


SPL:访问 HDFS
Hadoop分布式文件系统(HDFS)提供了Java API读写其文件,集算器把实现读写HDFS文件的JAVA代码做了封装,形成更易用的SPL函数。通过这些函数,直接把HDFS文件数据加载到集算器中进行计算。本文详细介绍这些函数的用法。
Java API方式连接HDFS
创建/关闭HDFS连接
使用方式类似数据库连接,SPL也用成对的“创建/关闭”方式连接HDFS。
创建HDFS连接
hdfs_open(url, user),url是HDFS服务器的地址,user指定操作用户,缺省时默认为 "root"。
示例:
A |
|
1 |
=hdfs_open("hdfs://192.168.0.8:9000", "root") |
关闭HDFS连接
hdfs_close(hdfsConn),hdfsConn是要被关闭的HDFS连接。
示例:A1创建连接,中间做一些读写、计算操作后,A3关闭A1创建的连接
A |
|
1 |
=hdfs_open("hdfs://192.168.0.8:9000", "root") |
2 |
…… |
3 |
=hdfs_close(A1) |
目录、文件操作
获取文件列表/创建目录/删除目录
hdfs_dir(hdfsConn, parent),hdfsConn是HDFS连接,parent是要操作的父目录。
示例:用不同的选项表示不同的操作。A2中用@d选项,获得/user/root下的目录列表;A3中用@p选项,获得/user/root下的目录、文件完整路径列表;A4中用@m选项,在/user/root目录下创建子目录imageFolder;A5中用@r选项,删除imageFolder:
A |
|
1 |
=hdfs_open("hdfs://192.168.0.8:9000", "root") |
2 |
=hdfs_dir@d(A1,"/user/root") |
3 |
=hdfs_dir@p(A1,"/user/root") |
4 |
=hdfs_dir@m(A1,"imageFolder") |
5 |
=hdfs_dir@r(A1,"imageFolder") |
6 |
=hdfs_close(A1) |
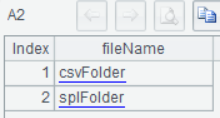
A2列出两个目录:
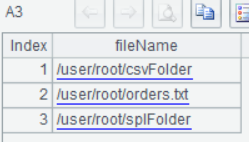
A3除了列出两个目录,还列出来一个orders.txt文件:
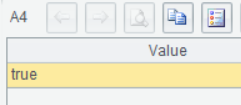
A4、A5执行成功后返回true:
上传到HDFS
hdfs_upload(hdfsConn, localFile, remoteFile),hdfsConn是HDFS连接,localFile是本地文件,remoteFile是上传到HDFS的目标文件。
示例:A3中增加@d选项时,localFile、remoteFile都是文件夹,会上传整个文件夹下的文件。
A |
|
1 |
=hdfs_open("hdfs://192.168.0.8:9000", "root") |
2 |
=hdfs_upload(A1,"D:/employees.xlsx","/user/root/splFolder/employees.xlsx") |
3 |
=hdfs_upload@d(A1,"D:/txtFolder/","/user/root/txtFolder/") |
4 |
=hdfs_close(A1) |
下载HDFS文件
hdfs_download(hdfsConn, remoteFile, localFile),hdfsConn是HDFS连接,remoteFile是HDFS中要下载的文件,localFile是下载到本地的目标文件。
示例:和上传类似,也有@d选项下载整个文件夹。
A |
|
1 |
=hdfs_open("hdfs://192.168.0.8:9000", "root") |
2 |
=hdfs_download(A1,"/user/root/splFolder/employees.xlsx","D:/employees.xlsx") |
3 |
=hdfs_download@d(A1,"/user/root/txtFolder/","D:/txtFolder/") |
4 |
=hdfs_close(A1) |
判断文件是否存在
hdfs_exists(hdfsConn, hdfsFile),hdfsConn是HDFS连接,hdfsFile是要判断的HDFS文件或文件夹。
