筛选指定特征的曲线段二——筛选曲线段
筛选指定特征的曲线段二——筛选曲线段
算法背景
算法背景已经在《筛选指定特征的曲线段一——计算曲线特征》中介绍过了,这里不再赘述。
文章链接:
算法思路
接《筛选指定特征的曲线段一——计算曲线特征》的算法思路,本篇介绍筛选曲线时的思路。
1. 投射特征
计算特征时,各个特征的量纲并不相同,在筛选这些特征时,不容易设置他们的取值范围。因此想办法把特征投射到一个统一的范围内。(比如投射到[-1,1],因为有些特征的正负是有意义的,如升降特征,正的表示上升,负的表示下降)。设置参数时只要设置[-1,1]范围内的数即可,-1表示最小,1表示最大。
2. 连续多特征曲线段
投射特征后可以方便的设置参数筛选出某种特征的曲线段,如上升或震荡发散等,但想选出连续不同特征的曲线段(如先上升后下降、先平稳后下降等)时会比较复杂。
(1) 将几种特征曲线段全筛选出来;
(2) 按序排列这些曲线段;
(3) 选出顺序正确且距离不远的曲线段即可。
算法过程
1. 投射特征
具有正负取值的特征(如升降指数):
假设特征的最大值是fmax,最小值是fmin。将[fmin,0]投射到[-1,0],[0,fmax]投射到[0,1],特征f与筛选参数a的函数关系为:
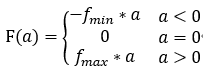
取值只有正数的特征:
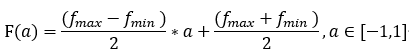
特征被投射到[-1,1]后,参数就更容易设置了。
2. 筛选特征
(1) 设置筛选参数
筛选曲线段的特征组合称为指数特征名,记为index_name。
index_name =[f1,f2,…,fm]
其中fi是第i个特征指数名。
特征组合对应的取值范围称为指数取值参数,记为index_arg。
index_arg=[[a(1)1, a(1)2], [a(2)1, a(2)2],…, [a(m)1, a(m)2]]
其中a(i)1是第i个特征指数的取值下限,a(i)2是第i个特征指数的取值上限,。
(2) 投射参数
将指数取值参数投射到指数的取值上,称为指数取值,记为index_value。
index_value=[[ v(1)1, v(1)2], [[v(2)1, v(2)2],…, [[v(m)1, v(m)2]]
其中F(…)是投射函数,v(i)1= F(a(i)1),v(i)2= F(a(i)2)。
(3) 记录满足条件的特征索引feature_idx。
