


SPL 的倍增分段
大数据通常是需要外存的,要实现外存并行计算必须有较好的数据分段技术。也就是能方便的把数据拆分成若干部分,让每个线程或进程分别处理。
SPL 采用倍增分段技术,实现了单文件可追加分块方案,在并行计算中的优势非常突出。这里,模拟向一个二进制文件写入数据的过程,详细剖析倍增分段的原理。我们主要看多线程的情况,多进程也是类似的。
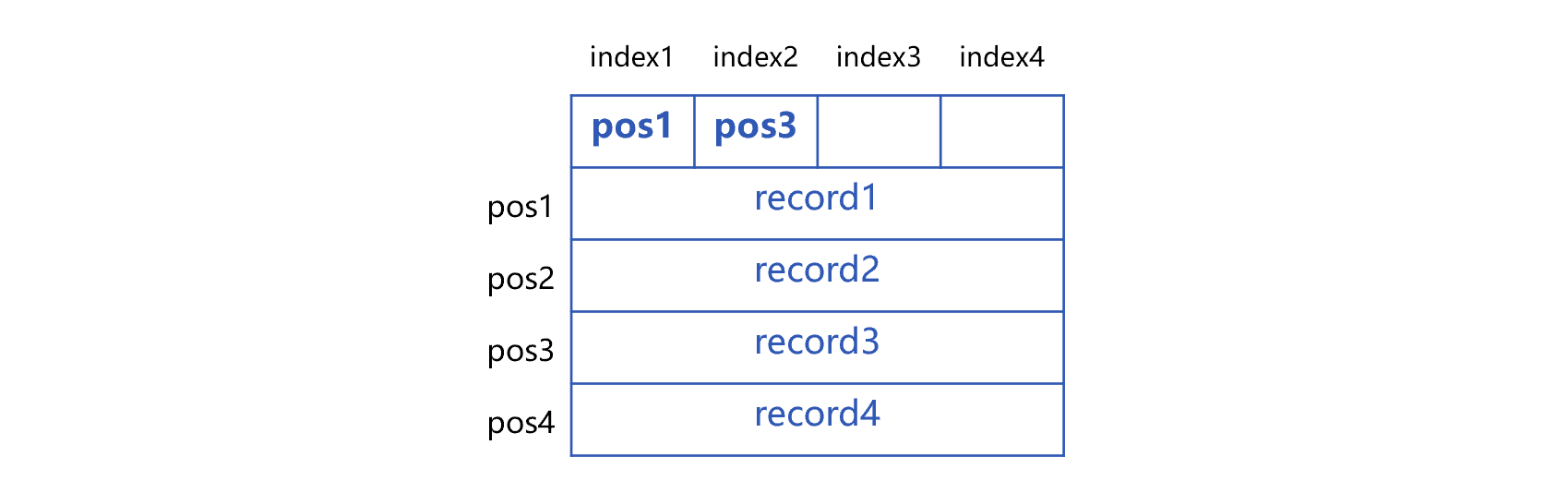
倍增分段需要在二进制文件头部预留固定长度的索引区。为了便于理解,我们假设索引区长度 N 为 4。也就是说,索引区有 4 个索引位 index1 到 index4。在索引区之后,写入 4 条连续的记录,二进制文件是这个样子:

上图中,存储数据的部分称为数据区。4 条记录开头的字节位置用 pos1 到 pos4 表示,要写入索引区的对应索引位。4 条数据物理上是连续的,没有任何分隔符或者空白区。以这 4 个字节位置 pos1 到 pos4 为界,可以将数据区划分为 4 部分,称为 4 个区块。每个区块包括 1 条记录,也就是区块容量为 1。
并行计算时,可以将每个区块作为一个分段,也可以将连续的多个区块组合成一个分段。例如,两线程并行时要分成两段,第一段从 pos1 开始到 pos3 的前一个字节为止;第二段从 pos3 开始到文件结尾为止。每一段都包含两个连续区块。
向数据区继续追加第 5 条记录之前,索引区已经没有空位了。这时候先要修改索引区,index1 不动,index2 改为原 index3 内容,index3、index4 清空。修改后,原有的 4 个区块合并成了 2 个,每个区块变成了 2 条记录,区块容量翻倍,这个过程我们称为倍增。这时二进制文件会变成这个样子:
倍增后追加第 5 到 8 条记录,index3 写入 pos5,index4 填入 pos7,文件会变成下图这样:

这时候,数据区共有 4 个区块,每个区块 2 条记录。我们看到,在追加数据和倍增的过程中,区块的数量、起止位置和容量都在改变,也就是说,区块对数据区的划分是变化的,是一种动态分块。
继续追加第 9 条记录时,索引区又没有空位了。这时候用同样的办法修改索引区:index1 不动,index2 改为原 index3 内容,index3、index4 清空。此时完成了第二次倍增,实际区块合并为 2 个,每个区块变成了 4 条记录,区块容量第二次翻倍。
倍增后再追加第 9 条记录,index3 中写入 pos9。数据区变为 3 个区块,前两个都有 4 条记录,最后一个是 1 条记录,也就是下面的样子:

