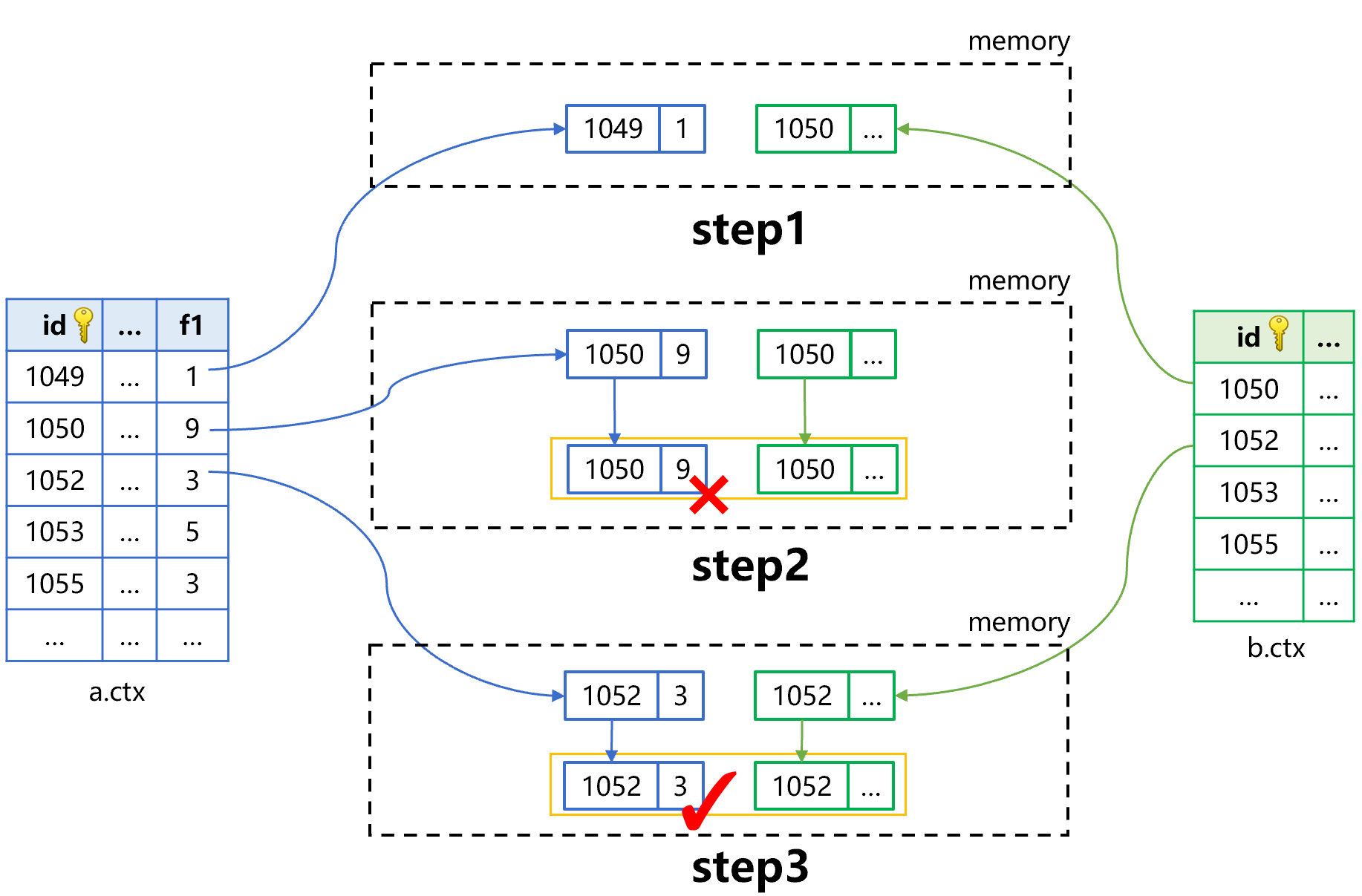
图 2 先关联再过滤
图 2 中,按照顺序从 a、b 两个表中取出记录做关联。关联后再判断 f1 是否为 3。是 3 则输出结果,不是 3 就舍弃掉。这样做,会将 a、b 表都遍历一次,表很大时就会非常耗时。
如果过滤后符合条件的记录仍然占绝大多数,那么 a、b 表都被遍历也是必要的。但如果 a 表过滤后只剩很少的记录,那么 b 表就没有必要再全遍历了。基于 a 表过滤后的数据,利用关联字段的有序性,到 b 表找到对应的数据,可以少遍历一个大表。
这就是 SPL 提供的关联定位算法,完成上述计算需求的过程大致是下图 3 这样:
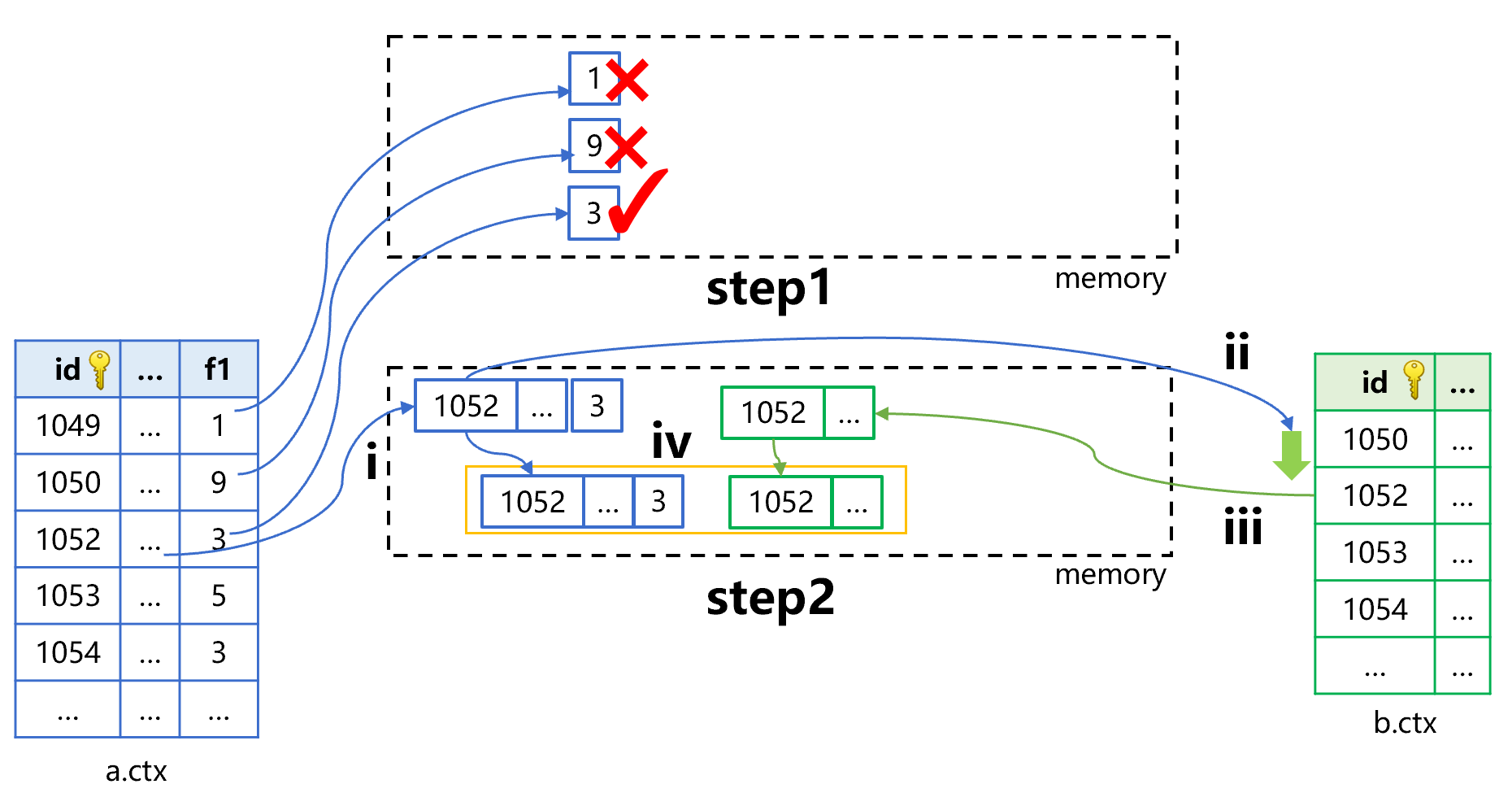
图 3 关联定位算法(step1、2)
图 3 中 step1,采用游标前过滤技术(参考这里),从 a 表中仅读入一条记录的一个字段 f1,判断是否为 3。如果不是 3 则舍弃,取 a 的下一条记录。如果是 3,做 step2。
step2 比较复杂,我们再分成四小步来看。第 i 步,从 a 表中继续读入 f1 之外的其他字段。第 ii 步,用 a 表主键 id 的值 1052 在 b 表中做主键查找。第 iii、iv 步,找到 b 表记录后和 a 表记录生成新的关联记录。