feature_idx=[i, v(1)1≤f(1)≤v(1)2,…, v(m)1≤f(m)≤v(m)2,i∈[1,m]]
其中f(i)是第i个指数的取值。
(4) 筛选曲线段长度
将曲线段长度范围记为duration
duration=[d1,d2]
feature_idx中每段数值连续的索引都是一段满足条件的曲线段,筛选出曲线段的持续时间在duration内的段,也就是找出连续索引的个数在[d1,d2]范围内的曲线段。
3. 分段曲线
当要筛选多种不同特征曲线时(如下降——平稳——上升…),按如下步骤进行:
(1) 按筛选特征的方法筛选出各种特征的曲线索引。
curve_idx1=H(arg1)
curve_idx2=H(arg2)
…
curve_idxk=H(argk)
其中curve_idxi是第i段特征曲线的索引集合,H(…)是2中介绍的筛选特征曲线段函数,argi是第i段特征曲线的参数。
(2) 合并这些曲线段并按照曲线段的先后顺序排序。
curve_id=curve_idx1|curve_idx2|curve_idxk
curve_id_sort=[c1,c2,…,ch]
其中curve_id_sort是按曲线段的先后顺序排序后的曲线段集合,ci是curve_id_sort的第i个元素,表示某个特征曲线的某一段,h是各种特征曲线的曲线段数量之和。
(3) 找出curve_id_sort中与所需特征顺序相同且间隔不远的连续曲线段。
seg_curve_id=[[ci,ci+1,…,ci+k-1],[ cj,cj+1,…,cj+k-1],…]
其中seg_curve_id是分段曲线的索引集合,其中ci,ci+1,…,ci+k-1分别属于curve_idx1, curve_idx2,…,curve_idxk,且相邻两段曲线相隔不远。
(4) 按索引取数
seg_curve=X(seg_curve_id)
其中X是时间序列。
写出代码
A |
B |
C |
D |
||
1 |
=json(args) |
/筛选参数 |
|||
2 |
=X |
/时间序列 |
|||
3 |
=T |
/时间 |
|||
4 |
=func(A37,A1.ob_level) |
/主线参数 k |
|||
5 |
=A1.ob_level\20 |
/指数区间 |
|||
6 |
=fit_main(A2,A4) |
/主线 |
|||
7 |
=clac_feature(A6,A5,"lift") |
/升降指数 |
|||
8 |
=clac_feature(A6,A5,"lift_speed") |
