


Python 和 SPL 对比 11——多对一关联
《Python和 SPL对比系列 10——一对 N关联》介绍了关联关系中的一对一和一对 N 关联,本文对比 Python 和 SPL 多对一关联的运算能力。
外键关联
表 A 的某些字段与表 B 的主键关联,表 A 的关联字段可以不唯一,表 B 的关联字段唯一,这就是多对一关联,也称作外键关联,即表 A 是事实表,表 B 是维表,A 表与 B 表主键关联的字段称为 A 指向 B 的外键,B 也称为 A 的外键表。如:
现有销售记录表和产品信息表,请汇总各类产品的销售额。
销售记录表、城市信息表、产品信息表部分内容如下:
销售记录表 (事实表):
recordid |
product |
sale_city |
amount |
… |
sr100001 |
p1003 |
c104 |
380 |
… |
sr100002 |
p1005 |
c103 |
400 |
… |
sr100003 |
p1003 |
c104 |
626 |
… |
… |
… |
… |
… |
… |
产品信息表(维表):
productid |
pclass |
… |
p1001 |
A |
… |
p1002 |
A |
… |
p1003 |
B |
… |
… |
… |
… |
Python
import pandas as pd sr_file1="D:\data\SaleRecord.csv" pt_file1="D:\data\Product.csv" record1=pd.read_csv(sr_file1) product1=pd.read_csv(pt_file1) r_pt=pd.merge(record1,product1,left_on="product",right_on="productid") pclass_sale=r_pt.groupby('pclass',as_index=False).amount.sum() print(pclass_sale) |
事实表
维表 事实表与维表外键关联
|
Python的 merge 函数关联两表,销售记录表 record1 是实事表,产品信息表 product1 是维表,record1 中的多条记录与 product1 的一条记录对应,两者的关联字段名不同,left_on 和 right_on 分别标出两表的关联字段,使两表关联成为一张宽表,最后分组汇总得到结果。
SPL
A |
B |
|
1 |
D:\data\SaleRecord.csv |
|
2 |
D:\data\Product.csv |
|
3 |
=file(A1).import@tc() |
|
4 |
=file(A2).import@tc() |
|
5 |
=A3.switch(product,A4:productid) |
/外键转维表记录 |
6 |
=A5.groups(product.pclass;sum(amount):amount) |
SPL的 switch 函数把外键字段转换成对应的维表记录,既然是记录当然可以引用字段,在分组时可以利用引用字段完成分组聚合运算。
一事实表,多维表
一张事实表可能关联多张维表,如:
续用上例的销售记录表(事实表)和产品信息表(维表 1),新增城市信息表(维表 2),请统计各省份各类产品的销售额。
城市信息表(维表 2):
cityid |
name |
province |
… |
c101 |
Beijing |
Beijing |
… |
c102 |
Tianjin |
Tianjin |
… |
c103 |
Harbin |
Heilongjiang |
… |
… |
… |
… |
… |
Python
#续用sr_file1和pt_file1 ct_file1="D:\data\City.csv" ct1=pd.read_csv(ct_file1) r_ct=pd.merge(record1,ct1,left_on="sale_city",right_on="cityid") r_ct_pdt=pd.merge(r_ct,product1,left_on="product",right_on="productid") ct_pdt_sale=r_ct_pdt.groupby(['province','pclass'],as_index=False).amount.sum() print(ct_pdt_sale) |
事实表关联维表 2 事实表关联维表 1 分组聚合 |
Python在关联多张维表时,通常是先关联一个再关联另一个,两次 merge 组成一张大宽表,最后利用宽表分组聚合。
SPL
A |
B |
|
… |
/A3是销售记录表,A4 是产品信息表 |
|
8 |
D:\data\City.csv |
|
9 |
=file(A8).import@tc() |