与图 2 相比,a 表中 f1 不满足条件的记录,不用再读取其他字段。例如:id 为 1049 和 1050 的两条记录,就省去了读取其他字段的时间。同时,b 表中 id 为 1050 的整条记录也不需要读取了。总体来看,a 表中满足过滤条件的结果集越小,减少的读取量就越大,性能提升效果越明显。
继续完成关联定位计算的 step3、4 步骤,大致是下图 4 这样:
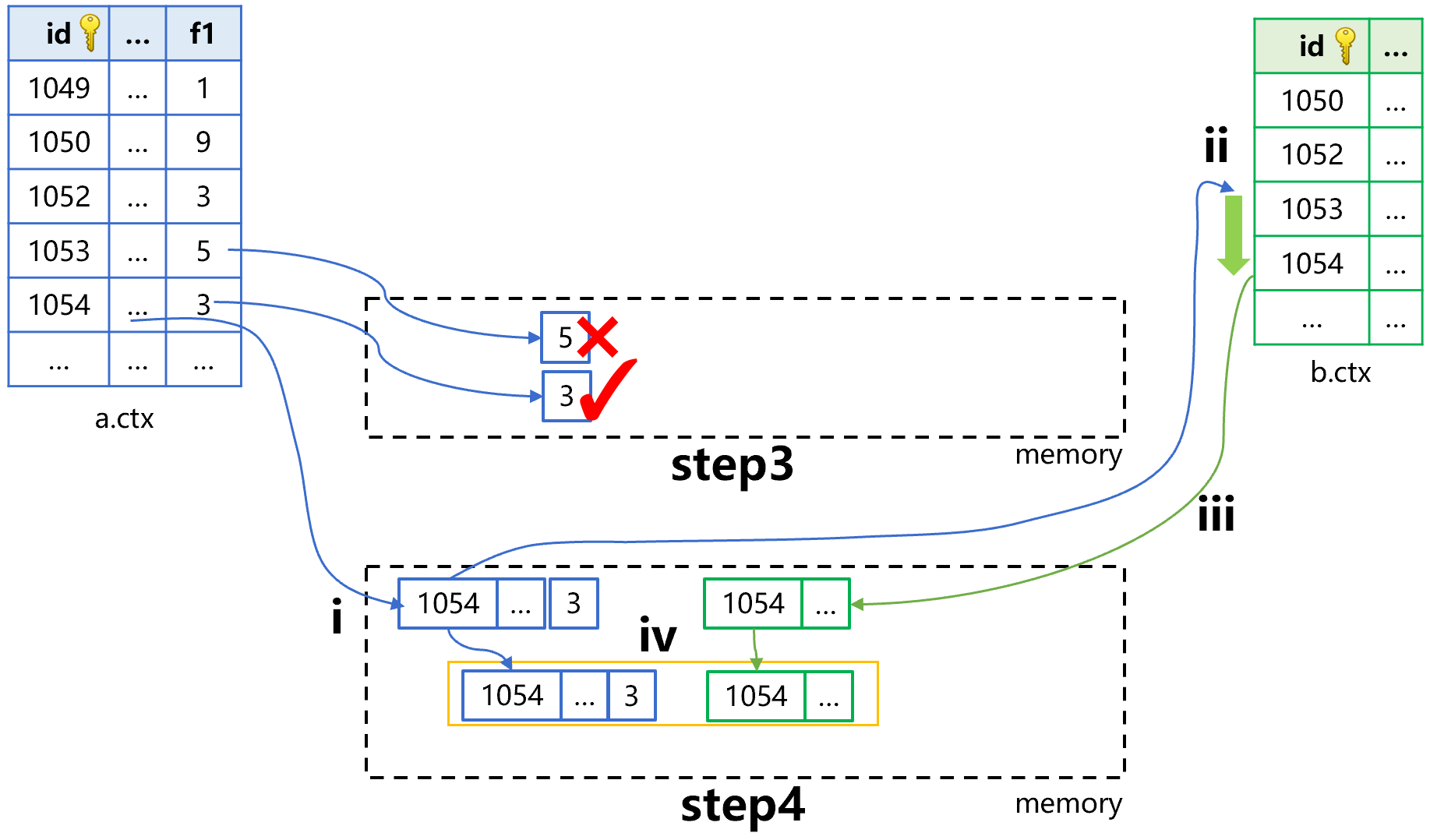
图 4 关联定位算法(step3、4)
图 4 中 step3,继续用游标前过滤的方法,找 f1 为 3 的记录。找到后,做 step4。
step4 也分成四个小步骤来看,其他小步骤都和 step2 相同,重点看第 ii 步:用主键 id 的值 1054 去 b 表中做主键查找。这次查找只要从上次的位置点(id 值为 1052)继续向后找就可以了,不必从 b 表开头去找。
结合图 3、4 可以看到,a 表取出来的记录主键 id 是有序的,所以用 id 从 b 表中取出的记录也不会重复。而且,读取的过程是从前向后扫描 b 表。最坏的情况也就是将 b 表遍历一次,不会出现多次重复遍历。
如果 a 表过滤后剩下的结果集很小,关联定位算法就能大量减少硬盘读取的数据量,而且也能避免对 b 表全表遍历,获得更好的性能。
但是,这种利用关联来定位的算法实现并不简单,代码较复杂,其本身开销也不小,有可能抵消掉读取量变小的优势,具体使用场景还要测试。
