


报表工具如何支持大数据?
随着业务增长报表查询的数据量越来越大,数据库容量和性能都会遭遇瓶颈。数据库本身体系比较封闭,执行效率也不够高,即使扩容也不能很好地解决大数据查询的性能问题,并且很容易达到扩容上限。不仅如此,数据库扩容成本高昂,用于解决大数据报表查询往往性价比不高。
比较可行的手段是使用开放、灵活的数据计算平台。MPP 数据库本质上还是数据库,数据库的问题仍然存在;Hadoop 虽然相对开放,但使用成本过高且查询效率往往并不理想。
集算器 SPL 可以很好解决大数据场景下的报表查询问题。
集算器是一款开源的数据计算平台,开放性和高性能是其主要特点。集算器内置了大量面向大数据的高性能计算函数,可以很方便地完成大数据计算任务。还提供了高性能存储方案,将数据存储成集算器私有的 BTX 或 CTX 格式再使用可以获得更高的运算性能。
此外,集算器还支持并行计算,单机多线程并行和多机多线程并行均可。集算器支持水平扩容,当遇到性能瓶颈时可以通过增加节点的方式获得接近线性的性能提升。
不仅如此,SPL 语法除了性能更高,也很简洁。根据月度销售额表查询每次第一个月比上季同月的增长额,及销售情况(有些月可能无数据)。SPL 写法:
A |
|
1 |
=db.query(“select * from sales”).align@1([1,4,7,10],smonth) |
2 |
=A1.new(#:month,amount,amount-amount[-1]:growth) |
集算器还支持多种数据源(RDB、NoSQL、Json、CSV、Webservice 等),可以实现跨数据源的混合计算。开放的计算体系不强迫数据“入库”,当然使用集算器自有的高性能存储查询效率更高。
在与报表工具结合方面,集算器可以作为嵌入式 JDBC 与报表工具集成使用,报表工具通过 JDBC 方式访问 SPL 计算结果,就像访问数据库一样。SPL 是解释执行的,支持热切换,脚本修改无需重启服务,可以很好适应多变的报表场景。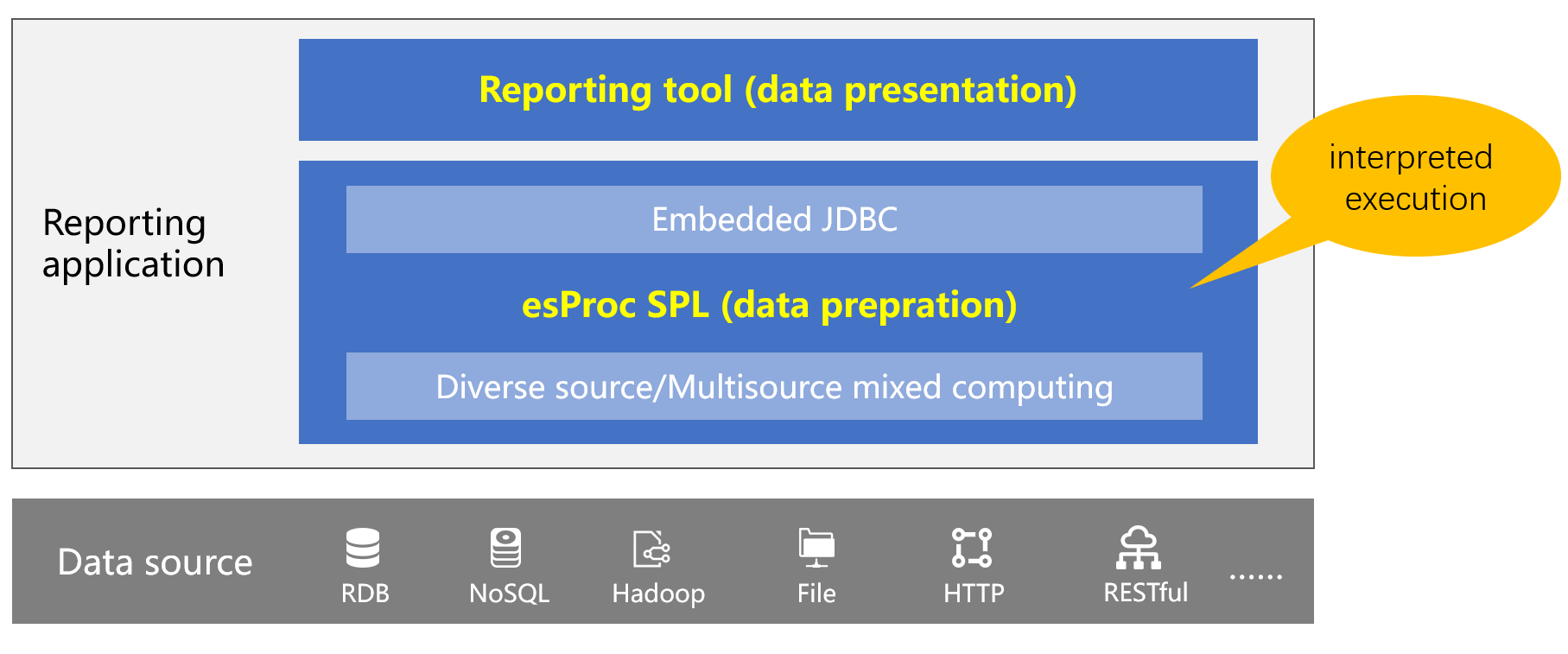
在润乾报表中还基于集算器开发出“大报表”的功能,直接支持大数据报表查询,无论数据源是数据库还是文件系统都可以使用。大报表采用两个异步线程分别进行取数和呈现,这样就可以避免传统数据库分页方案翻页效率差、还可能出错的问题,而且效率更高。