以此类推,不断追加数据、不断倍增。在这个过程中,记录数不断增加,固定索引区不断修改。但是,固定索引区的长度始终没有变,实际区块数保持在 2 到 4 之间。且每个区块的记录数基本保持一致,只有最后一个区块的记录可能会少一些。
倍增分段方案的实际区块数量在½N 到 N 之间,只要加大固定索引区的长度 N 就可以增加实际区块数量。假设我们将 N 扩大到 8,追加数据和倍增过程的原理是一样的,只观察固定索引区就很容易理解,如下图:
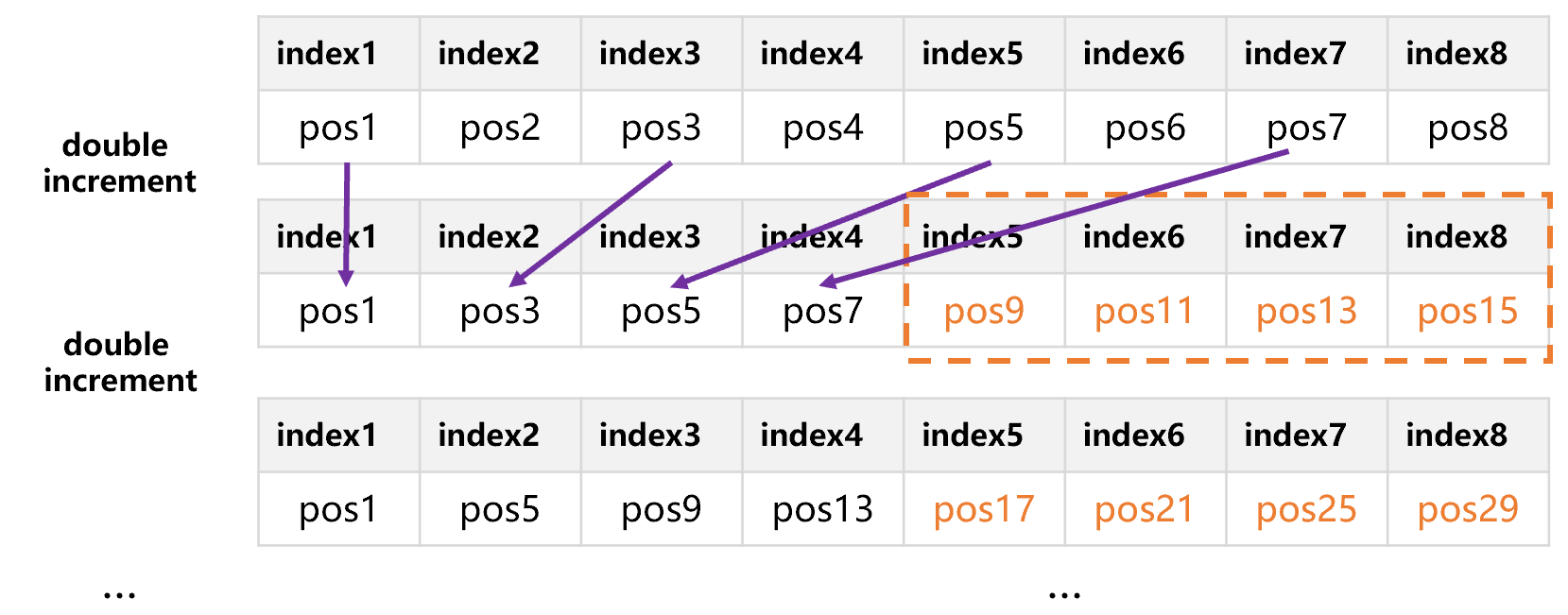
此时,实际区块数量在 4 到 8 之间,最多支持 4 到 8 个并行。根据主流计算机的 CPU 核数和硬盘并发能力,并行数通常在几个到几十个。我们把 N 设置的大一些,例如 1024、2048、4096 等,就可以随意的将数据分成几段到几十段。但也不能过大,以免索引区占用太多空间。SPL 将 N 设置为 1024,对于主流计算机已经足够了。
这样,实际区块数在 512 到 1024 之间。这些区块大小基本相同,组合成几个到几十个分段,可以做到各线程处理的分段数据量非常平均。又由于同一台机器的不同线程计算能力基本相当,所以最终可以保证各线程计算时间大体相同,有效避免部分线程拖慢整个任务的情况。
倍增分段方案中,区块内数据是连续存储的。用相邻区块组成分段,可以保证每个线程在硬盘上连续读取数据。这样,就可以避免频繁跳跃读取造成硬盘性能大幅降低的情况。
这种方案中,可以不断追加数据并倍增生成索引。对于实际应用中产生的新增数据,只要在文件的末尾继续写入数据、照样倍增即可。由于索引区是固定长度,倍增时对索引区的修改不会影响已经形成的数据,不需要耗费大量时间去重构整个文件。
前述数据是以记录为单位追加的,属于行式存储。倍增分段以记录数为基础,还特别适合列式存储。列存本质上是将各个记录的相同字段连续存储,使用倍增分段技术时,需要为每个字段都建立各自的固定索引区。数据区写入某个字段值时,将起始位置写到该字段的固定索引区,并按前述方式倍增。所有字段的索引区同步填入和倍增,始终保持一致。这样可以确保各个字段同步分段,即分段起始处的字段总是属于同一条记录。常规的列存则很难做到以记录数为基础分段,一般会先分块再在块内实现列存,要求分块数很多(适应并行)且分块很大(适应列存),只适合数据量特别大的场景。
SPL 的组表实现了倍增分段方案,可以根据场景采用列存或者行存,代码大致是这样的:
file("T-c.ctx").create(…).append(cs)
// 建立列存组表,并将来自游标 cs 的数据写入组表。
file("T-r.ctx").create@r(…).append(cs)
// 建立行存组表,并将来自游标 cs 的数据写入组表。
对组表做并行计算的代码也很简单,以多线程并行计算分组汇总为例:
=file("T-r.ctx").open().cursor@m().groups(f1,f2,f3,…;sum(amt1),avg(amt2),max(amt3+amt4),…)
// 很多列参与计算或总列数不多时用行存。
=file("T-c.ctx").open().cursor@m(f1,amt1).groups(f1;sum(amt1))
// 总列数很多,参与计算的列数很少时用列存。


英文版