


SPL 遍历复用
遍历复用的原理
对外存数据表做遍历计算时,大部分时间都用来从硬盘上读取数据了。所以我们会希望一次读取能做尽量多的事情,也就是尽量做到能复用遍历过程中读出来的数据。
比如我们对订单做分组统计,希望完成两种计算。计算 1(compute1),是按产品分组统计销售额,得到结果 result1。计算 2(compute2),是统计每个地区的最大订单额,得到结果 result2。直接的办法是遍历两次,大致是下图 1 这样的:
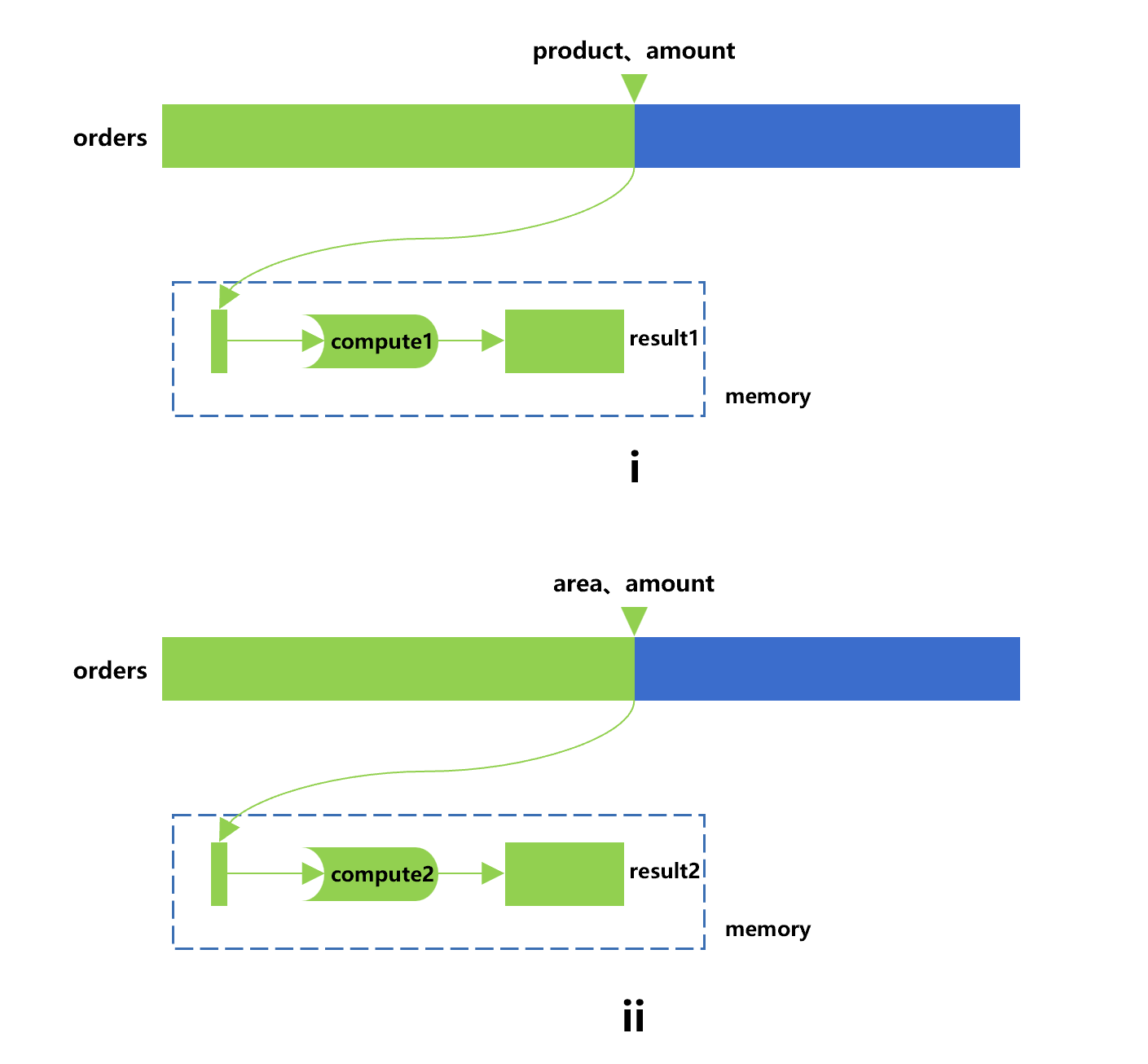
图 1 遍历两次
图 1 中第 i 步,用游标遍历订单表取出产品和订单金额字段,计算 compute1 得到 result1。第 ii 步,用一个新游标再遍历一次订单表取出地区和订单金额字段,计算 compute2 得到 result2。
假如订单表是列存,两次遍历中金额字段会被重复读取。如果是行存,那么重复读取的数据量更大。
我们使用一点技巧,就可以只对订单表遍历一次,也能得到两个分组结果。SPL 代码大致是这样:
A |
|
1 |
=file("orders.ctx").open() |
2 |
=A1.cursor(area,product,amount).groups(area,product;sum(amount):samount,max(amount):mamount) |
3 |
=A2.groups(product;sum(samount)) |
4 |
=A2.groups(area;max(mamount)) |
这样做,CPU 的计算量会多一些,占用内存也会更大,因为要计算和保持一个更细致的分组结果集,但是遍历量少很多,通常还是能获得更好的运算性能。
