


SPL:访问 HBase
HBase是基于HDFS的K-V数据库,有关系数据库中类似的概念:库(namespace)、表、行、列、字段值、主键等。
HBase存取数据和关系数据库大不相同,不支持SQL,提供了get、scan、filter等几个操作,只能简单地存取数据,没有分组、聚合、排序、子查询等计算能力。计算引擎SPL通过封装HBase提供的Java API、Rest API,能方便地存取HBase数据,正好弥补HBase的计算能力。
创建/关闭HBase连接
使用方式类似关系数据库的JDBC连接,SPL也用成对的“创建/关闭”方式连接HBase。
hbase_open(hdfsUrl, zkUrl1,zkUrl2…),第一个参数是HDFS URL,之后的是Zookeeper URL,可以有多个Zookeeper URL。
hbase_close(hbaseConn),hbaseConn是要关闭的HBase连接。
示例:A1创建连接,中间做一些读写、计算操作后,A3关闭A1创建的连接
A |
|
1 |
=hbase_open("hdfs://192.168.0.8", "192.168.0.8") |
2 |
…… |
3 |
=hbase_close(A1) |
查询单行数据
HBase用get操作查询单行数据、用scan查询多行数据。这一节先了解查询单行数据的SPL函数:
hbase_get(hbaseConn,tableName,rowName,family1:column1:type1:alias1,family2:column2:type:alias2,... ; filter:f,timeRange:[t1,t2],timeStamp:t)。参数用分号分成两部分:
第一部分,hbaseConn是创建的连接;tableName是表名;rowName是要查询行的健值;如果需要指定选出的列,后面可以跟多个选出列的定义,每个列完整的定义是family:column:type:alias,依次为列簇(family)名、列名、列的数据类型(把HBase中的字符串自动自动加载成这里指定的数据类型)、列别名。
第二部分,三个参数,filter是过滤条件,timeRange是待查数据版本的时间戳范围,timeStamp是明确指定某待查数据版本的时间戳。SPL提供了hbase_filter()等函数包装HBase的多种filter,在下面专门的章节再细讲。注意,HBase除了有过滤行的filter,还有过滤列簇、列、时间戳的filter,因此,用行键值get单行数据时,也可能用到filter。
示例:
A |
|
1 |
=hbase_open("hdfs://192.168.0.8", "192.168.0.8") |
2 |
=hbase_get(A1,"Orders","row1") |
3 |
=hbase_get(A1,"Orders","row1","datas:Amount":number:amt,"datas:OrderDate": date:od) |
4 |
=hbase_filter("ColumnCountGetFilter",2) |
5 |
=hbase_get(A1,"Orders","26";filter:A4) |
6 |
=hbase_get(A1,"Orders","26";timeStamp:1641785173116) |
7 |
=hbase_get(A1,"Orders","26";timeRange:[1641388111781,1642388111782]) |
8 |
=hbase_close(A1) |
A2查询只有表名、行键值,其它参数都省略掉,将查询出整行最新版本的数据。

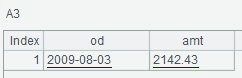
A3查询列簇datas下的Amount、OrderDate两列,指明数据类型为数值、日期,结果中的列别名为amt、od:
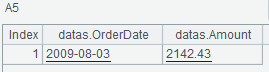
A4生成一个取前两列的filter,A5查询使用A4的filter:
A6用时间戳1641785173116(毫秒数)查询该行,如果含有这个时间戳更新的字段值,就查出这个时间戳版本的值。

A7查询时间戳在[1641388111781,1642388111782)之间的数据:

