


Python 和 SPL 对比 8——有序分组
人们对序运算天然是感兴趣的,分组运算也会涉及到次序。本文对比 Python 和 SPL 在有序分组的运算能力。
位置分组
成员的位置信息可能参与分组计算中,分组键也有可能是和成员位置(或序号)相关的。如:
现有如下数据:
time a b
0 0.5 -2.0
1 0.5 -2.0
2 0.1 -1.0
3 0.1 -1.0
4 0.1 -1.0
5 0.5 -1.0
6 0.5 -1.0
7 0.5 -3.0
8 0.5 -1.0
希望每三行分成一组,并把众数作为该组的结果。期望结果如下:
time a b
2 0.5 -2.0
5 0.1 -1.0
8 0.5 -1.0
Python
import pandas as pd file1="D:/data/position.txt" data1=pd.read_csv(file1,sep="\t") pos_seq=[i//3 for i in range(len(data1))] res1=data1.groupby(pos_seq).agg(lambda x:x.mode().iloc[-1]) print(res1) |
按位置衍生一列,按除 3 的整数商分组 按衍生列分组聚合
|
每 3 行分一组,只要序号除 3 取整就可以得到分组键,按此键分组即可。取众数也是聚合运算,用 agg+lambda 表达式就可以得到结果。
SPL
A |
B |
|
1 |
D:\data\position.txt |
|
2 |
=file(A1).import@t() |
|
3 |
=A2.group((#-1)\3).new(~.max(time):time,~.mode(a):a,~.mode(b):b) |
/分组聚合 |
SPL可以利用”#”来得到分组键,不需要单独计算一列分组键。这里的分组键是整数,SPL 还有一种针对自然数分组的高效分组方法,那就是 group@n(),因为可以直接用序号找到正确的分组子集,不需要做比较运算,所以运算速度更快,这里稍微改造一下代码就行:
A3=A2.group@n((#+2)\3)...
值变化分组
有时数据本身是有序的,但分组时只希望把相邻的相同值分到一组,如:
有数据如下:
duration location user
0 10 house A
1 5 house A
2 5 gym A
3 4 gym B
4 10 shop B
5 4 gym B
6 6 gym B
当 user 和 location 连续相同时对 duration 进行求和,location 变化时则重新求和。期望结果如下:
duration location user
15 house A
5 gym A
4 gym B
10 shop B
10 gym B
Python
file2="D:/data/value.txt" data2=pd.read_csv(file2,sep="\t") value_seq=(data2.location!=data2.location.shift()).cumsum() res2=data2.groupby(['user','location',value_seq], as_index=False, sort=False)['duration'].sum() print(res2) |
衍生列,相邻 location 相同该列值相等,不同则 +1 按 [user,location, 衍生列] 分组聚合
|
Python没有相邻成员相同分一组的功能,只能自己想办法衍生一列,把该列作为部分分组键分组才可以完成,而想出来比较简单的衍生列并没有那么容易,需要烧烧脑。
SPL
A |
B |
|
… |
… |
|
4 |
D:\data\value.txt |
|
5 |
=file(A5).import@t() |
|
6 |
=A6.groups@o(user,location;sum(duration)) |
/值变化分组 |
SPL 中 groups@o() 函数将依次扫描整个序列,当分组键值和上一个成员的分组键相同时,则将该成员加入到当前的分组子集,如果分组键值发生变化了,则产生一个新的分组子集并加入当前成员,扫描完之后就得到一批分组子集,从而完成分组运算。不需要自己烧脑去想衍生列,书写的方式也只是比 groups 多了个 @o 选项,这种分组只比较相邻值,分组速度更快,这是 Python 的 groupby 做不到的。