不过,如果我们还要对更多字段做不同的分组统计,代码就会麻烦得多;要是再对这个游标做一些不是简单分组的运算,比如先过滤后再分组,那几乎就不可能用这种技巧写出来了。在数据库中使用 SQL 就会面临这种窘境。
SPL 提供了更强大的遍历复用技术来解决这类问题。为了便于理解,我们先看只用游标来计算 compute1 的过程,基本上是下图 2 的样子:
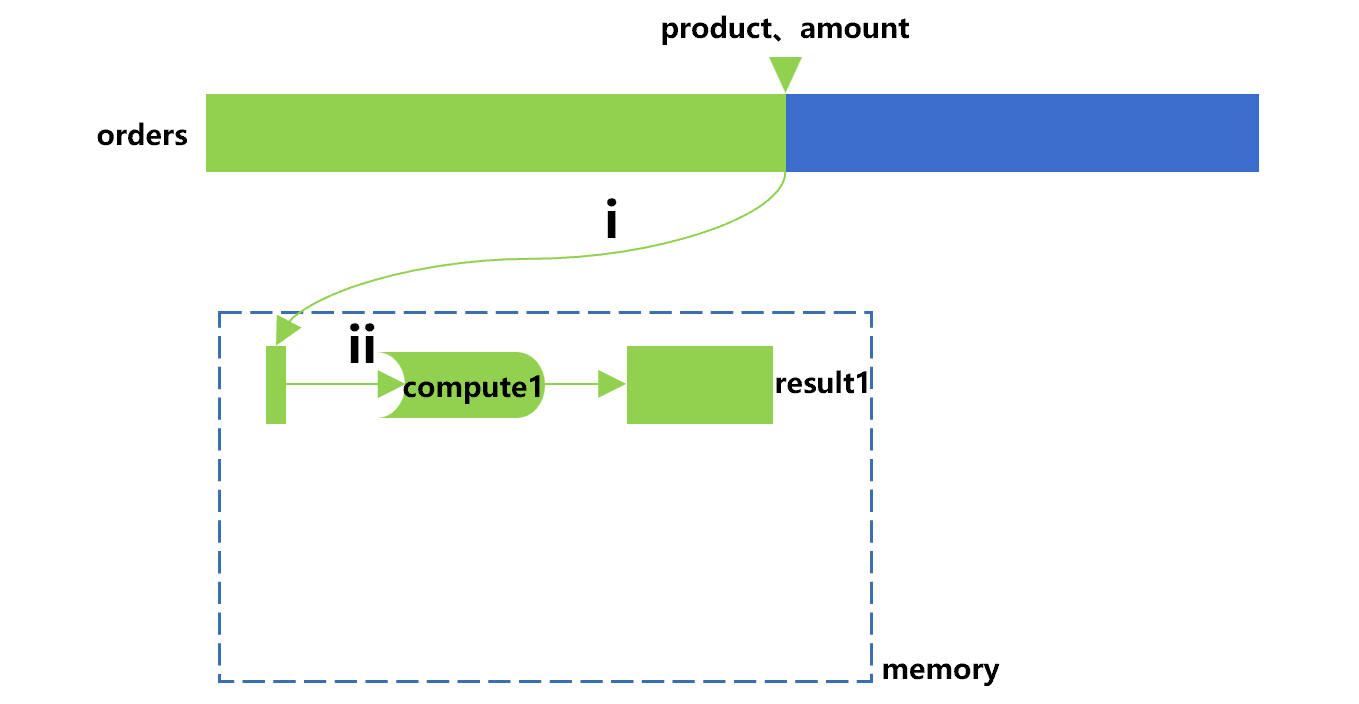
图 2 仅用游标计算 computer1
图 2 中,游标要完成其上定义的计算,会主动做动作 i,从订单表中分批取出产品和订单金额字段。动作 ii,则是按照产品分组对金额求和,也就是对这批订单数据完成 compute1。游标不断重复这两个动作,直到遍历完成得到结果 result1。
对应的 SPL 代码是这样:
A |
|
1 |
=file("orders.ctx").open() |
2 |
=A1.cursor(area,product,amount) |
3 |
=A2.groups(product;sum(amount)) |
A3 中定义了计算 compute1。
接下来,我们可以将游标完成的计算 compute1 看作一条主线,在此基础上对遍历进行复用,大致过程如下图 3:
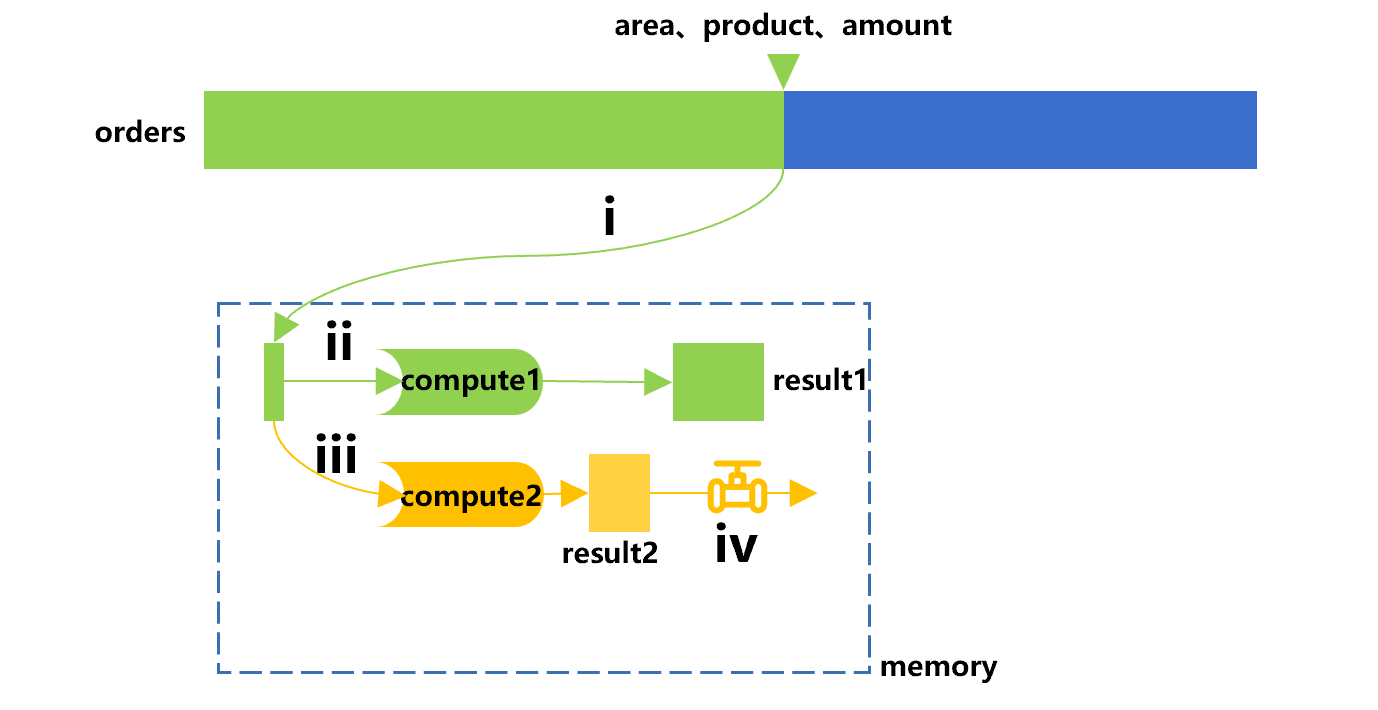
图 3 遍历复用
图 3 中,在游标计算 compute1 这条主线之外,我们增加了一条旁路,用来完成 compute2。游标在实施计算(即 compute1)的过程中,每次从订单表取出一批订单数据,如果发现有一个旁路,则把这份数据也送入这个旁路,即动作 iii,去进行 compute2 的计算,结果暂存起来。
