


SQL 提速:有关联维表的高并发查询
问题描述
在SQL 提速:高并发帐户查询(下面简称前文)中讨论过单表高并发查询方案。有时情况复杂,查询还会涉及关联运算。比如:帐户查询时,明细数据还要与网点表等维表做关联计算,最终结果中要包含维表的字段,例如网点名称、地址、电话等。数据结构如下图:
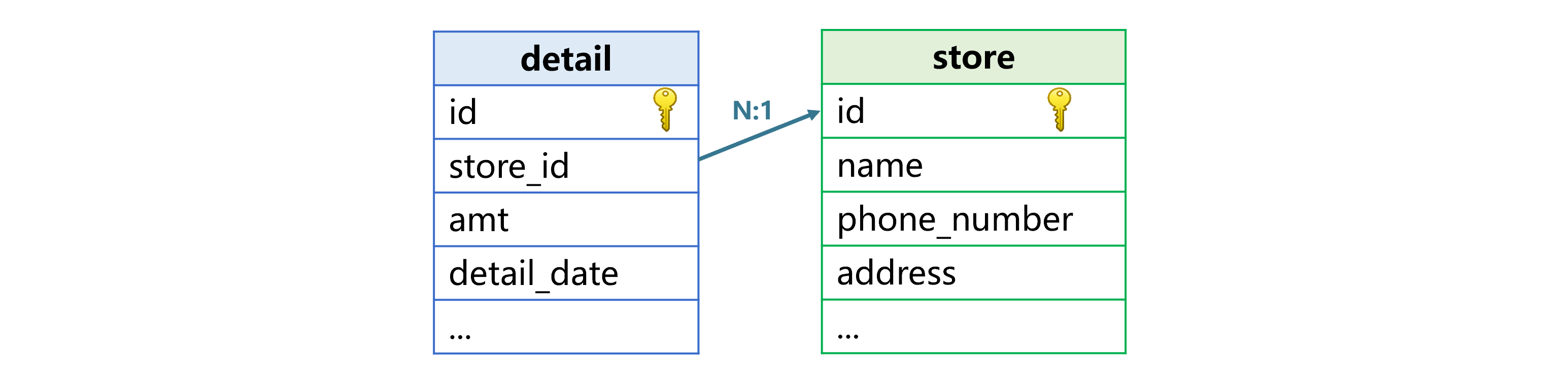
SQL 语句写出来大概是这个样子:
select d.id,d.amt,d.detail_date,s.name,s.phone_number,s.address,… from detail d
left join store s on d.store_id=s.id
where d.id='1010087'
and d.detail_date>= to_date('2021-01-10', 'yyyy-MM-dd')
and d.detail_date<to_date('2021-01-25', 'yyyy-MM-dd')
and …
为了提高查询响应速度,一般都会对 detail 表的帐号 id 字段建索引如下:
create index index_detail_1 on detail(id)
提速方案
一、快速查找,内存关联
通常,这些用作代码的维表都很小,可以全部预读入到内存中并建立好索引。然后使用前文所述的方案,快速查找满足条件的明细数据后,再与这些内存维表做关联运算。因为维表已经建好索引,而且读出来的明细数据量也很小,关联的性能损失基本可以忽略不计,即使有多个关联维表也仍然会非常快,可以满足秒级响应要求。
二、新增数据
按前文的方案即可。
代码示例
一、数据预处理,有序行存、建立索引
参见前文。
二、索引预加载、维表预加载
在系统初始化或者索引、维表发生变动时,要加载到内存中,每次查询计算的时候可以节省加载时间。
A |
B |
|
1 |
if !ifv(detail) |
=file("detail.ctx").open().index@3(index_id) |
2 |
=env(detail,B1) |
|
3 |
if !ifv(store) |
=file("store.btx").import@b(id,name,...).keys(id) |
4 |
=env(store,B3) |
A1:判断全局变量 detail 是否存在,如果存在,表示已经加载了索引。
B1:如果全局变量 detail 不存在,那么打开组表加载三级索引。@2 或者 @3 表示加载 2 或者 3 级索引。3 级索引性能更好,但需要更大的内存。具体加载 2 级还是 3 级,需要根据索引的大小和内存的容量确定。
B2:全局变量 detail 赋值为 B1。
A3-B4:预加载网点维表,带索引的主键是网点编号 id。
三、帐户查询、关联计算
因为预先加载了带索引的明细表和维表,所以查询代码非常简单:
A |
|
1 |
=detail.icursor(;id==1010087 && detail_date>=date("2021-01-10") && detail_date<date("2021-01-25") && …,index_id).fetch() |
2 |
=A1.switch(store_id,store) |
3 |
return A3.new(id,store_id.store_id:store_id,store_id.store_name:store_name,…,amt,detail_date,…) |
A1:icursor 是带索引的游标。实际应用中,帐户 id、时间段等条件,要通过参数传入。
A2:读入内存中的明细数据,和网点维表做关联计算。
A3:引用关联字段,返回查询结果。
四、新增数据
代码参见前文。


英文版