


开源 SPL 协助 BIRT 实现困难报表
BIRT 是比较流行的开源报表工具,独立的 IDE 与向导、丰富的设置开发报表很是方便,但 BIRT 对付某些复杂和特殊的报表会有一些困难。主要原因是 BIRT 的数据准备能力较弱,虽然提供了 script 数据集,但比起专业的数据处理引擎还要差很多,使用 BIRT 开发复杂报表往往还要借助硬编码,十分繁琐。
使用开源集算器 SPL 可以很好解决这个问题。SPL 是一款专业结构化数据计算引擎,拥有丰富的计算类库和完备、不依赖数据库的计算能力,支持多种数据源连接以及多源混合计算。敏捷 SPL 语法可以快速实现数据准备,同时高性能机制还能进一步保证报表运行效率,是 BIRT 名副其实的好帮手。
来看一下 SPL 可以辅助 BIRT 实现困难报表的例子。
特殊布局
横向分栏
BIRT 只支持纵向分栏,很难实现数据交替填充各栏(横向分栏),比如要基于左边的数据实现右边的报表:
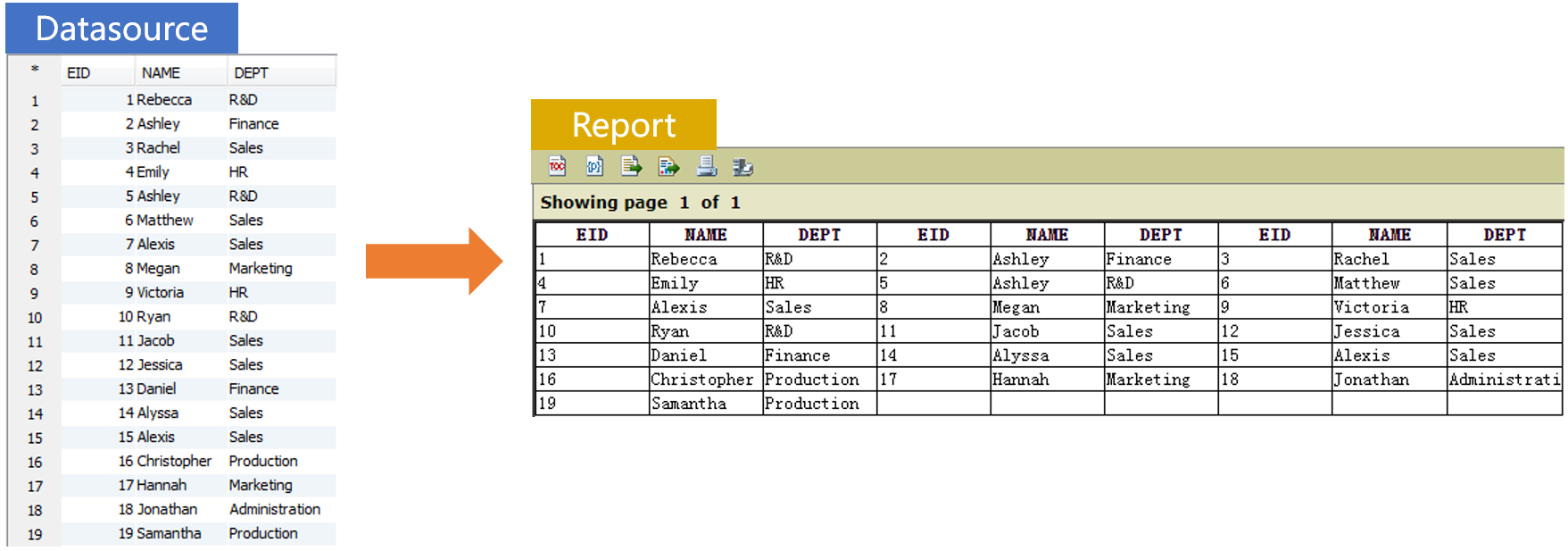
这时就可以借助 SPL 把数据准备成需要的格式再交给 BIRT 直接呈现。
A |
B |
|
1 |
=connect(“db”) |
/ 连接数据库 |
2 |
=A1.query@x("SELECT EID, NAME, DEPT FROM EMPLOYEE") |
/ 执行 SQL 获取数据 |
3 |
=create(EID,NAME,DEPT,EID2,NAME2,DEPT2,EID3,NAME3,DEPT3) .record(A2.conj(~.array())) |
/ 创建结果集并填充各列数据 |
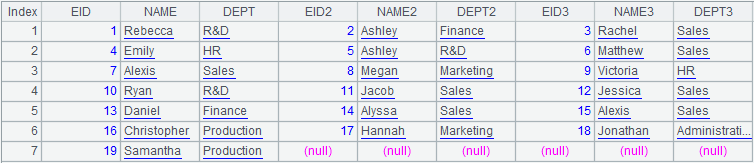
准备好的数据(A3)是下图这样的,BIRT 直接用就可以了。
错位分栏
类似的,要实现错位分栏也很方便