查询多行数据
继续看查询多行数据的scan操作的SPL函数:
hbase_scan(hbaseConn,tableName,family1:column1:type1:alias1,family2:column2:type:alias2,... ; rowPrefix:x,startRow:startrow,stopRow:stoprow,filter:f,timeRange:[t1,t2],timeStamp:t)。参数和hbase_get类似,也是用分号分成两部分,这里只介绍和hbase_get参数的不同部分:
第一部分,因为是查找多行,因此不需要行键值rowName了。
第二部分,多了三个参数,rowPrefix是待查询行主键的前缀,startRow和stopRow实现分页功能,从所有符合条件的数据行中取出startRow到stopRow的行。
hbase_scan的结果默认是SPL内存序表,如果遇到结果数据特别多,内存无法一次装下,可以用@c选项,这时返回游标,方便一部分一部分地取出数据,边取数据边计算。
示例:
A |
|
1 |
=hbase_open("hdfs://192.168.0.8", "192.168.0.8") |
2 |
=hbase_scan(A1,"Orders") |
3 |
=hbase_scan@c(A1,"Orders") |
4 |
=A3.fetch(3) |
5 |
=hbase_scan(A1,"Orders";rowPrefix:"row") |
6 |
=hbase_scan(A1,"Orders";startRow:2,stopRow:4) |
7 |
=hbase_close(A1) |
A2查询只有表名,其它参数都省略掉,查询全表最新版本的数据。
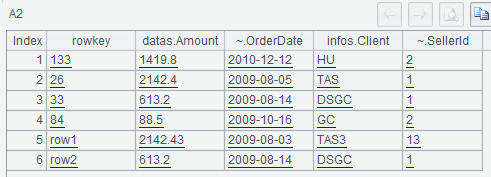
A3用@c选项得到查询结果的SPL游标,A4从A3游标中取3行数据:
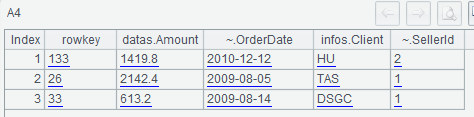
A5查询行健值以"row"为前缀的行:
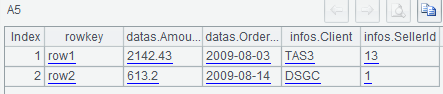
A6查询时,结果只返回第[2,4)行,也就是第2(含)到4(不含)行数据。