示例:
A |
|
1 |
=hdfs_open("hdfs://192.168.0.8:9000", "root") |
2 |
=hdfs_exists(A1,"/user/") |
3 |
=hdfs_exists(A1,"/user/root/city.xlsx") |
4 |
=hdfs_close(A1) |
读写文件数据
上传下载HDFS文件,是和本地文件的交互过程,但有些场景下,需要把数据直接读取到内存中进行计算,或把内存中持续不断产生的数据直接保存到HDFS中,而不用通过本地文件中转(可能因为文件太大不能存本地,或中转导致太慢)。SPL提供了hdfs_file函数,支持用游标方式读取文件的一小段,一边读取一边计算,或一边计算一边把结果数据追加写入HDFS文件。
常见的数据文件格式有文本(txt/csv/json/xml)、Excel,除此之外,SPL还提供了高性能的二进制格式的集文件(btx)。
打开HDFS文件
hdfs_file(hdfsConn, hdfsFile:cs),hdfsConn是HDFS连接,hdfsFile是文件,如果是文本格式,用cs指定文本字符集(UTF-8,GBK等等)。
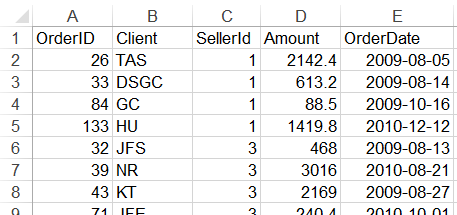
orders表的数据用orders.txt、orders.xlsx、orders.btx三种文件格式存储,下面测试对它们的读写。
A |
|
1 |
=hdfs_open("hdfs://192.168.0.8:9000", "root") |
2 |
=hdfs_file(A1,"/user/root/orders.txt":"UTF-8") |
3 |
=A2.read() |
4 |
=A2.import@t() |
5 |
=A2.cursor@t().fetch(2) |
6 |
=A2.export@t(T) |
7 |
=hdfs_file(A1,"/user/root/orders.xlsx") |
8 |
=A7.xlsimport@t() |
9 |
=A7.xlsexport@t(T) |
10 |
=hdfs_file(A1,"/user/root/orders.btx") |
11 |
=A10.import@b() |
12 |
=A10.cursor@b().skip(10).fetch(5) |
13 |
=A10.write@b(T) |
14 |
=hdfs_close(A1) |
A2打开HDSF文件orders.txt;
A3把整体orders.txt读成一个大字符串:
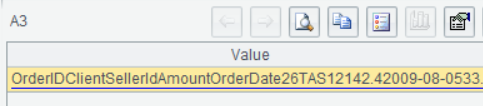
A4把orders.txt加载成序表(第一行是字段名,行内数据用TAB分割):
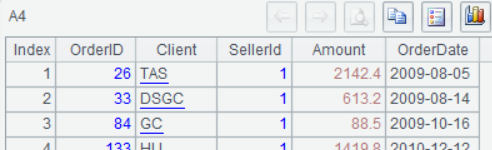
A5用游标方式加载orders.txt前两行数据,这适合处理超大量数据,边加载边计算:
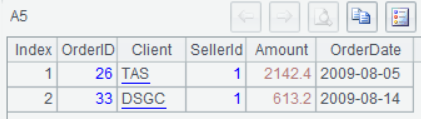
A6把内存中的数据序表T写入orders.txt。
A7打开Excel文件orders.xlsx,A8把其数据读入序表,A9把序表T写回orders.xlsx。
A10打开集文件orders.btx,A11读入数据,A12用游标方式读入,跳过前10条记录,读取第11~15条。A13把序表T写回orders.btx。
WEBHDFS方式连接HDFS
以上函数都是通过HDFS的JAVA API实现,需要在SPL环境中引入相应版本的Hadoop jar及配置文件。为了避免部署麻烦,Hadoop还提供了HTTP REST API方式的WEBHDFS。SPL基于这种方式也实现了两个函数:用webhdfs_file()实现文件数据的读写;剩余的所有操作(如上传下载任意文件、获取HDFS目录及文件列表、改变文件的访问权限、获取HDFS文件存储策略等等),都通过调用webhdfs()函数实现。
读写文件数据
webhdfs_file(fileUrl, params),fileUrl为目标文件的url,params为url中的参数。
下面还以orders的不同类型数据文件为例:
A |
|
1 |
|
2 |
=webhdfs_file("http://localhost:50070/webhdfs/v1/user/root/orders.txt":"UTF-8","user.name=root") |