SPL 对这种算法做了封装,同维表关联定位要用 new() 函数,SPL 代码大致是下面这样:
A |
|
1 |
=file("a.ctx").open().cursor(id,f1,…;f1==3) |
2 |
=file("b.ctx").open().new(A1,f1,…) |
3 |
=A1.fetch(1000) |
A1 对 a 表定义游标前过滤计算。为了后续做 b 表的主键查找,这里要取出 a 表的主键 id。
A2 采用关联定位算法,用过滤后的 a 表记录,去取 b 表记录。这里定义了延迟游标,并没有真正计算。
A3 中对 A2 形成的延迟游标取数。也可以利用游标做其他计算。
A2 中的 new 函数按照主键关联,使用时不指定关联字段。SPL 发现 a 表的主键只有一个 id 字段,就会用 b 表中第一个字段与之对应。一般的,由于同维表的主键字段个数相同,当 a、b 表的主键都是 n 个字段时,SPL 会按照顺序一一对应。字段的名称并不会影响主键字段的对应。
new 函数是用 a 表的主键在 b 表中查找,所以查找结果是以 b 表的记录为基础,增加 a 的字段。也就是说 a 表中有,而 b 表中没有的主键,对应记录是不会出现在结果中的。
当一个表的主键和其他表的部分主键关联时,我们称为主子表关联。第一个表称为主表,其他表为子表。下面我们来看主子表做关联定位计算的情况。