我们把这个旁路(compute2 及保存的结果)称为一个与游标同步的管道。这样,在完成 compute1 计算后,游标也实施了对订单表的遍历。游标运算本身将返回 result1,旁路的管道中还可以得到 result2,需要的时候可以通过动作 iv 取出来。
我们将图 3 与图 1 相比发现,遍历复用的 CPU 运算量和遍历两次的运算量是一样的,都只要做两个小分组。但是,它的硬盘读取量要小很多,订单金额字段只被读了一次。
遍历复用对应的 SPL 代码是这样的:
A |
|
1 |
=file("orders.ctx").open() |
2 |
=A1.cursor(product,area,amount) |
3 |
=channel(A2).groups(area;max(amount)) |
4 |
=A2.groups(product;sum(amount)) |
5 |
=A3.result() |
相比只有游标的代码,增加了 A3 和 A5。
A3 用 channel 函数定义一个与游标 A2 同步的管道,并在其上设置了计算 compute2。
A5 是取出管道中暂存的结果,得到 result2。对应图 3 中的第 iv 步。
遍历复用机制对于所有游标都有效,并不只限于组表。
一个游标可以定义多个同步管道,同时附加多套计算。而且这种计算可以随意写,不仅限于分组,可以是任意的,也可以多个步骤。比如再增加一个 compute3,先过滤出金额在 50 以上的订单,然后再统计记录数。计算过程可以参考下图 4:
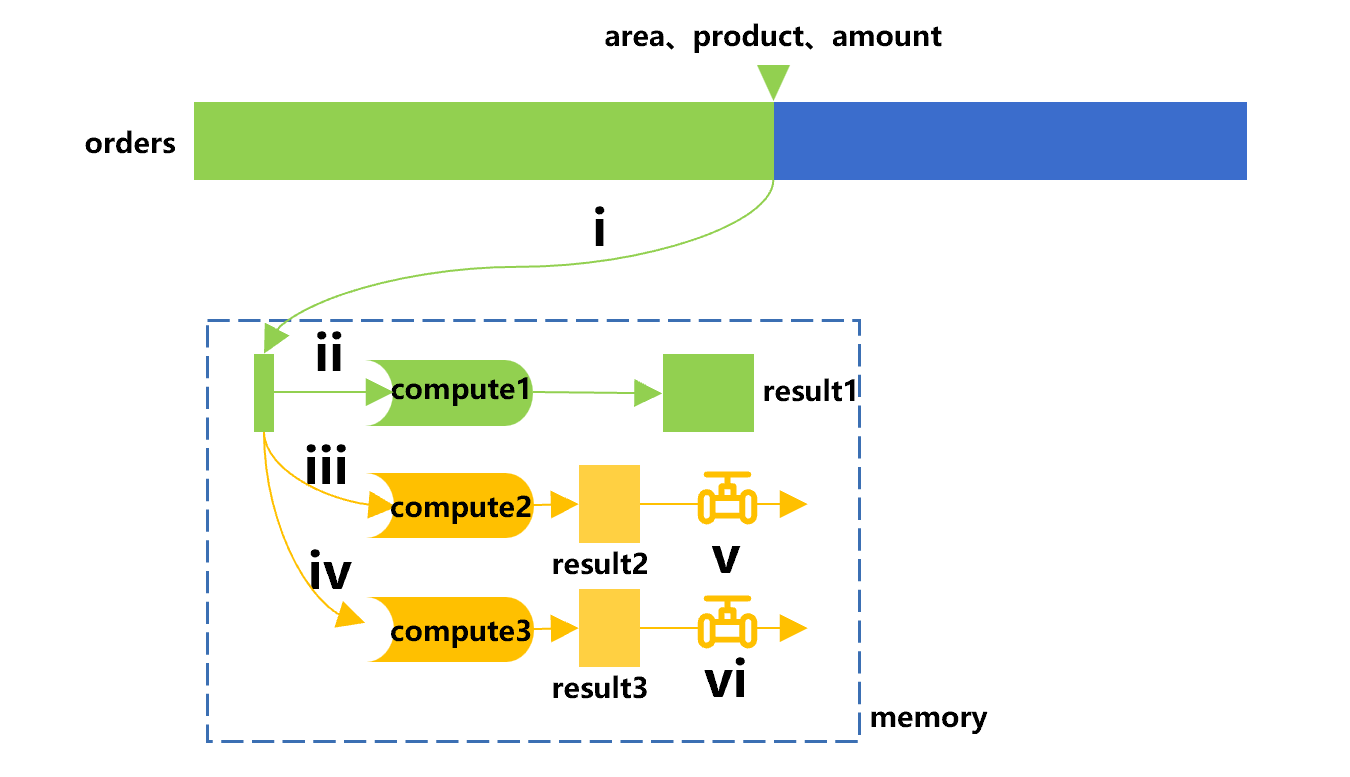
图 4 增加计算 compute3
图 4 中,在原来一个游标、一个管道的基础上,又增加了一个旁路,用于计算 compute3。
增加 compute3 后,对应 SPL 的代码大致是这样:
A |
B |
|
1 |
=file("orders.ctx").open() |
|
2 |
=A1.cursor(product,area,amount) |
|
3 |
=channel(A2).groups(area;max(amount)) |
|
4 |
=channel(A2).select(amount>=50).total(count(1)) |
|
5 |
=A2.groups(product;sum(amount)) |
|
6 |
=A3.result() |
=A4.result() |
A4 用 channel 函数定义了第二个与游标 A2 同步的管道,并在其上设置了计算 compute3。
当 A5 中遍历游标计算 compute1 时,读出的数据也会同时送给管道 A4 完成 compute3,遍历结束后,管道 A4 中会保持相应的计算结果,在 B5 取出来即可。
实际上,游标本身的计算 computer1 也可以用管道完成,而游标本身仅仅做遍历。这样,多个计算的地位是等同的,代码也会显得更为对称:
A |
B |
|
1 |
=file("orders.ctx").open() |
|
2 |
=A1.cursor(product,area,amount) |
|
3 |
=channel(A2).groups(product;sum(amount)) |
|
4 |