|
10 |
=A3.switch(product,A4:productid;sale_city,A9:cityid) |
/设置主键 |
11 |
=A10.groups(sale_city.province,product.pclass;sum(amount):amount) |
/分组聚合 |
SPL 的 switch 函数可以同时建立多个外键关系,如本例中的产品号 product 与产品信息表中的 productid,城市号 sale_city 与城市信息表中的 cityid,如果需要还可以建立更多的关联关系,关联后可以利用记录的字段完成分组聚合。和 Python 不同,SPL 可以一次解析多个关联关系,这使得关联关系明确且效率更高。
维表复用
一张事实表可能多次利用同一张维表,如:
现有销售记录表和城市信息表,请找出产品销售地与产地在同一省份的销售记录。
销售记录表 2(事实表):
recordid |
product |
product_city |
sale_city |
amount |
… |
sr100001 |
p1006 |
c105 |
c103 |
603 |
… |
sr100002 |
p1005 |
c105 |
c102 |
1230 |
… |
sr100003 |
p1003 |
c102 |
c102 |
885 |
… |
… |
… |
… |
… |
… |
… |
城市信息表2(维表):
cityid |
name |
province |
… |
c101 |
Beijing |
Beijing |
… |
c102 |
Tianjin |
Tianjin |
… |
c103 |
Harbin |
Heilongjiang |
… |
… |
… |
… |
… |
Python
sr_file2="D:\data\SaleRecord2.csv" ct_file2="D:\data\City2.csv" record2=pd.read_csv(sr_file2) ct2=pd.read_csv(ct_file2) r_ct2=pd.merge(record2,ct2,left_on="sale_city",right_on="cityid") r_ct_ct=pd.merge(r_ct2,ct2,left_on="product_city",right_on="cityid",suffixes=('_s', '_p')) r_ct_p_ct= r_ct_ct[r_ct_ct['province_s']==r_ct_ct['province_p']].recordid print(r_ct_p_ct) |
事实表第一次关联维表 事实表第二次关联维表
|
本例中的销售记录包含了产品销售城市号和产品产地号,两者都关联城市信息表的 cityid 可以完成关联。Python 还是老方子,merge 两次,第二次 merge 时会产生相同的字段名,但 Python 通过增加不同的后缀很好的处理了。
SPL
A |
B |
|
… |
… |
|
13 |
D:\data\SaleRecord2.csv |
|
14 |
D:\data\City2.csv |
|
15 |
=file(A13).import@tc() |
|
16 |
=file(A14).import@tc() |
|
17 |
=A15.switch(sale_city,A16:cityid;product_city,A16:cityid) |
/事实表关联维表 |
18 |
=A17.select(sale_city.province==product_city.province).(recordid) |
SPL 通过 switch 关联同一张维表,只不过是不同的外键(sale_city 和 product_city),然后利用关联后的记录字段选出。
多层维表
外键关联可能不止一层维表,会遇到多层维表的情况,如:
现有销售记录表、产品信息表和城市信息表,请找出产品销售地与产地在同一省份的销售记录。
销售记录表 (事实表):
recordid |
product |
sale_city |
amount |
… |
sr100001 |
p1003 |
c104 |
380 |
… |
sr100002 |
p1005 |
c103 |
400 |
… |
sr100003 |
p1003 |
c104 |
626 |
… |
… |
… |
… |
… |
… |
城市信息表(维表 1):
cityid |
name |
province |
… |
c101 |
Beijing |
Beijing |
… |
c102 |
Tianjin |
Tianjin |
… |
c103 |
Harbin |
Heilongjiang |
… |
… |
… |
… |
… |
产品信息表(维表 2):