/升降速度指数 |
|||
9 |
=A2--A6 |
/波动曲线 |
|||
10 |
=clac_feature(A9,A5,"range") |
/振幅 |
|||
11 |
=fit_main(A10,A4) |
/振幅主线 |
|||
12 |
=clac_feature(A11,A5,"lift") |
/振幅升降指数 |
|||
13 |
=clac_feature(A9,A5,"fre") |
/振频 |
|||
14 |
=fit_main(A13,A4) |
/振频主线 |
|||
15 |
=clac_feature(A14,A5,"lift") |
/振频升降指数 |
|||
16 |
[time,value,main,lift,lift_speed,range,range_lift,frequency,frequency_lift] |
||||
17 |
=create(${A16.concat@c()}) |
/建立特征序表 |
|||
18 |
=[A3,A2,A6,A7,A8,A10,A12,A13,A15] |
||||
19 |
=transpose(A18).conj() |
||||
20 |
=A17.record(A19) |
||||
21 |
=func(A42,A20) |
/特征最大最小值 |
|||
22 |
for A1 |
=A22.index_name_seq |
/指数名称 |
||
23 |
=A22.index_value_seq |
/指数参数值 |
|||
24 |
=A21.align(B22,feature) |
/需要的指数 |
|||
25 |
=B23.((idx=#,if(B24(idx).feature=="value",~,~.(func(A52,~,B24(idx).ma,B24(idx).mi))))) |
/指数实际值 |
|||
26 |
=B22.(~/">="/"number("/$[B25(]/#/$[)(1)]/")"/"&&"/~/"<="/"number("/$[B25(]/#/$[)(2)]/")").concat("&&") |
/筛选表达式 |
|||
27 |
=A20.pselect@a(eval(B26)) |
/曲线段索引 |
|||
28 |
=B27.group@u(~-#) |
/连续索引段 |
|||
29 |
=A22.duration |
/持续时间 |
|||
30 |