例如,订单表和明细表的关系如下图 5:
图 5 订单表和明细表的关系
我们要将两表关联,并将订单表按照条件 cid==10096 过滤。再按照 odate 分组,对 price*quantity 汇总求和。
和图 3、4 不同,用过滤后的订单数据,去明细表做的是部分主键查找,而不是全部主键查找。查找可能会得到多条记录的结果集。大致是下图 6 这样:
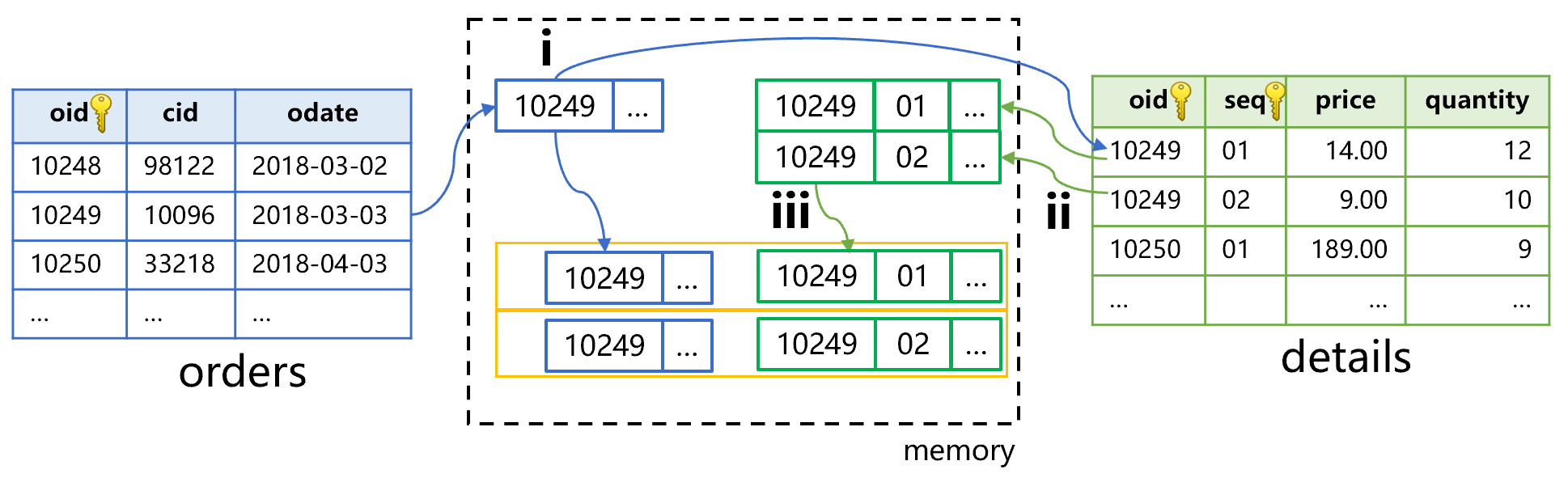
图 6 订单表(主表)按条件过滤
图 6 中第 i 步,顺序读取订单表,找到满足条件的一条记录。其主键 oid 值为 10249,去明细表中对第一个字段做查找。
第 ii 步,查找到两条记录。第 iii 步,查找对象是明细表,返回的是明细表的记录。所以结果以明细表为准,会生成两条新的关联记录,也就是说订单表的一条记录要重复两次。
SPL 中,主表(订单表)按条件过滤后关联子表,需要用 news() 函数,代码大致是这样:
A |
|
1 |
=file("orders.ctx").open().cursor(oid,odate;cid==10096) |
2 |
=file("details.ctx").open().news(A1,odate,price,quantity) |
3 |