用 SPL 准备数据:
A |
B |
|
1 |
=connect("db") |
|
2 |
=A1.query@x("SELECT EID, NAME, DEPT FROM EMPLOYEE") |
|
3 |
=A2.derive(EID[1]:EID2,NAME[1]:NAME2,DEPT[1]:DEPT2) |
/ 计算列用 [1] 方式取下一个值 |
宽表按行列数分页打印
BIRT 可以用简单的脚本实现行后分页,但列(字段)后分页较难实现。例如,给定任意数据库的宽表,一张纸打印不下,报表要求在第一张纸打印前 1 到 N 列,第二张纸打印 N+1 至 2N 列,以此类推。

仍然用 SPL 来辅助准备数据:
A |
B |
|
1 |
=connect("demo") |
|
2 |
=A1.query@x("SELECT * FROM"+table) |
/ 参数 table 是传入的数据库表名 |
3 |
=create(${col.("col"/~).concat@c()}) |
/ 动态生成 col 列数的空表 |
4 |
=A2.group((#-1)\row) |
/ 将数据每隔 row 行分组 |
5 |
=A2.fname().group((#-1)\col) |
/ 字段名按 col 的个数分组 |
6 |
=A5.("["+~.concat@cq()+"]|~.conj(["+~.concat@c()+"])").concat("|") |
/ 拼出需要执行的串 |
7 |
=A4.run(A3.record(${A6})) |
/ 遍历每组数据赋值 |
8 |
return A3 |

当 col 为 4,row 为 10,A3 的结果如图所示,这就是报表需要的数据集,展现时设置为每 row+1 行分页即可。
复杂格式
组内根据条件控制格式
用字段 STATE 分组,若组内记录数不止一条,第二条起的每条记录 NAME 前添加 +(加号),并在组尾增加对 SALARY 的汇总
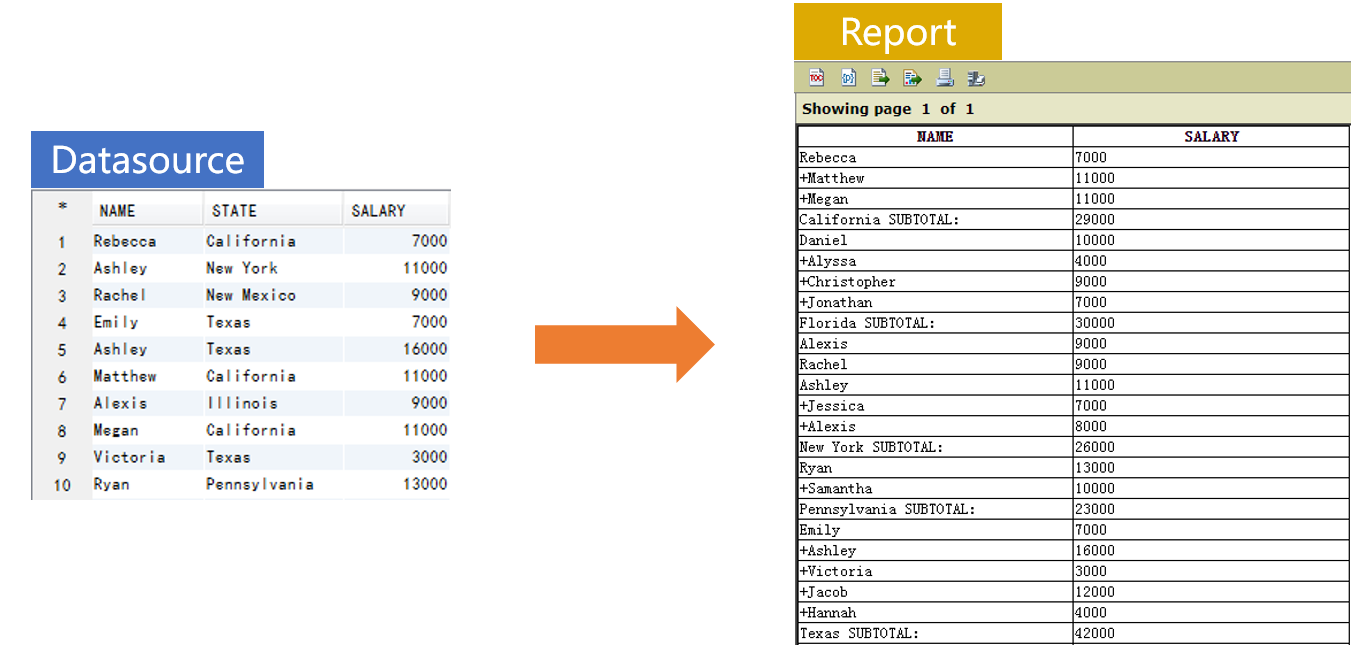
SPL 准备数据:
A |
B |
|
1 |
=connect("demo") |
|
2 |
=A1.query@x("SELECT * FROM EMPLOYEE") |
|
3 |
=create(NAME,SALARY) |
|
4 |
for A2.group(STATE) |
>A3.insert(0:A4,if(#>1,"+")+NAME,SALARY) |
5 |
=if(A4.len()>1,A3.insert(0,A4.STATE+" SUBTOTAL:",A4.sum(SALARY))) |
|
6 |
return A3 |
字段拆分到多条记录
数据库表 DATA 有两个字段,其中 ANOMOALIES 字段是用空格分隔的多个字符串,需要把 ANOMOALIES 按空格拆分为多个字符串,并用每个字符串和原 ID 字段形成新的记录