=if(!B29,B28,B28.select(~.len()>=B29(1)&&~.len()<=B29(2))) |
/按持续时间筛选 |
|||
31 |
=@|[B30] |
||||
32 |
=func(A60,B31,A1.(space)) |
/分段筛选 |
|||
33 |
=A32.(A20(~)) |
/按索引取数 |
|||
34 |
=if(A33.len()<1,"No satisfactory working condition was found",A33.new(#:index,~.(time):time,~.(value):value)) |
/返回结果 |
|||
35 |
return A34 |
||||
36 |
/计算移动窗口与拟合参数 k 的关系,参数:移动窗口 |
||||
37 |
func |
||||
38 |
=A37/15 |
||||
39 |
=lg(B38,2) |
||||
40 |
=2*power(4,B39-1) |
||||
41 |
/计算特征最大最小值,参数:特征序表 |
||||
42 |
func |
||||
43 |
=A42.fname() |
/特征名 |
|||
44 |
=create(feature,ma,mi) |
||||
45 |
for B43 |
=A42.(${B45}) |
|||
46 |
=C45.max() |
/最大值 |
|||
47 |
=C45.min() |
/最小值 |
|||
48 |
=[B45,C46,C47] |
||||
49 |
=B44.record(C48) |
||||
50 |
return B44 |
||||
51 |
/投射特征,参数:[-1,1] 范围内的数,最大值,最小值 |
||||
52 |
func |
||||
53 |
if B52*C52<0 |
if A52<=0 |
=(A52+1)*(-C52)+C52 |
||
54 |
return D53 |
||||
55 |
else |
=A52*B52 |
|||
56 |
return D55 |
||||
57 |
else if B52*C52>=0 |
=(A52*(B52-C52)+B52+C52)/2 |
|||
58 |
return C57 |
||||
59 |
/归并分段,参数:序列的序列 |
||||
60 |
func |
||||
61 |
=A60.conj((idx=#,~.new(~:seq,idx:seq_idx))) |