过滤功能
HBase提供了多种过滤器,其语法是FilterName(argument1,argument2,…),每种过滤器会有一个固定的名称,如
ColumnCountGetFilter(3);
FirstKeyOnlyFilter()
QualifierFilter(">=",'binary:xyz')
…
可以看出来,不同filter的参数个数,参数类型不尽相同,ColumnCountGetFilter的参数是要取的列数,这是数值类型的常量参数;FirstKeyOnlyFilter只取行键值列,不需要参数;FamilyFilter,按列簇名过滤,第一个参数是比较符(>、>=、=、!=、<、<=)、第二个参数是比较器(BinaryComparator 、BinaryPrefixComparator 、RegexStringComparator 、SubStringComparator等 )。
多个过滤器还有组合起来使用的情况,组合关系有AND、OR、SKIP、WHILE,以及可以嵌套的括号。
SPL用hbase_filter()实现过滤器,用hbase_cmp()实现比较器,用hbase_filterlist()实现多个过滤器的组合。
过滤器
hbase_filter(filterName,argument1,argument2,…) ,filterName是过滤器名称,可以去《HBase官网》详细了解它提供的十几种过滤器。过滤器不同,需要参数的个数和类型有差异,都跟在名称后面即可。
示例:
A |
|
1 |
=hbase_open("hdfs://192.168.0.8", "192.168.0.8") |
2 |
=hbase_filter("ColumnCountGetFilter",2) |
3 |
=hbase_scan(A1,"Orders";filter:A2) |
4 |
=hbase_filter("FirstKeyOnlyFilter") |
5 |
=hbase_scan(A1,"Orders";filter:A4) |
6 |
=hbase_filter("FamilyFilter","=",hbase_cmp@p("inf")) |
7 |
=hbase_scan(A1,"Orders";filter:A6) |
8 |
=hbase_close(A1) |
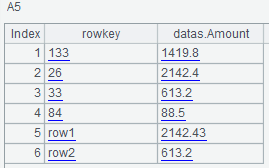
A2的ColumnCountGetFilter,取前2列,A3使用A2过滤器查询:
A4的FirstKeyOnlyFilter,只取行键值列,A5使用A4过滤器查询:
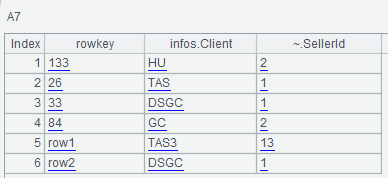
A6的FamilyFilter,取列簇名以inf开头的列,用到的比较器函数hbase_cmp()在下面详细介绍,A7使用A6过滤器查询:
这三种过滤器的参数比较有代表性,其它过滤器都类似,就不一一介绍了。
比较器
hbase_cmp(compareValue,comparatorArgument),compareValue是被比较的阈值,有的比较器需要额外控制参数comparatorArgument。通过函数选项决定使用哪个比较器,无选项时默认为BinaryComparator;
hbase_cmp@p(compareValue),@p选项表示用BinaryPrefixComparator;
hbase_cmp@s(compareValue),@s选项表示用SubstringComparator;
hbase_cmp@l(compareValue),@l选项表示用LongComparator;
hbase_cmp@d(compareValue),@d选项表示用BigDecimalComparator;
hbase_cmp@r(compareValue,comparatorArgument),@r选项表示用RegexStringComparator这个比较器,控制参数comparatorArgument可以包含i、m、d、u、q、x、l、c。i表示大小写不敏感,m表示可以匹配多行,d表示“.”可以表示任意字符,u表示对Unicode字符不区分大小写,q 表示匹配完全正则分解,x 表示换行符为 unix 风格,l 表示纯文本模式,c 表示注释模式
如hbase_cmp@r("ab.c\nd","idx"),正则表达式匹配时,大小写不敏感、“.”可以表示任意字符、unix风格换行。
hbase_cmp@b(compareValue,,comparatorArgument),@b选项表示用BitComparator;这个是按位比较,comparatorArgument参数可以是and、or、xor,分别表示按位与、按位或、按位异或。
hbase_cmp@c(compareValue,comparatorArgument),@c选项表示用BinaryComponentComparator;comparatorArgument是一个整数值,表示匹配字节时的偏移量。
如hbase_cmp@r("abc",10),从被匹配值的第10个字节开始匹配"abc"。
从上节的示例代码能看到,过滤器的控制参数可能用到这些比较器。
组合过滤
(filter1 AND filter2) OR (filter3 AND filter4)
如上,几个条件用and、or组合时,用SPL的hbase_filterlist(filterA, filterB, …)实现,参数中的filter既可以是hbase_filter(),也可以是嵌套的hbase_filterlist()。如下例A6中,两个内层的hbase_filterlist()用AND两两组合filter1~filter4,最外层hbase_filterlist()的@o选项表示用OR方式组合内层的两个hbase_filterlist()。
A |
|
1 |
=hbase_open("hdfs://192.168.0.8", "192.168.0.8") |
2 |
>filter1=hbase_filter("FamilyFilter","=",hbase_cmp@p("datas")) |
3 |
>filter2=hbase_filter("ColumnPrefixFilter","Amo") |
4 |
>filter3=hbase_filter("FamilyFilter","=",hbase_cmp@p("infos")) |
5 |
>filter4=hbase_filter("ColumnPrefixFilter","Cli") |
6 |
=hbase_listfilter@o(hbase_listfilter(filter1,filter2), hbase_listfilter(filter3,filter4)) |
7 |
=hbase_scan(A1,"Orders";filter:A6) |
8 |
=hbase_close(A1) |
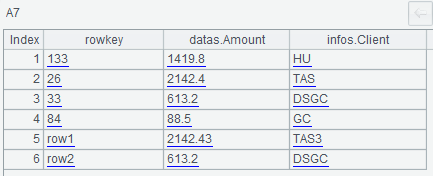
查询条件为:(列簇名等于datas AND 列名前缀为Amo) OR (列簇名等于infoss AND 列名前缀为Cli),A7查询出了符合条件的结果:
RestAPI的通用功能函数
HBase的RestAPI 能获取集群信息,增删改namespace、table,用get、scan查询数据、用put操作增删改数据。SPL提供了如下的函数实现RestAPI:
hbase_rest(restUrl, method, content; httpHeader1, httpHeader2, …),第一个参数rest链接地址;第二个参数是HTTP method,值可能是GET/PUT/POST/DELETE;第三个参数是HTTP请求提交的内容,但也有些操作不提交任何内容,这个参数就可以省略。分号后面是多个HTTP header,如果没有,也可以省略。每种Rest的HTTP请求,使用哪种method,提交什么内容,设置哪些HTTP header,这些细节参考其官网《Rest文档》。
调用hbase_rest()函数,会独立执行一个完整的HTTP请求,不需要预先创建HBase连接。
示例:
A |
|
1 |
=hbase_rest("http://127.0.0.1:3456/namespaces","GET") |
2 |
=A1.Content.split("\n") |
3 |
'<?xml version="1.0" encoding="UTF-8"?> <TableSchema name="Orders"> <ColumnSchema name="infos" /> <ColumnSchema name="datas" /> </TableSchema> |
4 |
=hbase_rest("http://127.0.0.1:3456/Orders/schema","PUT",A3;"Content-Type: text/xml","Accept: text/xml") |
5 |
=hbase_rest("http://127.0.0.1:3456/namespaces/default/tables","GET") |
6 |
=A5.Content.split("\n") |
7 |
=$[<?xml version="1.0" encoding="UTF-8" standalone="yes"?><CellSet><Row key=${"\""+base64("row1":"UTF-8")+"\""}><Cell column=${"\""+base64("infos:Client":"UTF-8")+"\""}>${base64("TAS":"UTF-8")}</Cell> ...... </Row></CellSet>] |
8 |
=hbase_rest("http://127.0.0.1:3456/Orders/fakerow","PUT",string(A7);"Content-Type: text/xml","Accept: text/xml") |
9 |
=hbase_rest("http://127.0.0.1:3456/Orders/row1","GET";"Accept:text/xml") |
10 |
=xml@s(A9.Content) |
11 |
=A10.CellSet.Row.derive(base64(Cell,"UTF-8"):CellValue,base64(column,"UTF-8"):columnName) |
12 |
=hbase_rest("http://127.0.0.1:3456/Orders/scanner/","PUT","<Scanner batch=\"1\"/>";"Content-Type:text/xml","Accept:text/xml") |
13 |
=hbase_rest(A12.Location,"GET") |
hbase_rest()函数返回所有HTTP响应的信息。在各种rest操作中,重要信息大多出现在HTTP的Content中,但也可能在Message、或之后出现的Location中。如A1获取所有namespace:

A1中返回的多个namespace是一个字符串,A2用split函数转换成序列,就容易观察了。
A3的xml定义了一个表,其中有infos、datas两个列簇,A4用hbase_rest()函数提交A3的表定义,执行结果显示Created,创建表成功了:

A5查询“default”namespace下的表:

A6观察A5结果中Content,能看到之前新建的Orders表了:
A7定义待插入Orders表的数据(xml格式),它的列名、数据都要求是base64编码,用SPL的base64()函数对需要的部分进行编码,执行后,能看到含有base64编码的xml字符串:

A8用hbase_rest()提交A7的表数据,看到执行结果为“OK”:

A9用hbase_rest()执行HBase的GET操作,查询行键值为row1的数据,得到结果:

A9中得到的结果是xml格式,不方便查看和计算,A10用SPL的xml()函数把它转换成嵌套序表:
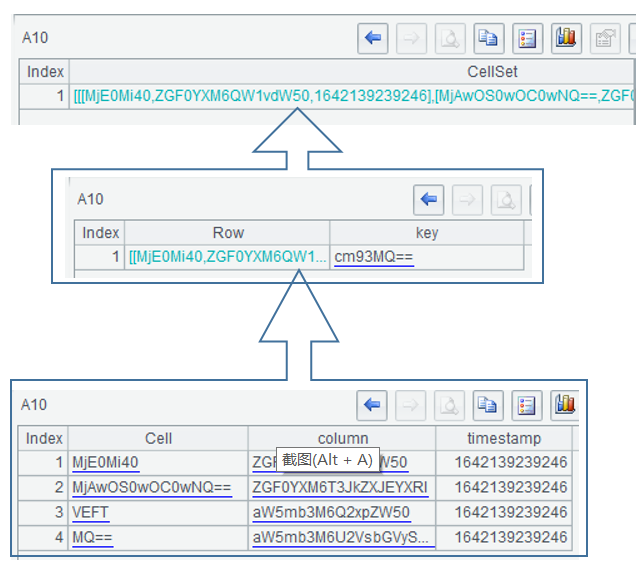
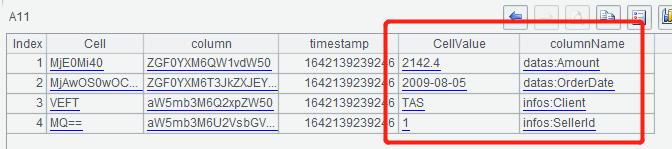
A10中的行数据在CellSet.Row序表里,但发现它里面列值(Cell字段)、列名(column字段)都是base64的编码,A11用derive()函数计算出两个新字段CellValue、columnName,通过base64()函数base64解码,得到新列的值:
A12创建一个HBase的SCAN操作,返回的Location中的url含有SCAN ID:

A13用A12的SCAN ID取查询数据。A12中的SCAN操作指定了batch=1,所以每次也就只取一条数据:



英文版