


Python 和 SPL 对比 3——循环函数
针对集合每个成员计算,遍历后得出一个新结果的函数,我们通称为循环函数。Python原生的 list 循环函数太少了,稍微复杂一些的循环就得用 for 来写了,所以这里就不介绍了,我们主要对比 Pandas 和 SPL 中的循环函数。
基本聚合运算
求和、平均等都是常见的聚合运算。
以求和函数为例介绍:
计算前一百个正整数之和。
Python代码:
import pandas as pd |
导入 pandas 库 |
SPL代码:
A |
B |
|
1 |
=to(100) |
/生成序列 |
2 |
=A1.sum() |
/求和 |
Pandas和 SPL 都提供了这类聚合运算,都可以轻松的算出结果, Pandas 中的聚合运算函数还更加丰富,比如有比较完善的统计学函数,而 SPL 的统计学函数暂时还不完善。
聚合前处理
在聚合之前,有时需要对集合中的每个元素处理后再运算。
如:计算前 100 个奇数之和。
Python代码:
#s是 [1,2,…,100] 的 Series |
|
SPL代码:
A |
B |
|
1 |
=to(100) |
/生成序列 |
2 |
=A1.sum(~*2-1) |
/用 ~ 表示当前元素 |
为了计算前 100 个奇数,Python 使用了令人费解的 apply 函数和 lambda 表达式,apply 是循环执行某个函数, lambda 表达式则相当于是个函数,对 Serires 中的某个元素执行这个函数。SPL 巧妙的利用符号“~”来完成 lambda 表达式的运算,使代码非常简单,只要理解了“~”表示循环时的当前元素即可,A.sum(…) 又等同于 A.(…).sum(),这就是循环后求和,稍加思考即可理解。
再看一个稍微复杂点的例子:
计算自然底数 e:
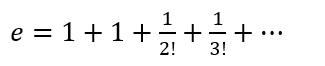
Python代码:
#s是 [1,2,…,20] 的 Series |
|
SPL代码:
A |
B |
|
1 |
=to(20) |
/生成序列 |
2 |
=nf=1,1+A1.sum((nf*=~,1/nf) ) |
/用 ~ 表示当前元素 |
Python的做法很简单,先求出阶乘,然后循环,求和得到结果。但仔细想想这个有点简单粗暴了,每次算阶乘时都在重复 n-1 之前的阶乘动作,而 n-1 之前的结果刚好可以用来求自然底数,本来遍历一遍就解决了,Python 的 lambda 表达式却写不出来。SPL 只要先定义一个变量 nf,循环函数里边循环边更新,这样只要遍历一遍序列就把结果计算出来了,效率提高非常多。
相邻引用
循环函数除了用到集合中的元素外,有时还会用到集合中相邻位置的信息。。
还是看个具体的例子:
集合[123,345,321,345,546,542,874,234,543,983,434,897]是某个商家1年中每个月的销售额,请算出这一年中最大的月增长额是多少。
Python代码:
sales=[123,345,321,345,546,542,874,234,543,983,434,897] |
|
SPL代码:
A |
B |
|
1 |
[123,345,321,345,546,542,874,234,543,983,434,897] |
/生成序列 |
2 |
=A1.(if(#>1,~-~[-1],0)).max() |
/~[-1]距离当前元素之前 1 个位置的元素 |
Python中提供了计算之前一个元素的方法shift,但并没有提供循环时利用位置信息的方法,这样无形中又多遍历了1次集合,效率必然会打折扣。而SPL则是通过~[-1]充分利用位置关系,遍历一遍就将相邻元素的差计算出来,代码写起来简单流畅。
有时还会同时用到当前元素前后几个元素。
比如:还是那家店铺的一年的销售额,请计算每月及其前后各一个月的销售额的平均值。
Python代码:
sales=[123,345,321,345,546,542,874,234,543,983,434,897] |
|
SPL代码:
A |
B |
|
1 |
[123,345,321,345,546,542,874,234,543,983,434,897] |
/生成序列 |
2 |
=A1.(avg(~[-1:1])) |
/~[-1:1]距离当前位置前一个位置到后一个位置全部元素 |
Python中 Rolling 又是一个新函数,上个问题和这个问题是一类问题,都用 shift 或者都用 rolling 的话可以理解,偏偏是完全不同的两个函数,在使用上完全不成体系,除了死记这些方法外貌似也没有更有效的方法了。再看 SPL,~[-1] 是距离当前位置之前一个位置的元素,~[-1:1] 是距离当前位置之前和之后一个位置的所有元素,很容易举一反三,运行效率还高。
小结
虽然 Python 中原生的循环函数很少,但 Pandas 对此进行了弥补,使用上方便了不少,比如一些常用的统计学方法在 Pandas 里都可以找得到,这相较于在统计学方面暂时尚未成熟的 SPL 来说还是很有优势的;但同时 Pandas 的方法又太多太凌乱,完全不成系统,就像本篇文章中的几个例子,本来都在“循环函数”这个框架下,但 Pandas 的解决方法是一题一方法,更像是为了解决问题而解决问题,方法之间不搭边,用户在使用时也只能东一榔头西一棒槌的调用方法了。
SPL就要好的多,总体都是在 A.() 这一循环函数的框架内,对循环时的元素进行相应的处理即可,举一反三自然不在话下,遍历一遍就解决的问题不会遍历第二遍,运行效率相较于 Python 也高了很多。


英文版