/不同特征的曲线段索引 |
|||
62 |
=B61.sort(seq) |
/排序 |
|||
63 |
=B62.group@u(seq_idx-#) |
/特征相邻的分组 |
|||
64 |
=if(A60.len()==1,B63,B63.select(~.len()==A60.len()&&(~.(~.seq.m(1)-~[-1].seq.m(-1)).m(2:)--B60.m(:-2)).id(~<=0)==[true])) |
/筛选间隔足够小的分组 |
|||
65 |
=B64.((sq=~.(seq).conj(),to(sq.~,sq.m(-1)))) |
/满足要求的曲线段 |
|||
参数说明:
args:是筛选曲线段的参数,是个json串。形式如下:
[{"ob_level":600,
"index_name_seq":["lift"],
"index_value_seq":[[-1,-0.1]],
"duration":[100,1000],
"space":180},
{"ob_level":600,
"index_name_seq":["lift"],
"index_value_seq":[[-0.1,0.1]],
"duration":[100,1000],
"space":180}]
ob_level:观察级别,用于计算拟合主线的参数k,可以理解为移动均线的移动窗口。
index_name_seq:指数特征名,值是字符串构成的序列,如:[“lift”]。
index_value_seq:指数参数值,值是数字构成的序列的序列,如:[[-1,-0.1]]。
duration:曲线段长度范围,值是数字构成的序列,可以为空,如:[100,1000]。
space:与下一种工况的间隔,当筛选分段工况时,该参数才有用,如:180。
说明:代码是简单的实现代码,每次都会计算所有特征,在实际应用时只需要计算参数中设置的特征即可,也可以把计算特征模块单独出来,将特征存储下来,这样筛选时就会快很多。
应用举例
时间序列X
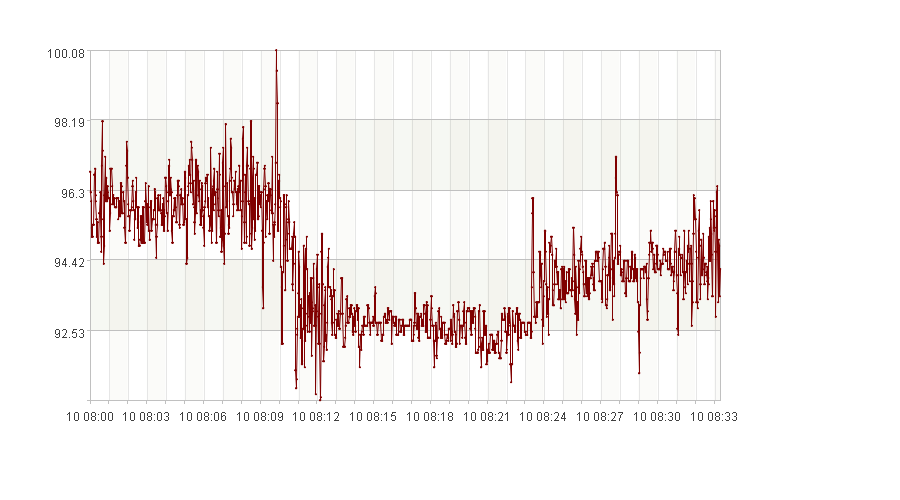
图中横轴是时间(dd hh:mm),纵轴是序列中的值。
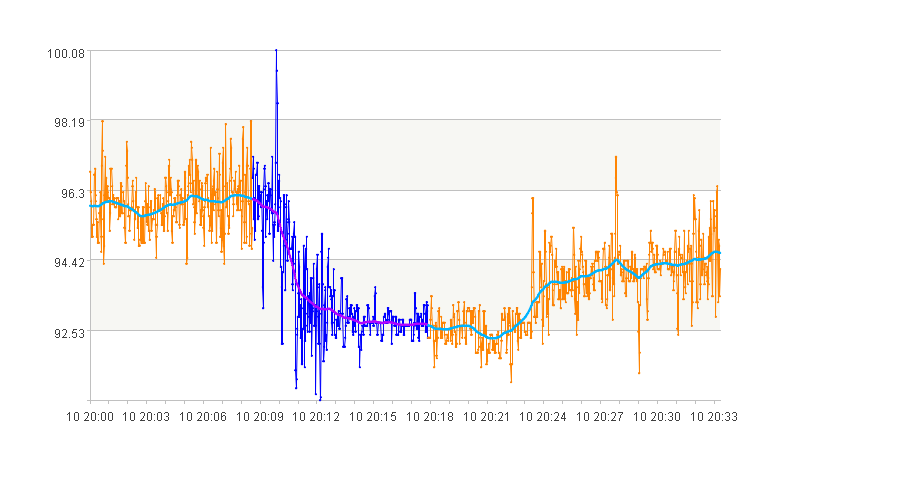
1. 取值在[90,95]之间的曲线段
args:
[{"ob_level":600,
"index_name_seq":["value"],