productid |
product_city |
… |
p1001 |
c104 |
… |
p1002 |
c103 |
… |
p1003 |
c102 |
… |
… |
… |
… |
Python
sr_file3="D:\data\SaleRecord3.csv" ct_file3="D:\data\City3.csv" pt_file3="D:\data\Product3.csv" record3=pd.read_csv(sr_file3) product3=pd.read_csv(pt_file3) ct3=pd.read_csv(ct_file3) pdt_ct=pd.merge(product3,ct3,left_on="product_city",right_on="cityid") r_pdt_ct=pd.merge(record3,pdt_ct,left_on="product",right_on="productid") r_pdt_ct_ct=pd.merge(r_pdt_ct,ct3,left_on="sale_city",right_on="cityid",suffixes=('_s', '_p')) r_ct_p_ct2=r_pdt_ct_ct[r_pdt_ct_ct['province_s']==r_pdt_ct_ct['province_p']].recordid print(r_ct_p_ct2) |
关联产地和城市 关联销售记录和产品 关联销售地和城市
|
城市信息既是产品的维表又是销售记录的维表,产品信息也是销售记录的维表,这就构成了多层维表,而且有维表被多次关联。Python 中三次关联三次 merge。
SPL
A |
B |
|
… |
… |
|
20 |
D:\data\SaleRecord3.csv |
|
21 |
D:\data\City3.csv |
|
22 |
D:\data\Product3.csv |
|
23 |
=file(A20).import@tc() |
|
24 |
=file(A21).import@tc() |
|
25 |
=file(A22).import@tc() |
|
26 |
=A25.switch(product_city,A24:cityid) |
/产地关联城市 |
27 |
=A23.switch(sale_city,A24:cityid;product,A26:productid) |
/销售记录关联城市和产品 |
28 |
=A27.select(sale_city.province==product.product_city.province).(recordid) |
SPL 建立关联关系后可以一直使用,即使是又被建立关联后,如 A26 中建立了产地与城市的关联关系,在 A27 中建立销售记录与产品的关联关系后,产地与城市的关联关系依旧在,所以 A28 中可以有 product.product_city.province 的引用,这在多表关联的关系中是很方便的。
自关联
有时会遇到一张表既是事实表又是维表,即自己和自己关联的情况。如:
现有员工信息表,请列出所有员工及其上级的姓名。
员工信息表部分内容如下:
empid |
name |
superior |
… |
7902 |
FORD |
7566 |
… |
7788 |
SCOTT |
7566 |
… |
7900 |
JAMES |
7698 |
… |
… |
… |
… |
… |
Python
emp_file="D:\data\Employee_.csv" emp=pd.read_csv(emp_file) emp_s=pd.merge(emp,emp,left_on="superior",right_on="empid",suffixes=('', '_m'),how="left") emp_s_name=emp_s[['name','name_m']] print(emp_s_name) |
自关联
|
Python的本质还是两表关联。
SPL
A |
B |
|
… |
… |
|
30 |
D:\data\Employee_.csv |
|
31 |
=file(A30).import@tc() |
|
32 |
=A31.switch(superior,A31:empid) |
/自关联 |
33 |
=A32.new(name,superior.name:s_name) |
SPL 也没太大的区别,switch 建立 superior 和 empid 的关联。
环状关联
关联关系复杂时,可能会发生环装关联。如:
现有员工信息表和部门信息表,请找出北京经理的北京员工。
员工信息表:
empid |
name |
dept |
province |
… |
1 |
Rebecca |
6 |
Beijing |
… |
