


Java 中怎样解析和计算 XML?
方法一,用JAVA代码将XML字符串存入数据库,再用SQL计算XML,这样做的好处是利用了SQL的计算能力,缺点是SQL是基于二维结构化记录的,不擅长多层XML的计算,而且入库过程繁琐,性能非常差。方法二,先用XOM\Xerces-J\Jdom\Dom4J等JAVA类库解析XML,再用Xpath语法计算,好处是直接高效,缺点是Xpath只支持条件查询和聚合,除此之外的计算都要硬编码。
方法三,用开源JAVA类库SPL直接解析和计算XML。SPL的数据对象专为多层结构而设计,可以大幅简化多层XML的计算,SPL的函数和语法具有强大的计算能力,可以显著简化复杂的计算逻辑。
SPL提供了方便的JDBC接口,使用者可以轻松上手。例如,某XML文件有两层,每个字段是员工记录,员工记录的每个字段是订单记录,将该文件解析为SPL的序表数据对象:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
String str="=xml(file(\"D:/data.xml\").read(),\"xml/row\")";
ResultSet result = statement.executeQuery(str);
…
SPL序表天然就是多层数据结构,特别适合计算多层XML,可以明显减低代码难度。比如,对所有员工的所有订单进行条件查询,找到金额属于某区间,且客户名称包含某字符串的订单:
=xml(file("D:/data.xml").read(),"xml/row").conj(Orders).select((Amount>1000 && Amount<=2000) && like@c(Client,"*business*"))
SPL代码可外置于JAVA代码,修改时无须编译,可降低计算代码和JAVA代码的耦合性。比如上面的条件查询可先存为SPL脚本文件:
A |
|
1 |
=xml(file("d:/data.xml").read(),"xml/row") |
2 |
=A1.conj(Orders) |
3 |
=A2.select(Amount>100 && Amount<=3000 && like@c(Client,"*bro*")) |
再在JAVA中调用时,只需以存储过程的形式引用脚本文件名:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
String str="call condition()";
ResultSet result = statement.executeQuery(str);
…
SPL内置丰富的库函数,提供了等价于SQL的计算能力,下面试举几例:
A |
||
2 |
…. |
|
3 |
=A2.conj(Orders).groups(Client;sum(Amount)) |
分组汇总 |
4 |
=A2.groups(State,Gender;avg(Salary),count(1)) |
多字段分组汇总 |
5 |
=A2.sort(Salary) |
排序 |
6 |
=A2.id(State) |
去重 |
7 |
=A2.new(Name,Gender,Dept,Orders.OrderID,Orders.Client,Orders.Client,Orders.SellerId,Orders.Amount,Orders.OrderDate) |
关联 |
有些运算逻辑比较复杂,用SQL或存储过程也很难实现,而SPL具有丰富的函数和灵活的语法,可以大幅简化复杂运算逻辑。比如:计算某支股票最长的连续上涨天数,SPL只需两行:
A |
|
1 |
=xml(file("d:/share.xml").read(),"xml/row") |
2 |
=a=0,A1.max(a=if(price>price[-1],a+1,0)) |
SPL支持Http/WebServic取XML,接口简单易懂。比如从WebService取股票信息的接口描述,再根据接口描述查询某支股票的收盘价,最后计算连长天数:
A |
|
1 |
=ws_client("http://.../shareWebService.asmx?wsdl") |
2 |
=ws_call(A1,"shareWebService":"shareWebServiceSoap":"AAPL") |
3 |
=a=0,A1.max(a=if(price>price[-1],a+1,0)) |
对于计算逻辑较复杂的运算,SPL提供了专用的IDE,不仅有完整的调试,还能用表格的形式观察每一步的中间计算结果:
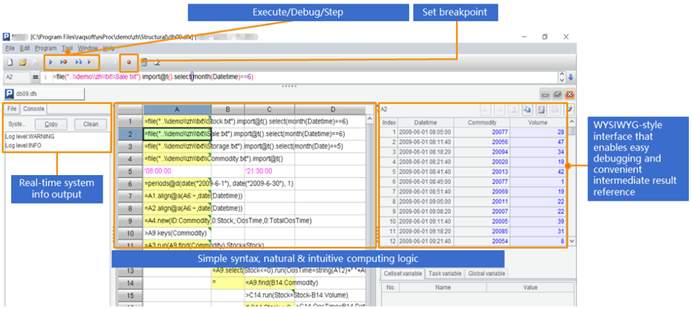
SPL计算能力非常强,经常可以简化多层XML的计算。比如文件book1.xml存储多个图书信息,每本书有多个作者,部分数据如下:
|
将这个XML整理成结构化二维表,其中作者字段以特殊格式呈现,结果应当如下:
title |
Category |
year |
Author |
info |
Everyday Italian |
COOKING |
2005 |
Giada De Laurentiis[it] |
Hello Italian! |
Harry Potter |
CHILDREN |
2005 |
J K. Rowling[uk] |
Hello Potter! |
XQuery Kick Start |
WEB |
2005 |
James McGovern[us],Per Bothner[us] |
Hello XQuery |
源XML和整理后的二维表都很复杂,处理难度较大,但用SPL就简单多了:
A |
|
1 |
=file("D:\\xml\\book1.xml") |
2 |
=xml@s(A1.read(),"library/book").library |
3 |
=A2.new(category,book.field("year").ifn():year,book.field("title").ifn():title,book.field("lang").ifn():lang,book.field("info").ifn():info,book.field("name").select(~).concat@c():name,book.field("country").select(~).concat(","):country) |
4 |
=A3.new(title,category,year,(lang,name.array().(~+"[")++country.array().(~+"]")).concat@c():author,info) |
5 |
=A4.select(year==2005) |
使用SPL,无须入库便可直接解析来自文件和webService的XML,可以大幅简化多层XML的计算,可以显著简化复杂的运算逻辑。