"index_value_seq":[[90,95]],
"duration":[100,10000],
"space":180}]
筛选结果:
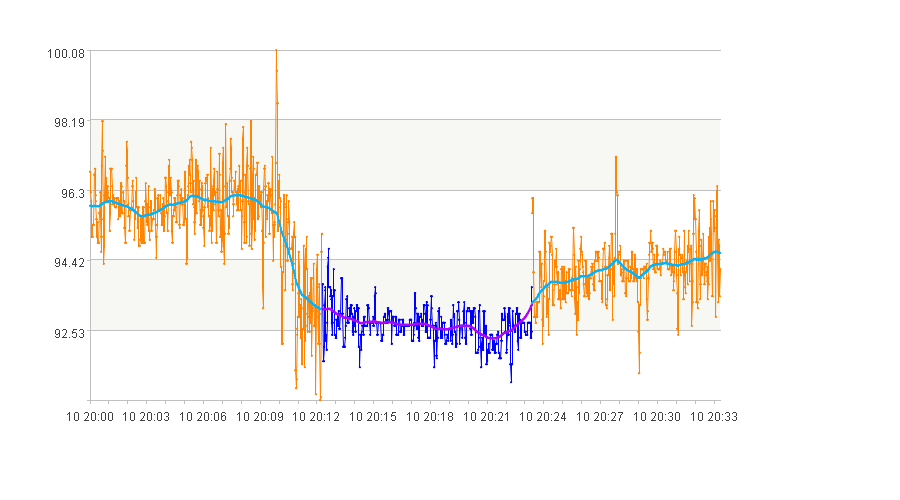
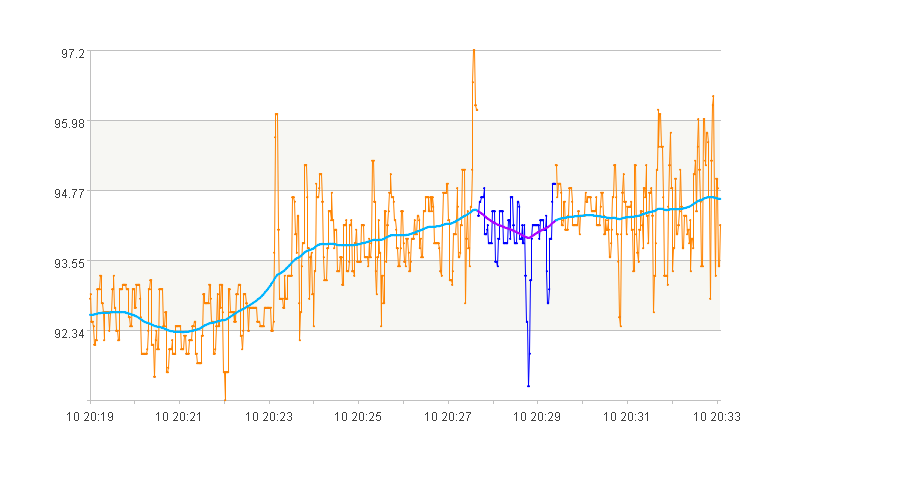
图中蓝色的曲线段为筛选到曲线段。
2. 上升的曲线段
args:
[{"ob_level":600,
"index_name_seq":["lift"],
"index_value_seq":[[0.1,1]],
"duration":[100,10000],
"space":180}]
筛选结果:
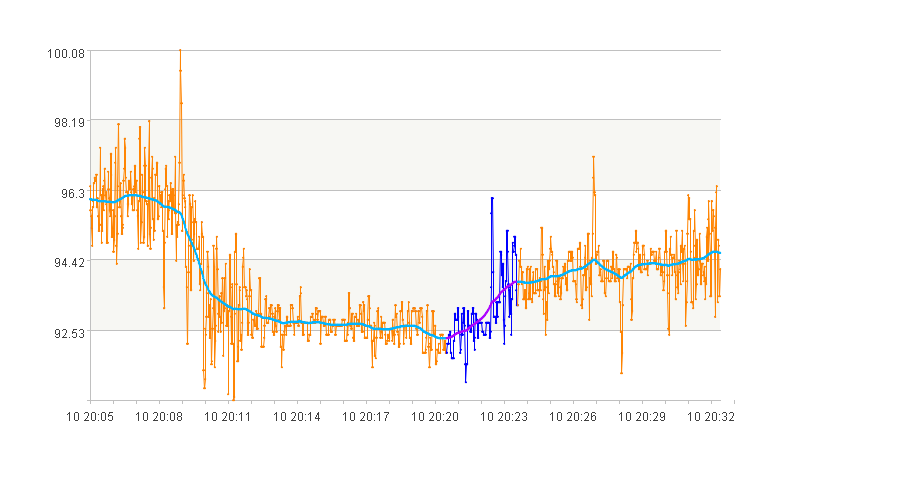
3. 振频很高的曲线段
args:
[{"ob_level":600,
"index_name_seq":["frequency"],
"index_value_seq":[[0,1]],
"duration":[100,10000],
"space":180}]
筛选结果:
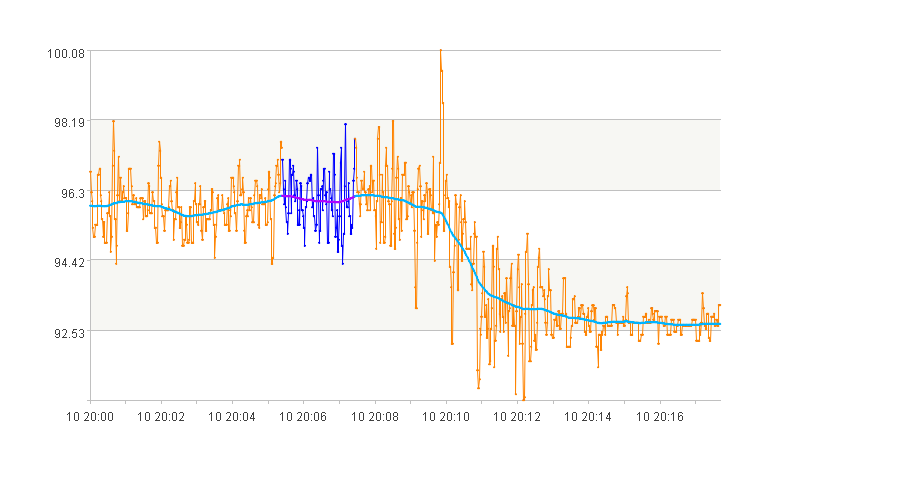
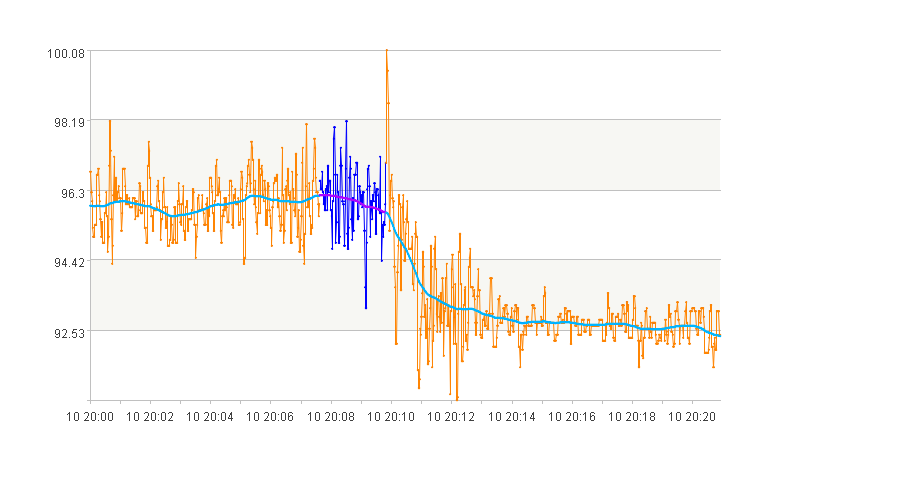
4. 震荡发散的曲线段
args:
[{"ob_level":600,
"index_name_seq":["range_lift","frequency_lift"],
"index_value_seq":[[0,1],[-0.5,1]],
"duration":[100,3000],
"space":180}]
筛选结果:
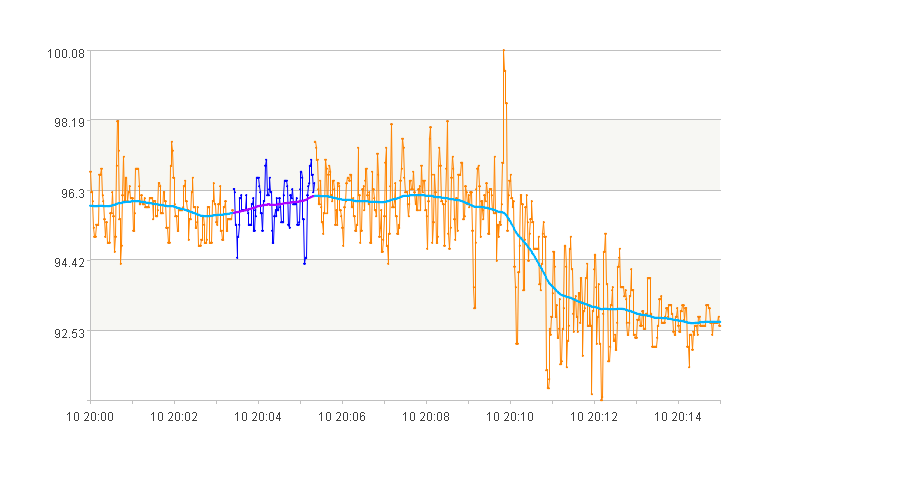
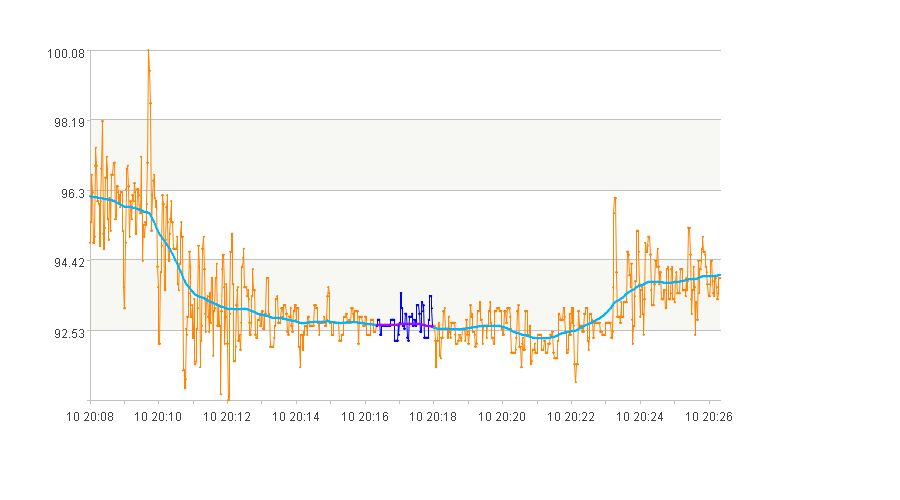
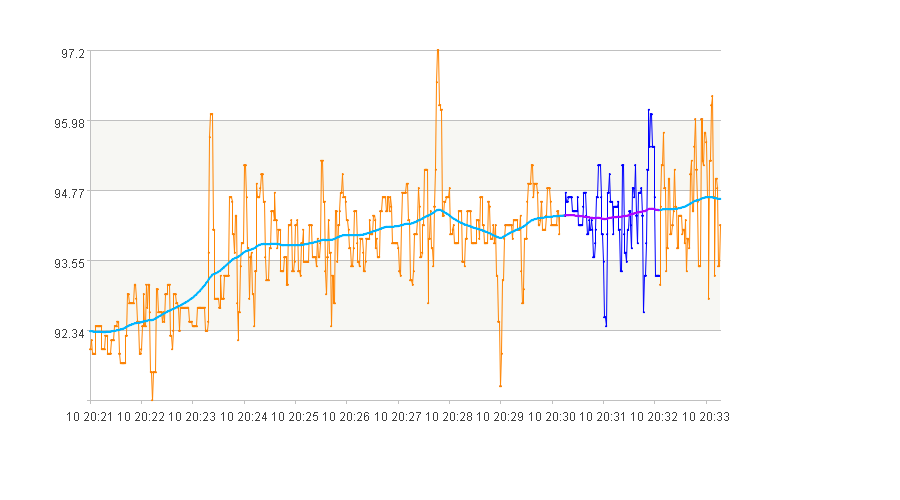
5. 先下降后平稳的曲线段
args:
[{"ob_level":600,
"index_name_seq":["lift"],
"index_value_seq":[[-1,-0.1]],
"duration":[100,1000],
"space":180},
{"ob_level":600,
"index_name_seq":["lift"],
"index_value_seq":[[-0.1,0.1]],
"duration":[100,1000],
"space":180}]