=channel(A2).groups(area;max(amount)) |
|
5 |
=channel(A2).select(amount>=50).total(count(1)) |
|
6 |
=A2.skip() |
=A3.result() |
7 |
=A4.result() |
=A5.result() |
A3 到 A5 用 channel 函数定义了三个与游标 A2 同步的管道,并在其上设置了计算 compute1 到 compute3。
当 A6 中遍历游标时,读出的数据也会同时送给三个管道。遍历结束后,三个管道中会保持相应的计算结果,可以在 B6、A7、B7 中取出来。
这种情况比较常见,SPL 提供专门的语句式管道语法,上面的代码还可以写成这样:
A |
B |
|
1 |
=file("orders.ctx").open() |
|
2 |
=A1.cursor(product,area,amount) |
|
3 |
cursor A2 |
=A3.groups(product;sum(amount)) |
4 |
cursor |
=A4.groups(area;max(amount)) |
5 |
cursor |
=A5.select(amount>=50).total(count(1)) |
6 |
||
A2 游标创建后,用 A3 的 cursor 语句为其创建管道,然后在其上设置运算。可以创建多个管道,后面语句不再写游标参数则表示会复用同一个游标。
所有的 cursor 语句(的代码块)写完后,SPL 即认为整套管道定义结束,就会开始遍历游标,将每个管道的运算结果计算出来存放在 cursor 语句所在的格中。
