


报表工具怎样使用 txt/csv/xls 的数据
报表工具一般都支持txt/csv/xls等文件数据源,但因为重展示轻计算的产品特性,一般只能对格式规则的文件进行简单计算,至于复杂些的计算任务或格式不够规则的文件,就只能另寻他法了。容易想到的办法是自定义数据集+第三方文件处理类库。文件处理类库的种类不少,但通常解析能力强而计算能力弱,要辅以大量硬编码才能完成计算任务。还有一种办法是通过CSVJDBC/XLSJDBC等驱动在文件上直接执行SQL,好处是集成方便,学习门槛低,缺点是解析能力差且计算能力弱,缺乏日期函数和字符串函数,也不支持关联计算、集合计算、子查询。
更好的办法是用JAVA开源计算类库SPL,既有强大的计算能力,又能解析格式不规则的文件,还有易于被报表工具集成的JDBC接口。
SPL提供了语法简洁的解析函数。统一使用T函数,就可以解析各类格式的规则文件:
T("d:/Orders.csv") //分隔符为逗号,首行为列名
T("d:/Employees.txt) //分隔符为tab,首行为列名
T("d:/data.xls") //行式xls/xlsx,首行为列名
SPL内置丰富的计算函数,可以用简单直观的语法计算文件数据,从而避免繁琐的硬编码。比如对订单进行区间查询,其中p_start、p_end是参数:
A |
|
1 |
=T("d:/Orders.csv") |
2 |
=A1.select(Amount>p_start && Amount<=p_end) |
3 |
return A2 |
SPL提供了JDBC驱动,可以像RDB一样被报表工具集成。对于上面的SPL代码,先存为脚本文件intervalQuery.splx,再在报表工具里调用脚本文件,类似调用存储过程。以Birt报表为例,应写作:
{call intervalQuery(? , ?)}
再举几例:
A |
B |
|
1 |
… |
|
2 |
=A1.select(Amount>1000 && like(Client,\"*S*\")) |
//模糊查询 |
3 |
=A1.sort(Client,-Amount)" |
//排序 |
4 |
=A1 .id(Client) |
//去重 |
5 |
=A1.groups(year(OrderDate);sum(Amount)) |
//分组汇总 |
6 |
=join(A1:O,SellerId; T("D:/Employees.txt"):E,EId) |
/关联 |
对于格式不太规则的文件,SPL也能轻松搞定:
解析csv文件,分隔符是特殊的双横线:
= file("D:/Orders.txt").import@t(;,"--").select(Amount>1000 && Amount<=3000)
文件每三行对应一条记录,其中第二行含多个字段,将该文件整理成规范的二维表,并按第3和第4个字段排序:
A |
|
1 |
=file("D:\\data.txt").import@si() |
2 |
=A1.group((#-1)\3) |
3 |
=A2.new(~(1):OrderID, (line=~(2).array("\t"))(1):Client,line(2):SellerId,line(3):Amount,~(3):OrderDate ) |
4 |
=A3.sort(_3,_4) |
不规则的xls也没问题,一些常见的例子:
//没有列名,首行直接是数据:
=file("D:/Orders.xlsx").xlsimport()
//跳过前2行的标题区:
=file("D:/Orders.xlsx").xlsimport@t(;,3)
//从第3行读到第10行:
=file("D:/Orders.xlsx").xlsimport@t(;,3:10)
//只读取其中3个列:
=file("D:/Orders.xlsx").xlsimport@t(OrderID,Amount,OrderDate)
//读取名为"sheet3"的特定sheet:
=file("D:/Orders.xlsx").xlsimport@t(;"sheet3")
函数xlsimport还具有读取倒数N行、密码打开文件、读大文件等功能,这里不再详述。
SPL还支持标准SQL语法,包括丰富的字符串函数和日期函数,支持关联计算、集合计算、子查询。比如同样的区间查询,可以在报表工具中建立SQL数据集,使用如下SQL语句:
$select * from d:/Orders.csv where Amount>? and Amount<=?
再比如关联:
$select e.name, s.orderdate, s.amount from sales.xls s left join employee.csv e on s.sellerid= e.eid
更多例子参考《在文件上使用 SQL 查询的示例》
SPL计算能力强大,可简化分步计算、有序计算、分组后计算等逻辑较复杂的计算,很多SQL难以实现的计算,用SPL解决起来就很轻松。比如,找出销售额累计占到一半的前n个大客户,并按销售额从大到小排序:
A |
B |
|
1 |
… |
/取数据 |
2 |
=A1.sort(amount:-1) |
/销售额逆序排序 |
3 |
=A2.cumulate(amount) |
/计算累计序列 |
4 |
=A3.m(-1)/2 |
/最后的累计即总额 |
5 |
=A3.pselect(~>=A4) |
/超过一半的位置 |
6 |
=A2(to(A5)) |
/按位置取值 |
再比如,下面的Excel每8行对应一条记录,字段有规律地分散在不同的单元格中,请循环读取每条记录,组织成规范的二维表。
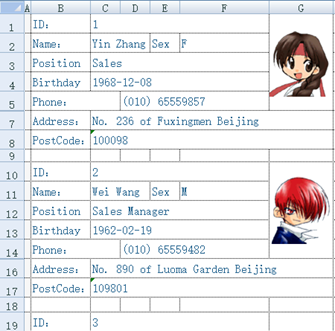
这是个较复杂的多步骤计算问题,还涉及循环控制和有序计算,对POI等类库而言是个繁琐的大工程,而SPL代码就简短得多:
A |
B |
C |
|
1 |
=create(ID,Name,Sex,Position,Birthday,Phone,Address,PostCode) |
||
2 |
=file(“e:/excel/employe.xlsx").xlsopen() |
||
3 |
[C,C,F,C,C,D,C,C] |
[1,2,2,3,4,5,7,8] |
|
4 |
For |
=A3.(~/B3(#)).(A2.xlscell(~)) |
|
5 |
if len(B4(1))==0 |
Break |
|
6 |
>A1.record(B4) |
||
7 |
>B3=B3.(~+9) |
||
SPL提供了专业的IDE,具备完整的调试功能,可以以表格的形式观察每一步的计算结果,适合开发逻辑较复杂的计算。
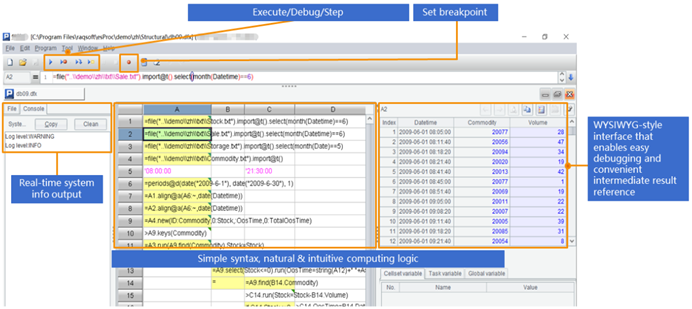
除了txt/csv/xls之外,SPL还支持WebService、Restful、MongoDB、Hadoop、redis、ElasticSearch、SalesForce、Cassandra等多种数据源,以及不同数据源/数据库之间的混合计算。


英文版