条件变化分组
数据本身有序时,还有一种情况就是条件变化时分一组。如:
现有数据如下:
ID code
333_c_132 x
333_c_132 n06
333_c_132 n36
333_c_132 n60
333_c_132 n72
333_c_132 n84
333_c_132 n96
333_c_132 n108
333_c_132 n120
999_c_133 x
999_c_133 n06
999_c_133 n12
999_c_133 n24
998_c_134 x
998_c_134 n06
998_c_134 n12
998_c_134 n18
998_c_134 n36
997_c_135 x
997_c_135 n06
997_c_135 n12
997_c_135 n24
997_c_135 n36
996_c_136 x
996_c_136 n06
996_c_136 n12
996_c_136 n18
996_c_136 n24
996_c_136 n36
995_c_137 x
希望从 code 列的每两个 x 中间随机取一行
期望结果如下:
333_c_132 n06
999_c_133 n12
998_c_134 n18
997_c_135 n36
996_c_136 n18
Python
file3="D:/data/condition.txt" data3=pd.read_csv(file3,sep="\t") cond_seq=data3.code.eq('x').cumsum() res3=data3[data3.code.ne('x')].groupby(cond_seq).apply(lambda x:x.sample(1)).reset_index(level=0,drop=True) print(res3) |
衍生列 按衍生列分组再抽样
|
Python的思路和之前两个例子是一样的,都需要自己烧脑衍生出一列分组键,然后按这列来分组,在抽样时 Python 提供了抽样函数 sample(),使得抽样更加便捷。
SPL
A |
B |
|
… |
… |
|
9 |
D:\data\condition.txt |
|
10 |
=file(A9).import@t() |
|
11 |
=A10.group@i(code=="x").conj((l=~.len(),if(l<2,,~.m(2:)(rand(l-1)+1)))) |
/条件变化分组 |
SPL 中 group@i() 的分组键是个表达式,每当计算出 true 时则产生一个新的分组子集,也就是满足某个条件时就重新分一组,同样不需要烧脑想衍生列,运算效率也更高,SPL 中暂时没有提供抽样函数,需要自己手动来写抽样这一动作,不过这对于 SPL 也很简单,利用 rand() 可以轻松完成。
这里要多说一句,@o 选项和 @i 选项既对在 groups 有效,也对 group 有效,效果也相同。
在日志处理时,本文介绍的三种有序分组都有很好的效果。
1. 固定行数日志处理
日志形式如下图:
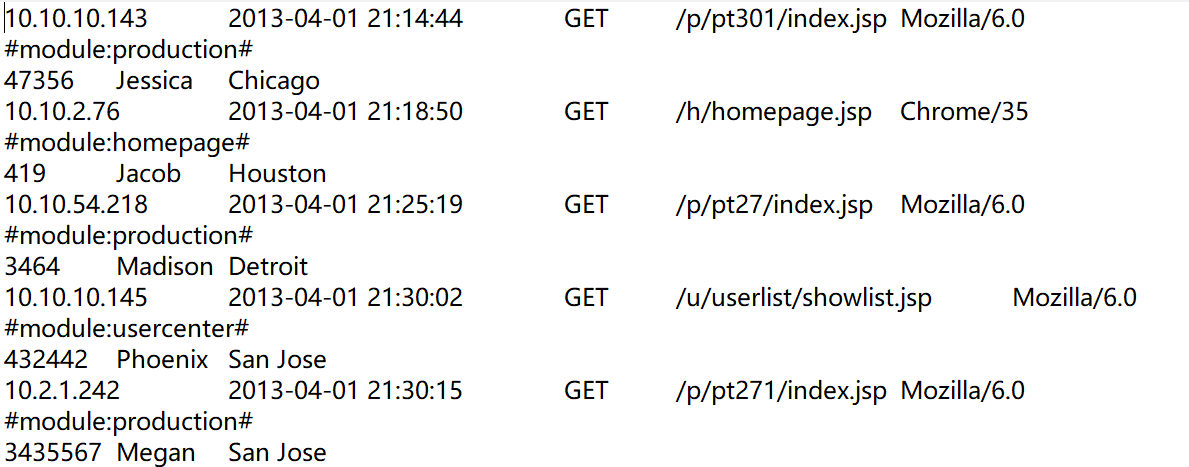
第一行是 IP,TIME,GET,URL,BROWER;
第二行是 MODULE;
第三行是 USERID,UNAME,LOCATION
此时只要 group((#-1)\3),再处理各组的日志就可以了。
2. 行数不固定但每行都有标记的日志
日志形式如下:

每个用户的行数不同,但每行开始都有用户的 ID。
此时只要 group@o(~.split(“\t”)(1)),然后处理各组日志。
3. 行数不固定但有一个开始标记
日志形式如下:
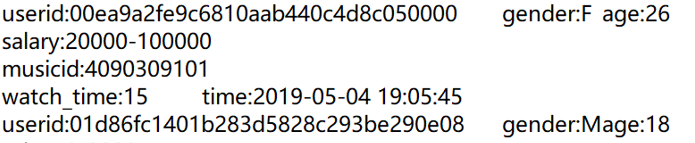
每个用户的行数不同,但每个用户都有一个开始标记 userid。
此时只要 group@i(~.split(“:”)(1)==”userid”),然后处理各组日志。
小结
Python 对待有序和无序的分组是一样的,不能利用有序这一条件来提高效率,要想办法算出一个衍生列,让其符合分组的条件,是舍近求远的方法。
SPL 可以充分利用数据有序的优势,使得分组更快,也不需要自己去算衍生列,只要把分组条件写好就可以了,形式上也只是增加个选项 @n,@o 或 @i,简单实用。


英文版