这里 B3、B4、B5 分别定义 compute1、compute2、compute3,这些计算结果会分别放在 A3、A4、A5 中(注意不是 B3、B4、B5)。
遍历复用用于数据拆分
遍历复用思路可以应用在数据拆分上。比如有个大文本文件 data.txt,我们希望从中挑出正确的数据(满足给定条件)进一步做分析,这对游标使用 select 函数就可以了。同时,我们可能也想知道有哪些错误的数据(不满足条件)以便防止这种情况的再发生。但一次过滤不能同时把满足和不满足条件的记录分开,这时候就可以使用遍历复用技术了。大致的计算过程如下图 5:
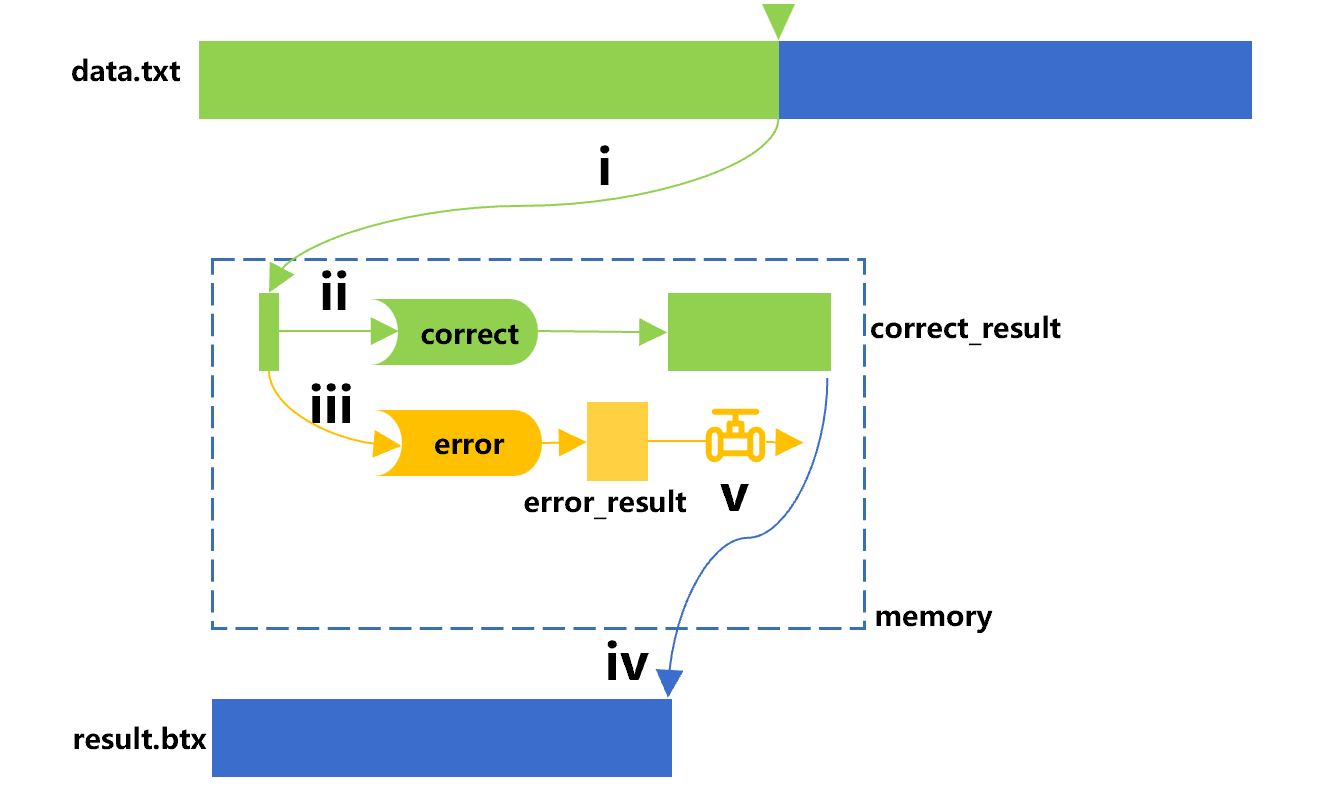
图 5 数据拆分
图 5 中,游标定义了 select 函数做条件过滤,也就是计算“correct”,得到正确数据 correct_result,输出到 result.btx。游标的管道定义了相反的条件,也就是计算“error”,得到错误数据 error_result。这里我们假定不满足条件的记录很少,能够在内存中放下。
对应 SPL 的代码是:
A |
|
1 |
=file("data.txt").cursor@t() |
2 |
… |
3 |
=channel(A1).select(!(${A2})).fetch() |
4 |
=A1.select(${A2}) |
5 |
>file("result.btx").export@b(A4) |
6 |
=A3.result() |
在 A2 中填入过滤条件,A3 的管道将完成计算“error”,过滤出不满足条件的记录并取出 error_result。