3 |
=A2.read() |
4 |
=A2.import@t() |
5 |
=A2.cursor@t().fetch(2) |
6 |
=A2.export@t(T) |
7 |
=webhdfs_file("http://localhost:50070/webhdfs/v1/user/root/orders.xlsx","user.name=root") |
8 |
=A7.xlsimport@t() |
9 |
=A7.xlsexport@t(T) |
10 |
=webhdfs_file("http://localhost:50070/webhdfs/v1/user/root/orders.btx","user.name=root") |
11 |
=A10.import@b() |
12 |
=A10.cursor@b().skip(10).fetch(5) |
13 |
=A10.write@b(T) |
14 |
|
webhdfs由于采用http请求,不需要长链接了,也就免去了A1、A14中的open/close动作。
对各种数据文件支持的操作,和之前的hdfs_file是一致的,对文本支持整体读、整体写、游标读、追加写;但由于集文件追加数据时需要随机写,但HDFS的Java API不支持随机写,那也就不支持集文件的追加写了。
这两个读取文件数据的函数功能一样,但各有优缺点,hdfs_file()需要部署特定版本的Hadoop环境,集成麻烦,但性能较好;webhdfs_file()使用简便,兼容不同的HDFS版本,但性能会稍慢。
通用功能函数
webhdfs(url, localFile),url是《HDFS WEBHDFS》中的任意操作;假如是上传文件的操作,localFile是待上传的本地文件;假如是下载文件的操作,localFile下载到本地的目标文件;其它操作时,不需要localFile参数,省略它即可。
示例
A |
|
1 |
=webhdfs("http://localhost:50070/webhdfs/v1/user/root/f1.zip ?op=CREATE&user.name=root","d:/f1.zip") |
2 |
=webhdfs("http://localhost:50070/webhdfs/v1/user/root/f2.png ?op=CREATE&user.name=root&overwrite=true","d:/f2.png") |
3 |
=webhdfs("http://localhost:50070/webhdfs/v1/user/root/f3.txt ?op=APPEND&user.name=root","d:/f3_part5.txt") |
4 |
=webhdfs("http://localhost:50070/webhdfs/v1/user/root/f4.xlsx ?op=OPEN&user.name=root","d:/f4.xlsx") |
5 |
=webhdfs("http://localhost:50070/webhdfs/v1/user/root/?op=LISTSTATUS&user.name=root") |
6 |
=json(A5) |
7 |
=A6.FileStatuses.FileStatus |
8 |
=webhdfs("http://localhost:50070/webhdfs/v1/user/root/orders.txt ?op=SETOWNER&owner=user1&group=grp2") |
A1上传f1.zip;
A2上传f2.png,参数中有overwrite=true,文件已经存在时,会强制替换;
A3上传f3_part5.txt,追加到f3.txt里;
A4下载f4.xlsx,这个通用函数可以上下载任意文件,包括txt、xlsx这类数据文件;
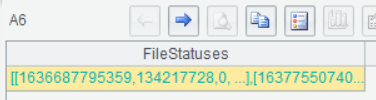
A5获得/user/root/目录下的文件列表, WEBHDFS所有的操作,要么不返回内容,要么返回一个JSON格式的结果:
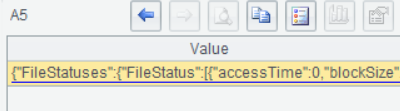
A6把A5返回的JSON串转成嵌套的多层序表:
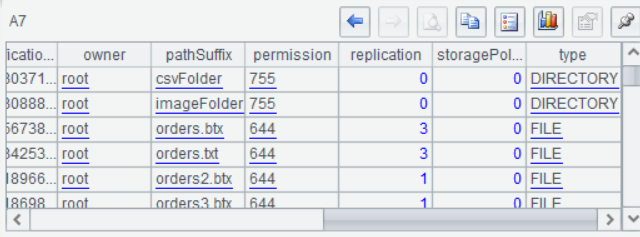
A7从A6中取出需要的那一层序表,能看到文件列表的详细内容:
A8设置HDFS文件的拥有者,更多操作就不一一展示。


英文版