SPL 数据准备:
A |
B |
|
1 |
=connect("demo") |
|
2 |
=A1.query@x("SELECT * FROM DATA") |
|
3 |
=A2.news(ANOMALIES.split(" ");ID,~:ANOMALIES) |
/ 按空格拆分后生成新记录 |
复制行
按次序将记录复制三份,并用报表展现
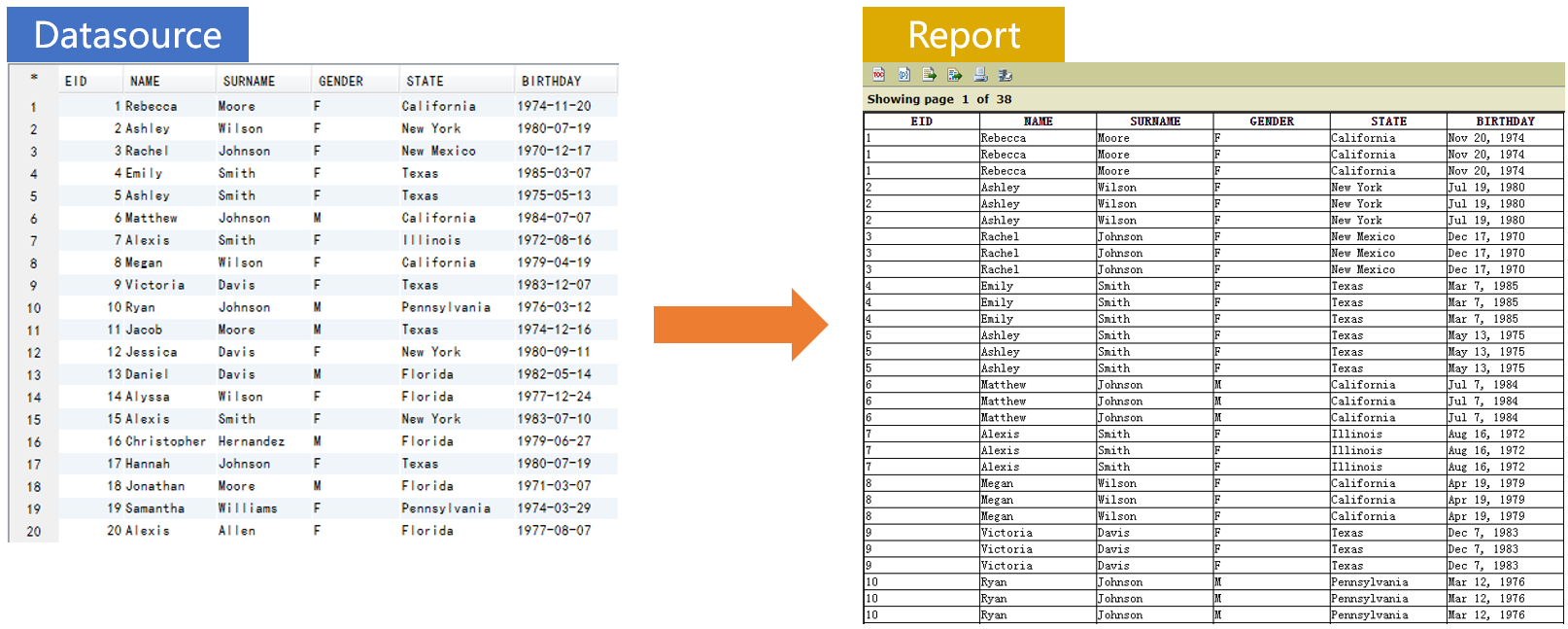
SPL 准备数据:
A |
B |
|
1 |
=connect("demo") |
|
2 |
=A1.query@x("SELECT * FROM EMPLOYEE") |
|
3 |
=A2.conj([~]*3) |
/ 每条记录重复 3 份 |
就得到了报表需要的数据格式:

行列转置
数据库表 SALES 存储订单数据,报表需要按月横向扩展,聚合项纵向扩展

SPL 数据准备:
A |
B |
|
1 |
=connect("demo") |
|
2 |
=A1.query@x("SELECT month(ORDERDATE) AS MONTH, sum(AMOUNT) AS OSUM , max(AMOUNT) AS OMAX, min(AMOUNT) AS OMIN , count(ORDERID) AS ONUM FROM SALES GROUP BY MONTH ORDER BY MONTH") |
|
3 |
=A2.pivot@r(MONTH;SUBTOTAL,VALUE) |
/ 列转行 |
4 |
=A3.pivot(SUBTOTAL;MONTH,VALUE) |
/ 行转列 |
不规则统计
交叉表列间计算
数据库表 STORE 存储了 2014、2015 年的产品销售量,需要呈现每种产品每年的销售量,并计算出各产品的年增长率

SPL 数据准备:
A |
B |
|
1 |
=connect("demo") |
|
2 |
=A1.query@x("SELECT * FROM STORE ORDER BY ITEM, YEAR") |
|
3 |
=A2.group@o(ITEM).run(A2.record(["GROWTH RATE",ITEM,~(2).QUANTITY/~(1).QUANTITY-1])) |
/ 分组后计算出增长率 |
4 |
=A2.pivot(ITEM;YEAR,QUANTITY) |
/ 行转列 |
不规则月份统计
数据库表 SALES 存储订单数据,要统计从 2013-01-16 日到 2013-08-18 每个月的销售总额

SPL 数据准备:
A |
B |
|
1 |
=connect("demo") |
|
2 |
=A1.query@x("SELECT ORDERID, AMOUNT, ORDERDATE FROM SALES WHERE ORDERDATE >= ? AND ORDERDATE < ? ORDER BY ORDERDATE",startDate,endDate) |
|
3 |
=interval@m(startDate,endDate) |
/ 计算起止日期隔了多少个月 |
4 |
=startDate|A3.(elapse@m(startDate,~)) |
/ 起始日期并上新日期 |
5 |
=A2.group(A4.pseg(ORDERDATE):NUMBER;round(~.sum(AMOUNT),2):TOTALAMOUNT,A4(#):STARTDATE) |
/ 按日期区间的序号分组统计,并取每组对应的起始日期 |
组内跨行计算
数据库表 SAMPLE 有三个字段,其中 ID 是分组字段。需要设计一张分组表,使用 ID 分组,明细字段是 V1,V2 以及计算列 CROSSLINE, 其中 CROSSLINE 的算法是本条记录 V1、V2 之和加上本组上一条记录的 V1、V2 之和