A4 的游标完成计算“correct”,过滤出满足条件的正确记录。
A5 遍历游标把满足条件的记录写入新文件,对应图 5 中第 iv 步。
A6 则可以将管道结果取出来了,对应图 5 中的第 v 步。
不过,这样做还是需要把这个条件计算两次(满足和不满足要分别计算)。SPL 在 select 函数直接提供了这种方法,可以把不满足条件的记录同时取出来,不过只能写入另一个文件,也只能是集文件的格式。
A |
|
1 |
=file("data.txt").cursor@t() |
2 |
… |
3 |
=A1.select(${A2};file("error.btx")) |
4 |
>file("result.btx").export@b(A3) |
类似地,还有可能把大数据表拆分成多个组,比如把订单记录按地区拆分成多个文件以便分发处理,也可以使用管道。不过,管道的数量是在代码中事先确定的,要事先知道总共分成多少份,而不能在分组过程中临时产生新的管道。
对于这种情况,SPL 在游标的序号分组中附加了拆分写入文件的功能,比如下面的代码将把订单分到 12 个月(月份容易序号化方便举例,其它情况读者可以自己做序号化)。
A |
|
1 |
=file("orders.txt").cursor@t() |
2 |
=12.(file("order"/~/".btx")) |
3 |
=A1.groupn(month(dt);A2) |
4 |
=A1.skip() |
这里的 groupn 函数是个延迟游标,只是记录一下动作,在游标遍历过程中才会真地计算。事先要准备好相应数量的文件对象(A2)。和 select 类似,groupn 也只能写出集文件。


英文版