2 |
Ashley |
2 |
Tianjin |
… |
3 |
Rachel |
7 |
Heilongjiang |
… |
… |
… |
… |
… |
… |
部门信息表:
deptid |
name |
manager |
… |
1 |
Administration |
20 |
… |
2 |
Finance |
2 |
… |
3 |
HR |
162 |
… |
… |
… |
… |
… |
Python
emp_file2="D:\data\Employee_2.csv" dept_file2="D:\data\Department2.csv" emp2=pd.read_csv(emp_file2) dept2=pd.read_csv(dept_file2) d_emp=pd.merge(dept2,emp2,left_on="manager",right_on="empid") emp_d_emp=pd.merge(emp2,d_emp,left_on="dept",right_on="deptid",suffixes=('', '_m')) beijing_emp_m=emp_d_emp[(emp_d_emp['province']=="Beijing") & (emp_d_emp['province_m']=="Beijing")].name print(beijing_emp_m) |
部门表关联员工表 员工表关联部门表
选出
|
Python的两步关联相对独立,两步构成一个环状关联,形成一个宽表,最后选出。
SPL
A |
B |
|
… |
… |
|
35 |
D:\data\Employee_2.csv |
|
36 |
D:\data\Department2.csv |
|
37 |
=file(A35).import@tc() |
|
38 |
=file(A36).import@tc() |
|
39 |
=A38.switch(manager,A37:empid) |
/部门关联员工表 |
40 |
=A37.switch(dept,A38:deptid) |
/员工表关联部门表 |
41 |
=A40.select(province=="Beijing"&&dept.manager.province=="Beijing").(name) |
/选出 |
SPL 第一步建立部门和员工的关联关系,第二步建立员工和部门的关联关系,第三步选出,建好的关联关系可以直接拿来使用。上述的所有案例都是用 switch 函数完成关联,它有一个特点:关联后本身的字段值会被替换为关联后的记录,本身的记录值就不存在了,如果想保留本身的记录值可以用 join 函数完成关联,如本例的 A40 可以这样写:A40=A37.join(dept,A38:deptid,~:dpt),此时的 dept 就是关联后的记录,利用该记录引用就可以完成后续计算了,之前例子中的 switch 都可以用这种方式完成计算。
混合关联
数据分析中,可能会遇到同维关联、主子关联、外键关联同时发生的混合关联,此时的关联关系复杂,要理清楚关联关系。如:
利用订单表,订单明细表,产品信息表,员工信息表,出差信息表,客户信息表,城市信息表,计算出差时间大于 10 天的 90 后销售员在各省份销售黑龙江商品的金额。
关联关系如下:
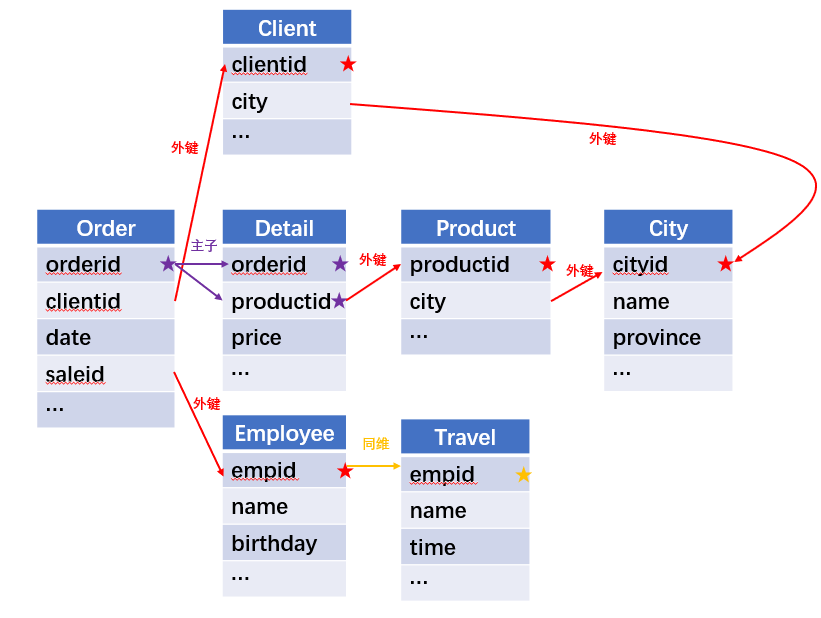
Python
emp4 = pd.read_csv("D:\data\Employee4.csv") trv4 = pd.read_csv("D:\data\Travel4.csv") emp_inf = pd.merge(emp4,trv4,on=["empid","name"]) years = pd.to_datetime(emp_inf.birthday).dt.year emp_inf_c = emp_inf[(years>=1990) & (years<2000)&(emp_inf.time>=10)] clt4 = pd.read_csv("D:\data\Client4.csv") city4 = pd.read_csv("D:\data\City4.csv") sale_location = pd.merge(clt4,city4,left_on='city',right_on='cityid') pdt4 = pd.read_csv("D:\data\Product4.csv") pdt_location = pd.merge(pdt4,city4,left_on='city',right_on='cityid') detail4 = pd.read_csv("D:\data\Detail4.csv") order4 = pd.read_csv("D:\data\Order4.csv") detail_pdt = pd.merge(detail4,pdt_location,on='productid',how="left") order_sale_location = pd.merge(order4,sale_location,on='clientid',how="left") order_sale_location_emp = pd.merge(order_sale_location,emp_inf_c,left_on='saleid',right_on='empid',how="left",suffixes=('_c', '_e')) order_inf = order_sale_location_emp[order_sale_location_emp.empid.notnull()] order_detail = pd.merge(order_inf,detail_pdt,on='orderid',how="left",suffixes=('_s', '_p')) order_detail_Hljp = order_detail[order_detail.province_p=="Heilongjiang"] res = order_detail_Hljp.groupby(['empid','name_e','province_s'],as_index=False).price.sum() print(res) |
员工表和出差表
选出 90 后
客户表和城市表
产品表和城市表
订单明细和产品 订单和出售地
订单和员工
订单和订单明细 选出
分组聚合 |
本例中表很多,关联关系很复杂,按照我们介绍的 3 种关系关联: 同维关联(一对一),主子关联(一对多),外键关联(多对一)进行关联,如果出现了多对多的关联关系,那多半是错了,需要重新检查关联关系,否则多对多关联后很可能导致内存爆炸。Python 面对如此复杂的关联关系时,最好就是用 merge 两两关联,一步解析一个关联关系,虽然稍麻烦,但不容易出错。
SPL
A |
B |
|
… |
… |
|
43 |
=file("D:/data/Employee4.csv").import@tc() |
|
44 |
=file("D:/data/Travel4.csv").import@tc() |
|
45 |
=A44.join(empid,A43:empid,birthday) |
|
46 |
=A45.select((y=year(birthday),y>=1990&&y<2000&&time>=10)) |
|
47 |
=file("D:/data/Client4.csv").import@tc() |
|
48 |
=file("D:/data/City4.csv").import@tc() |
|
49 |
=A47.join(city,A48:cityid,province) |
|
50 |
=file("D:/data/Product4.csv").import@tc() |
|
51 |
=A50.join(city,A48:cityid,province) |
|
52 |
=file("D:/data/Detail4.csv").import@tc() |
|
53 |
=file("D:/data/Order4.csv").import@tc() |
|
54 |
=A52.join(productid, A51:productid,province:product_province) |
|
55 |
=A54.group(orderid) |
|
56 |
=A53.switch(orderid, A55:orderid;saleid, A46:empid;clientid, A49:clientid) |
|
57 |
=A56.select(saleid).new(saleid.empid:empid,saleid.name:sale_name,clientid.province:sale_location,orderid.select(product_province=="Heilongjiang").sum(price):price) |
|
58 |
=A57.groups(empid,sale_name,sale_location;sum(price):price).select(price) |
SPL 面对如此复杂的关联关系时,就显得很从容,同维、主子、外键关联关系都很明了,需要同时关联两个关联关系时,SPL 也可以同时解决,快捷还不易出错。
小结
Python 进行外键关联时,同样存在复制数据、每次只能解析一个关联关系的问题,另外每一次关联都是独立的,之前建立的关联关系,后续不可以重复利用,只能重新关联,这使得关联效率比较低。
SPL 不存在类似的问题,建立一次关联关系后,可以重复利用,运算效率更高。


英文版