SPL 数据准备:
A |
B |
|
1 |
=connect("demo") |
|
2 |
=A1.query@x("SELECT ID, V1, V2 FROM SAMPLE ORDER BY ID") |
|
3 |
=A2.derive(iterate(~~+V1+V2;ID):CROSSLINE) |
/ 添加计算列 CROSSLINE,本条记录 V1、V2 之和加上本组上一条记录的 V1、V2 之和 |
动态报表
动态数据源
由报表参数决定连接哪个数据源
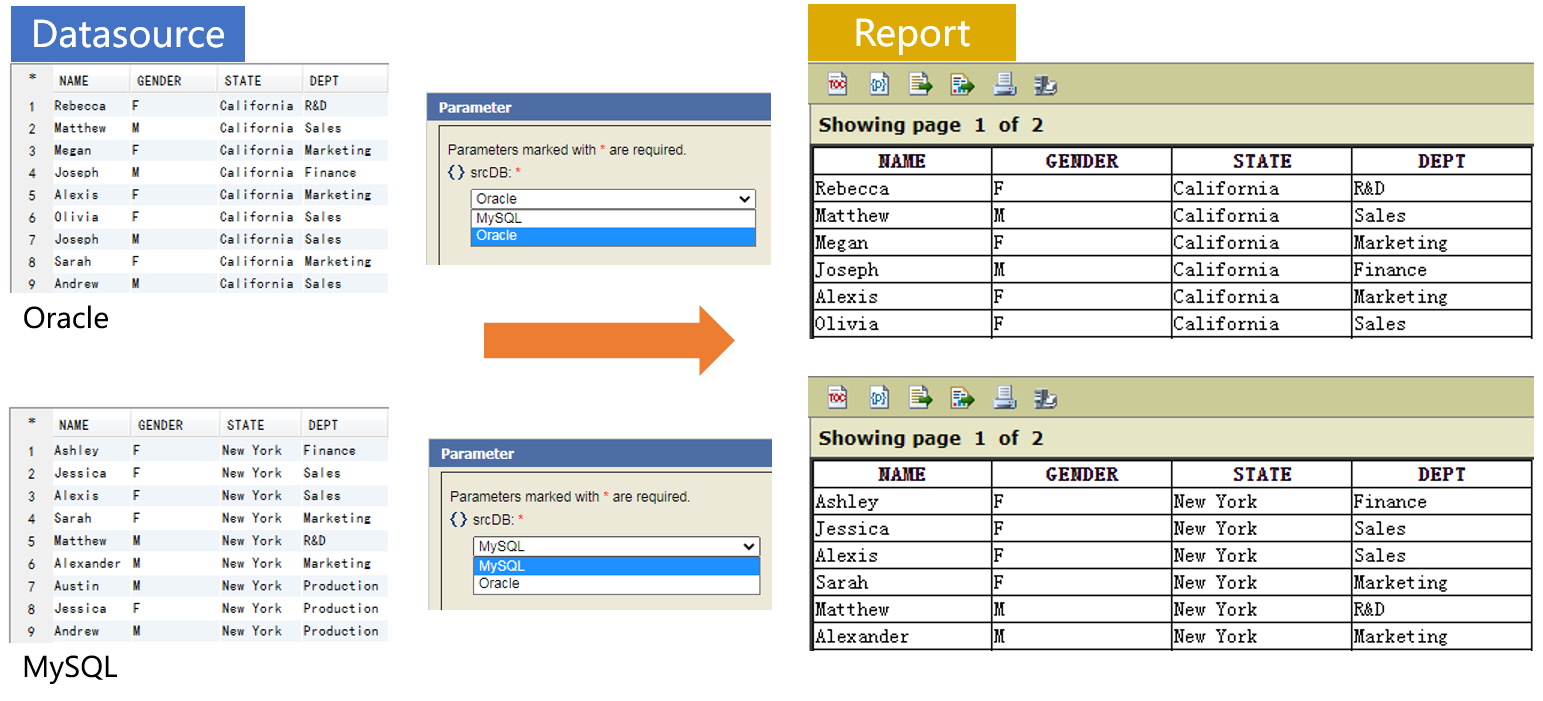
SPL 实现:
A |
B |
|
1 |
=connect(srcDB) |
/ 参数 srcDB 是需要连接的数据库名 |
2 |
=A1.query@x("SELECT * FROM EMPLOYEE") |
/ 执行 SQL 取数 |
跨数据源拼接
TABLE1 表来自数据库,table2.xlsx 是 Excel 文件,两者同构。要求:将两者的数据,分别按 NAME 分组并对各组计数(NUM1、NUM2)、对 VALUE 求和(AMOUNT1、AMOUNT2)