=A2.groups(dt;sum(price*quantity)) |
A1 对订单表定义游标前过滤计算。为了后续在明细表查找,这里要取出主键 oid。
A2 中,用 A1 过滤的结果,去明细表中查找。用订单表(主表)符合条件的每个 oid 去查找明细表(子表),都可能会得到多条记录。这里用 news 函数,表示要把主表的字段按关联的子表记录数量复制形成多行结果集。
A2 中的 news 函数也不指定关联字段,SPL 发现 A1(主表)中的主键只有一个字段 oid,就会用 detail(子表)中的第一个字段 oid 和与之对应。一般的,主子表关联,主表的主键字段个数一定小于子表。当主表的主键由 n 个字段组成,SPL 会在 detail(子表)中按照字段顺序找到前 n 个字段与之对应。
如果要过滤的条件是明细表 quantity>10,那么计算过程大致会变成下图 7 这样:
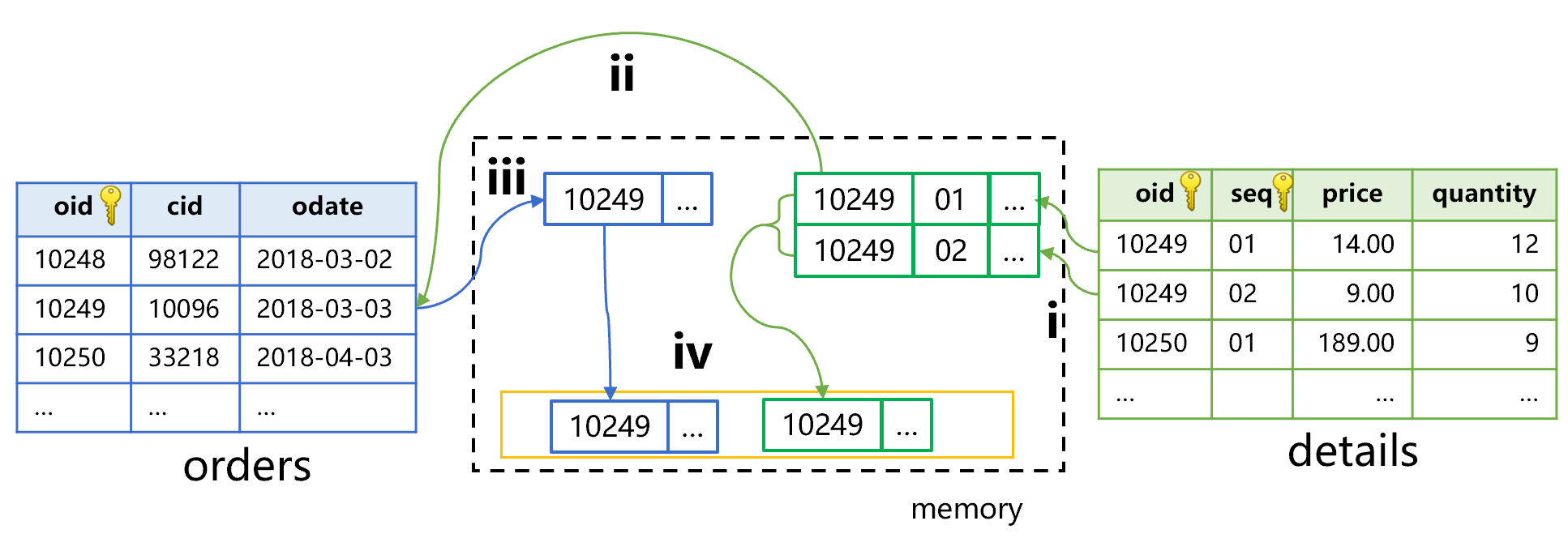
图 7 先过滤明细表(子表)
图 7 中第 i 步,按照过滤条件遍历明细表,先找到 oid 都是 10249 的两条记录满足条件,seq 分别为 1 和 2。第 ii 步,用 oid 值 10249 到订单表中查找,得到一条记录。第 iii 步,主键查找的对象是订单表,返回的结果是订单表的记录。所以结果以订单表为准,要将明细表中的两条记录做聚合计算后,再和订单表记录生成新的关联记录。
SPL 实现先过滤明细表(子表)再关联主表,也要使用 new 函数,代码大致是这样:
A |
|
1 |
=file("details.ctx").open().cursor(oid,price,quantity;quanity>10) |
2 |
=file("orders.ctx").open().new@z(A1,odate,sum(price*quantity):amount) |
3 |
=A2.groups(odate;sum(amount)) |
A1 对明细表定义游标前过滤计算。为了后续做订单表的主键查找,这里要取出 oid 字段。
A2 中,new 函数是用 A1 过滤的结果,去订单表中做查找。new 的结果是订单表记录,要以订单表记录为准。而明细表符合条件的一个 oid 可能对应多条记录。所以,这里用 new 函数时,要先对 A1 做一次聚合。
这里的 new 为什么要加 @z 选项呢?
前面介绍过,new 函数默认会去看 A1 的主键有几个,再用订单表中前几个字段与之对应。但是,A1 中游标只取得了部分主键 oid,没有取第二个主键 seq,所以 A1 计算的结果游标失去主键了。这时就不能用 A1 的主键字段,去对应订单表的前几个字段了。
@z 的含义就是,new 函数反过来用订单表的主键,去 A1 中找对应个数的字段做对应。


英文版