


SPL:访问 Cassandra
Cassandra是一种分布式的NoSQL数据库。JAVA中可以使用DataStax执行Cassandra的CQL,CQL语言能简单地维护、读写数据,但不支持关联、分组聚合等操作,计算能力比关系数据库的SQL差很多。另一个掣肘CQL语言计算能力的原因是,它要支持更复杂的数据模型,字段值可能是Set,Map等一些嵌套集合。计算引擎语言SPL能很好的支持复杂数据模型计算,它提供了几个函数连接Cassandra,把数据读出来就能弥补Cassandra数据库较弱的计算能力。
创建/关闭Cassandra连接
使用方式类似关系数据库的JDBC连接,SPL也用成对的“创建/关闭”方式连接Cassandra。
stax_open(server[:port][,keyspace][,user:pwd][,compressor][,version:verX][,queryOptions:optionX]),server是服务器地址,之后分别是端口,键空间、用户名、密码、压缩算法、协议版本号、查询选项,这些参数不需要时可以省略。
stax_close(staxConn),staxConn是要关闭的Cassandra连接。
示例:A1创建连接,中间做一些读写及计算操作后,A3关闭A1创建的连接
A |
|
1 |
=stax_open("127.0.0.1":9042) |
2 |
…… |
3 |
=stax_close(A1) |
执行CQL
stax_execute(staxConn, cql, [arg1], [arg2], ...) ,staxConn是Cassandra连接,cql是要执行的语句,可以带多个参数,传入参数的地方用“?”占位,arg1、arg2…是参数值,有几个“?”,后面就要提供几个参数值。
示例:
A |
|
1 |
=stax_open("127.0.0.1":9042) |
2 |
=stax_execute(A1,"CREATE KEYSPACE splSpace WITH replication = {'class':'SimpleStrategy','replication_factor': 3}") |
3 |
=stax_execute(A1,"USE splSpace") |
4 |
CREATE TABLE emp( emp_id int PRIMARY KEY, emp_name text, emp_city text, emp_sal int, emp_phone text ) |
5 |
=stax_execute(A1,A4) |
6 |
=stax_execute(A1, "select * from emp") |
7 |
INSERT INTO emp(emp_id, emp_name, emp_city,emp_sal, emp_phone) VALUES(4,'robin', 'Hyderabad',?,?); |
8 |
=stax_execute(A1, A7, 234, "984-8022-339") |
9 |
=stax_execute(A1, "select * from emp") |
10 |
=stax_cursor(A1, "select * from emp") |
11 |
=A10.fetch(10) |
12 |
CREATE TABLE users ( id text PRIMARY KEY, name text, favs map<text, text> ) |
13 |
=stax_execute(A1,A12) |
14 |
INSERT INTO users (id, name, favs) VALUES ('jsmith', 'John Smith', { 'fruit' : 'Apple', 'band' : 'Beatles'}) |
15 |
=stax_execute(A1,A13) |
16 |
=stax_execute(A1, "select * from users") |
17 |
=stax_close(A1) |
A2创建一个名为“splSpace”的键空间;
A3使用这个键空间,之后的操作就都在这个健空间下;
A4是一个表定义的CQL,A5执行A4的CQL,就创建好这个表了;A6查询这个表,虽然还没数据,但能看到表结构了:

A7是一条向emp表插入数据的语句,最后两个值以参数的方式传入,A8执行A7的语句,传入的参数值是234,984-8022-339,执行后,A9再查询emp表,能看到数据了:

A10是新的函数stax_cursor(),它和stax_execute()语法一样,不立即返回结果数据,而是一个游标,根据需要分批的读入数据,如A11取前10行数据。stax_cursor()适合结果数据巨大的情况。
A12定义的users表中favs字段是map类型,A13执行创建CQL,A15插入一行数据,A16查询users表,SPL中的结果是如下嵌套的序表: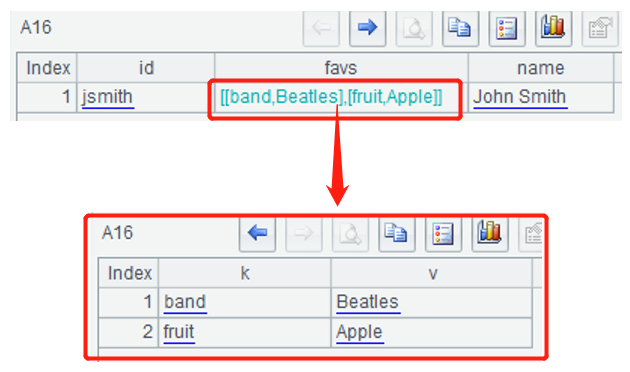
嵌套多层的复杂数据,只要引入到SPL中,再做后续变换、计算就容易了。


英文版