SPL 数据准备:
A |
B |
|
1 |
=connect("demo") |
|
2 |
=A1.query@x("SELECT NAME, count(*) AS NUM, sum(VALUE) AS AMOUNT FROM TABLE1 GROUP BY NAME") |
/ 数据库数据 |
3 |
=file("table2.xlsx").xlsimport@t() |
/Excel 数据 |
4 |
=A3.groups@o(NAME;count(~):NUM,sum(VALUE):AMOUNT) |
/ 分组,计数、求和 |
5 |
=join@f(A2:T1,NAME;A4:T2,NAME) |
/ 全连接 |
6 |
=A5.new(ifn(T1,T2).NAME:NAME,T1.NUM:NUM1,T1.AMOUNT:AMOUNT1, T2.NUM:NUM2,T2.AMOUNT:AMOUNT2) |
/ 列出姓名和两份数据的计数、求和结果 |
动态日期分组

SPL 数据准备:
A |
B |
C |
|
1 |
=connect("demo") |
||
2 |
=A1.query@x("SELECT ORDERID, ORDERDATE, AMOUNT FROM SALES WHERE ORDERDATE >= ? AND ORDERDATE <= ?",sdate,edate) |
||
3 |
=interval(sdate,edate) |
/ 计算起止日期的间隔天数 |
|
4 |
if A3>365 |
>duration=sdate|A3.(elapse@y(sdate,~)),DN="YEAR" |
/ 大于 365 天,则按年分组 |
5 |
else if A3>30 |
>duration=sdate|A3.(elapse@m(sdate,~)),DN="MONTH" |
/ 大于 30 且小于等于 365 天,则按月分组 |
6 |
else if A3>15 |
>duration=sdate|A3.(elapse(sdate,~*7)),DN="WEEK" |
/ 大于 15 且小于等于 30 天,则按周分组 |
7 |
else |
>duration=sdate|A3.(elapse(sdate,~)),DN="DAY" |
/ 小于等于 15 天,则按天分组 |
8 |
=A2.group(duration.pseg(ORDERDATE):${DN};~.count(ORDERID):COUNT,round(~.sum(AMOUNT),2):TOTAL,duration(#):STARTDATE) |
/ 分组并统计 |
带 in 条件查询
BIRT 对数组参数支持得不好,很难处理带 in 条件的查询,可以使用 SPL 协助 BIRT,支持用数组参数进行查询

SPL 数据准备:
A |
B |
|
1 |
=connect("demo") |
|
2 |
=A1.query@x("SELECT * FROM SALES WHERE ORDERID IN (?)",ids.split@c()) |
/ 用逗号拆分出的数组 |
以上是 SPL 协助 BIRT 实现复杂报表的部分示例,那么如何将 SPL 集成到 BIRT 中呢。简单,借助 SPL 封装的标准 JDBC 接口就可以顺利集成。
BIRT 集成 SPL
SPL 是用 Java 实现的,只要把相应的 jar 引入,就可以完全无缝地集成到 BIRT 中。SPL 提供了标准 JDBC,可以作为 BIRT 数据源使用,调用 SPL 脚本时使用类似存储过程的方式调用。

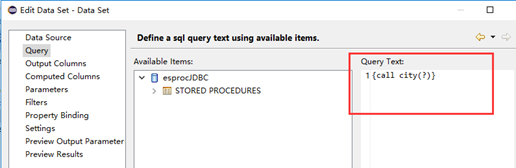
具体集成使用可以参考: BIRT 调用 SPL 脚本
有了 SPL,BIRT 就再也没有难做的报表了。开源 SPL+ 开源 BIRT,绝配!赶快下载玩玩吧。
下载地址: 集算器 (SPL) 最新版发布啦『发布日期 20260507』
源代码:https://github.com/SPLWare/esProc


英文版